mirror of
https://github.com/mendableai/firecrawl.git
synced 2024-11-16 11:42:24 +08:00
Merge branch 'main' into feat/actions
This commit is contained in:
commit
0690cfeaad
5
.vscode/settings.json
vendored
Normal file
5
.vscode/settings.json
vendored
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
{
|
||||||
|
"rust-analyzer.linkedProjects": [
|
||||||
|
"apps/rust-sdk/Cargo.toml"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -103,7 +103,7 @@ This should return the response Hello, world!
|
||||||
If you’d like to test the crawl endpoint, you can run this
|
If you’d like to test the crawl endpoint, you can run this
|
||||||
|
|
||||||
```curl
|
```curl
|
||||||
curl -X POST http://localhost:3002/v0/crawl \
|
curl -X POST http://localhost:3002/v1/crawl \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://mendable.ai"
|
||||||
|
|
|
||||||
30
README.md
30
README.md
|
|
@ -34,9 +34,9 @@
|
||||||
|
|
||||||
# 🔥 Firecrawl
|
# 🔥 Firecrawl
|
||||||
|
|
||||||
Crawl and convert any website into LLM-ready markdown or structured data. Built by [Mendable.ai](https://mendable.ai?ref=gfirecrawl) and the Firecrawl community. Includes powerful scraping, crawling and data extraction capabilities.
|
Empower your AI apps with clean data from any website. Featuring advanced scraping, crawling, and data extraction capabilities.
|
||||||
|
|
||||||
_This repository is in its early development stages. We are still merging custom modules in the mono repo. It's not completely yet ready for full self-host deployment, but you can already run it locally._
|
_This repository is in development, and we’re still integrating custom modules into the mono repo. It's not fully ready for self-hosted deployment yet, but you can run it locally._
|
||||||
|
|
||||||
## What is Firecrawl?
|
## What is Firecrawl?
|
||||||
|
|
||||||
|
|
@ -52,9 +52,12 @@ _Pst. hey, you, join our stargazers :)_
|
||||||
|
|
||||||
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
||||||
|
|
||||||
- [x] [API](https://firecrawl.dev/playground)
|
Check out the following resources to get started:
|
||||||
- [x] [Python SDK](https://github.com/mendableai/firecrawl/tree/main/apps/python-sdk)
|
- [x] [API](https://docs.firecrawl.dev/api-reference/introduction)
|
||||||
- [x] [Node SDK](https://github.com/mendableai/firecrawl/tree/main/apps/js-sdk)
|
- [x] [Python SDK](https://docs.firecrawl.dev/sdks/python)
|
||||||
|
- [x] [Node SDK](https://docs.firecrawl.dev/sdks/node)
|
||||||
|
- [x] [Go SDK](https://docs.firecrawl.dev/sdks/go)
|
||||||
|
- [x] [Rust SDK](https://docs.firecrawl.dev/sdks/rust)
|
||||||
- [x] [Langchain Integration 🦜🔗](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/)
|
- [x] [Langchain Integration 🦜🔗](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/)
|
||||||
- [x] [Langchain JS Integration 🦜🔗](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl)
|
- [x] [Langchain JS Integration 🦜🔗](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl)
|
||||||
- [x] [Llama Index Integration 🦙](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader)
|
- [x] [Llama Index Integration 🦙](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader)
|
||||||
|
|
@ -62,8 +65,12 @@ We provide an easy to use API with our hosted version. You can find the playgrou
|
||||||
- [x] [Langflow Integration](https://docs.langflow.org/)
|
- [x] [Langflow Integration](https://docs.langflow.org/)
|
||||||
- [x] [Crew.ai Integration](https://docs.crewai.com/)
|
- [x] [Crew.ai Integration](https://docs.crewai.com/)
|
||||||
- [x] [Flowise AI Integration](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl)
|
- [x] [Flowise AI Integration](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl)
|
||||||
|
- [x] [Composio Integration](https://composio.dev/tools/firecrawl/all)
|
||||||
- [x] [PraisonAI Integration](https://docs.praison.ai/firecrawl/)
|
- [x] [PraisonAI Integration](https://docs.praison.ai/firecrawl/)
|
||||||
- [x] [Zapier Integration](https://zapier.com/apps/firecrawl/integrations)
|
- [x] [Zapier Integration](https://zapier.com/apps/firecrawl/integrations)
|
||||||
|
- [x] [Cargo Integration](https://docs.getcargo.io/integration/firecrawl)
|
||||||
|
- [x] [Pipedream Integration](https://pipedream.com/apps/firecrawl/)
|
||||||
|
- [x] [Pabbly Connect Integration](https://www.pabbly.com/connect/integrations/firecrawl/)
|
||||||
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
||||||
|
|
||||||
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md).
|
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md).
|
||||||
|
|
@ -487,9 +494,20 @@ const scrapeResult = await app.scrapeUrl("https://news.ycombinator.com", {
|
||||||
console.log(scrapeResult.data["llm_extraction"]);
|
console.log(scrapeResult.data["llm_extraction"]);
|
||||||
```
|
```
|
||||||
|
|
||||||
|
## Open Source vs Cloud Offering
|
||||||
|
|
||||||
|
Firecrawl is open source available under the AGPL-3.0 license.
|
||||||
|
|
||||||
|
To deliver the best possible product, we offer a hosted version of Firecrawl alongside our open-source offering. The cloud solution allows us to continuously innovate and maintain a high-quality, sustainable service for all users.
|
||||||
|
|
||||||
|
Firecrawl Cloud is available at [firecrawl.dev](https://firecrawl.dev) and offers a range of features that are not available in the open source version:
|
||||||
|
|
||||||
|
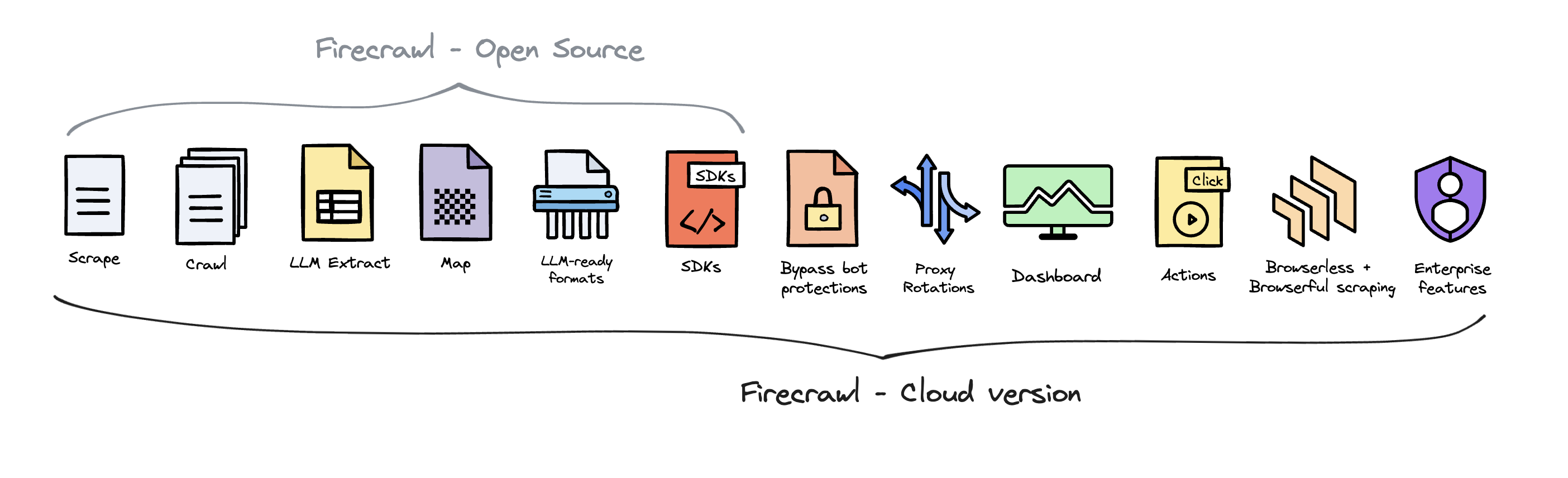
|
||||||
|
|
||||||
|
|
||||||
## Contributing
|
## Contributing
|
||||||
|
|
||||||
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request.
|
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request. If you'd like to self-host, refer to the [self-hosting guide](SELF_HOST.md).
|
||||||
|
|
||||||
_It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions._
|
_It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions._
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -176,4 +176,4 @@ By addressing these common issues, you can ensure a smoother setup and operation
|
||||||
|
|
||||||
## Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
## Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
||||||
|
|
||||||
Read the [examples/kubernetes-cluster-install/README.md](https://github.com/mendableai/firecrawl/blob/main/examples/kubernetes-cluster-install/README.md) for instructions on how to install Firecrawl on a Kubernetes Cluster.
|
Read the [examples/kubernetes/cluster-install/README.md](https://github.com/mendableai/firecrawl/blob/main/examples/kubernetes/cluster-install/README.md) for instructions on how to install Firecrawl on a Kubernetes Cluster.
|
||||||
|
|
@ -19,8 +19,15 @@ import { billTeam } from "../../services/billing/credit_billing";
|
||||||
import { logJob } from "../../services/logging/log_job";
|
import { logJob } from "../../services/logging/log_job";
|
||||||
import { performCosineSimilarity } from "../../lib/map-cosine";
|
import { performCosineSimilarity } from "../../lib/map-cosine";
|
||||||
import { Logger } from "../../lib/logger";
|
import { Logger } from "../../lib/logger";
|
||||||
|
import Redis from "ioredis";
|
||||||
|
|
||||||
configDotenv();
|
configDotenv();
|
||||||
|
const redis = new Redis(process.env.REDIS_URL);
|
||||||
|
|
||||||
|
// Max Links that /map can return
|
||||||
|
const MAX_MAP_LIMIT = 5000;
|
||||||
|
// Max Links that "Smart /map" can return
|
||||||
|
const MAX_FIRE_ENGINE_RESULTS = 1000;
|
||||||
|
|
||||||
export async function mapController(
|
export async function mapController(
|
||||||
req: RequestWithAuth<{}, MapResponse, MapRequest>,
|
req: RequestWithAuth<{}, MapResponse, MapRequest>,
|
||||||
|
|
@ -30,8 +37,7 @@ export async function mapController(
|
||||||
|
|
||||||
req.body = mapRequestSchema.parse(req.body);
|
req.body = mapRequestSchema.parse(req.body);
|
||||||
|
|
||||||
|
const limit: number = req.body.limit ?? MAX_MAP_LIMIT;
|
||||||
const limit : number = req.body.limit ?? 5000;
|
|
||||||
|
|
||||||
const id = uuidv4();
|
const id = uuidv4();
|
||||||
let links: string[] = [req.body.url];
|
let links: string[] = [req.body.url];
|
||||||
|
|
@ -47,24 +53,61 @@ export async function mapController(
|
||||||
|
|
||||||
const crawler = crawlToCrawler(id, sc);
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
const sitemap = req.body.ignoreSitemap ? null : await crawler.tryGetSitemap();
|
|
||||||
|
|
||||||
if (sitemap !== null) {
|
|
||||||
sitemap.map((x) => {
|
|
||||||
links.push(x.url);
|
|
||||||
});
|
|
||||||
}
|
|
||||||
|
|
||||||
let urlWithoutWww = req.body.url.replace("www.", "");
|
let urlWithoutWww = req.body.url.replace("www.", "");
|
||||||
|
|
||||||
let mapUrl = req.body.search
|
let mapUrl = req.body.search
|
||||||
? `"${req.body.search}" site:${urlWithoutWww}`
|
? `"${req.body.search}" site:${urlWithoutWww}`
|
||||||
: `site:${req.body.url}`;
|
: `site:${req.body.url}`;
|
||||||
// www. seems to exclude subdomains in some cases
|
|
||||||
const mapResults = await fireEngineMap(mapUrl, {
|
const resultsPerPage = 100;
|
||||||
// limit to 100 results (beta)
|
const maxPages = Math.ceil(Math.min(MAX_FIRE_ENGINE_RESULTS, limit) / resultsPerPage);
|
||||||
numResults: Math.min(limit, 100),
|
|
||||||
});
|
const cacheKey = `fireEngineMap:${mapUrl}`;
|
||||||
|
const cachedResult = await redis.get(cacheKey);
|
||||||
|
|
||||||
|
let allResults: any[];
|
||||||
|
let pagePromises: Promise<any>[];
|
||||||
|
|
||||||
|
if (cachedResult) {
|
||||||
|
allResults = JSON.parse(cachedResult);
|
||||||
|
} else {
|
||||||
|
const fetchPage = async (page: number) => {
|
||||||
|
return fireEngineMap(mapUrl, {
|
||||||
|
numResults: resultsPerPage,
|
||||||
|
page: page,
|
||||||
|
});
|
||||||
|
};
|
||||||
|
|
||||||
|
pagePromises = Array.from({ length: maxPages }, (_, i) => fetchPage(i + 1));
|
||||||
|
allResults = await Promise.all(pagePromises);
|
||||||
|
|
||||||
|
await redis.set(cacheKey, JSON.stringify(allResults), "EX", 24 * 60 * 60); // Cache for 24 hours
|
||||||
|
}
|
||||||
|
|
||||||
|
// Parallelize sitemap fetch with serper search
|
||||||
|
const [sitemap, ...searchResults] = await Promise.all([
|
||||||
|
req.body.ignoreSitemap ? null : crawler.tryGetSitemap(),
|
||||||
|
...(cachedResult ? [] : pagePromises),
|
||||||
|
]);
|
||||||
|
|
||||||
|
if (!cachedResult) {
|
||||||
|
allResults = searchResults;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sitemap !== null) {
|
||||||
|
sitemap.forEach((x) => {
|
||||||
|
links.push(x.url);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
let mapResults = allResults
|
||||||
|
.flat()
|
||||||
|
.filter((result) => result !== null && result !== undefined);
|
||||||
|
|
||||||
|
const minumumCutoff = Math.min(MAX_MAP_LIMIT, limit);
|
||||||
|
if (mapResults.length > minumumCutoff) {
|
||||||
|
mapResults = mapResults.slice(0, minumumCutoff);
|
||||||
|
}
|
||||||
|
|
||||||
if (mapResults.length > 0) {
|
if (mapResults.length > 0) {
|
||||||
if (req.body.search) {
|
if (req.body.search) {
|
||||||
|
|
@ -84,17 +127,19 @@ export async function mapController(
|
||||||
// Perform cosine similarity between the search query and the list of links
|
// Perform cosine similarity between the search query and the list of links
|
||||||
if (req.body.search) {
|
if (req.body.search) {
|
||||||
const searchQuery = req.body.search.toLowerCase();
|
const searchQuery = req.body.search.toLowerCase();
|
||||||
|
|
||||||
links = performCosineSimilarity(links, searchQuery);
|
links = performCosineSimilarity(links, searchQuery);
|
||||||
}
|
}
|
||||||
|
|
||||||
links = links.map((x) => {
|
links = links
|
||||||
try {
|
.map((x) => {
|
||||||
return checkAndUpdateURLForMap(x).url.trim()
|
try {
|
||||||
} catch (_) {
|
return checkAndUpdateURLForMap(x).url.trim();
|
||||||
return null;
|
} catch (_) {
|
||||||
}
|
return null;
|
||||||
}).filter(x => x !== null);
|
}
|
||||||
|
})
|
||||||
|
.filter((x) => x !== null);
|
||||||
|
|
||||||
// allows for subdomains to be included
|
// allows for subdomains to be included
|
||||||
links = links.filter((x) => isSameDomain(x, req.body.url));
|
links = links.filter((x) => isSameDomain(x, req.body.url));
|
||||||
|
|
@ -107,8 +152,10 @@ export async function mapController(
|
||||||
// remove duplicates that could be due to http/https or www
|
// remove duplicates that could be due to http/https or www
|
||||||
links = removeDuplicateUrls(links);
|
links = removeDuplicateUrls(links);
|
||||||
|
|
||||||
billTeam(req.auth.team_id, 1).catch(error => {
|
billTeam(req.auth.team_id, 1).catch((error) => {
|
||||||
Logger.error(`Failed to bill team ${req.auth.team_id} for 1 credit: ${error}`);
|
Logger.error(
|
||||||
|
`Failed to bill team ${req.auth.team_id} for 1 credit: ${error}`
|
||||||
|
);
|
||||||
// Optionally, you could notify an admin or add to a retry queue here
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
});
|
});
|
||||||
|
|
||||||
|
|
@ -116,7 +163,7 @@ export async function mapController(
|
||||||
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
|
|
||||||
const linksToReturn = links.slice(0, limit);
|
const linksToReturn = links.slice(0, limit);
|
||||||
|
|
||||||
logJob({
|
logJob({
|
||||||
job_id: id,
|
job_id: id,
|
||||||
success: links.length > 0,
|
success: links.length > 0,
|
||||||
|
|
@ -140,3 +187,51 @@ export async function mapController(
|
||||||
scrape_id: req.body.origin?.includes("website") ? id : undefined,
|
scrape_id: req.body.origin?.includes("website") ? id : undefined,
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Subdomain sitemap url checking
|
||||||
|
|
||||||
|
// // For each result, check for subdomains, get their sitemaps and add them to the links
|
||||||
|
// const processedUrls = new Set();
|
||||||
|
// const processedSubdomains = new Set();
|
||||||
|
|
||||||
|
// for (const result of links) {
|
||||||
|
// let url;
|
||||||
|
// let hostParts;
|
||||||
|
// try {
|
||||||
|
// url = new URL(result);
|
||||||
|
// hostParts = url.hostname.split('.');
|
||||||
|
// } catch (e) {
|
||||||
|
// continue;
|
||||||
|
// }
|
||||||
|
|
||||||
|
// console.log("hostParts", hostParts);
|
||||||
|
// // Check if it's a subdomain (more than 2 parts, and not 'www')
|
||||||
|
// if (hostParts.length > 2 && hostParts[0] !== 'www') {
|
||||||
|
// const subdomain = hostParts[0];
|
||||||
|
// console.log("subdomain", subdomain);
|
||||||
|
// const subdomainUrl = `${url.protocol}//${subdomain}.${hostParts.slice(-2).join('.')}`;
|
||||||
|
// console.log("subdomainUrl", subdomainUrl);
|
||||||
|
|
||||||
|
// if (!processedSubdomains.has(subdomainUrl)) {
|
||||||
|
// processedSubdomains.add(subdomainUrl);
|
||||||
|
|
||||||
|
// const subdomainCrawl = crawlToCrawler(id, {
|
||||||
|
// originUrl: subdomainUrl,
|
||||||
|
// crawlerOptions: legacyCrawlerOptions(req.body),
|
||||||
|
// pageOptions: {},
|
||||||
|
// team_id: req.auth.team_id,
|
||||||
|
// createdAt: Date.now(),
|
||||||
|
// plan: req.auth.plan,
|
||||||
|
// });
|
||||||
|
// const subdomainSitemap = await subdomainCrawl.tryGetSitemap();
|
||||||
|
// if (subdomainSitemap) {
|
||||||
|
// subdomainSitemap.forEach((x) => {
|
||||||
|
// if (!processedUrls.has(x.url)) {
|
||||||
|
// processedUrls.add(x.url);
|
||||||
|
// links.push(x.url);
|
||||||
|
// }
|
||||||
|
// });
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
|
|
||||||
|
|
@ -36,17 +36,15 @@ export async function getLinksFromSitemap(
|
||||||
const root = parsed.urlset || parsed.sitemapindex;
|
const root = parsed.urlset || parsed.sitemapindex;
|
||||||
|
|
||||||
if (root && root.sitemap) {
|
if (root && root.sitemap) {
|
||||||
for (const sitemap of root.sitemap) {
|
const sitemapPromises = root.sitemap
|
||||||
if (sitemap.loc && sitemap.loc.length > 0) {
|
.filter(sitemap => sitemap.loc && sitemap.loc.length > 0)
|
||||||
await getLinksFromSitemap({ sitemapUrl: sitemap.loc[0], allUrls, mode });
|
.map(sitemap => getLinksFromSitemap({ sitemapUrl: sitemap.loc[0], allUrls, mode }));
|
||||||
}
|
await Promise.all(sitemapPromises);
|
||||||
}
|
|
||||||
} else if (root && root.url) {
|
} else if (root && root.url) {
|
||||||
for (const url of root.url) {
|
const validUrls = root.url
|
||||||
if (url.loc && url.loc.length > 0 && !WebCrawler.prototype.isFile(url.loc[0])) {
|
.filter(url => url.loc && url.loc.length > 0 && !WebCrawler.prototype.isFile(url.loc[0]))
|
||||||
allUrls.push(url.loc[0]);
|
.map(url => url.loc[0]);
|
||||||
}
|
allUrls.push(...validUrls);
|
||||||
}
|
|
||||||
}
|
}
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
Logger.debug(`Error processing sitemapUrl: ${sitemapUrl} | Error: ${error.message}`);
|
Logger.debug(`Error processing sitemapUrl: ${sitemapUrl} | Error: ${error.message}`);
|
||||||
|
|
|
||||||
|
|
@ -1,10 +1,14 @@
|
||||||
import axios from "axios";
|
import axios from "axios";
|
||||||
import dotenv from "dotenv";
|
import dotenv from "dotenv";
|
||||||
import { SearchResult } from "../../src/lib/entities";
|
import { SearchResult } from "../../src/lib/entities";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { Logger } from "../lib/logger";
|
||||||
|
|
||||||
dotenv.config();
|
dotenv.config();
|
||||||
|
|
||||||
export async function fireEngineMap(q: string, options: {
|
export async function fireEngineMap(
|
||||||
|
q: string,
|
||||||
|
options: {
|
||||||
tbs?: string;
|
tbs?: string;
|
||||||
filter?: string;
|
filter?: string;
|
||||||
lang?: string;
|
lang?: string;
|
||||||
|
|
@ -12,34 +16,43 @@ export async function fireEngineMap(q: string, options: {
|
||||||
location?: string;
|
location?: string;
|
||||||
numResults: number;
|
numResults: number;
|
||||||
page?: number;
|
page?: number;
|
||||||
}): Promise<SearchResult[]> {
|
|
||||||
let data = JSON.stringify({
|
|
||||||
query: q,
|
|
||||||
lang: options.lang,
|
|
||||||
country: options.country,
|
|
||||||
location: options.location,
|
|
||||||
tbs: options.tbs,
|
|
||||||
numResults: options.numResults,
|
|
||||||
page: options.page ?? 1,
|
|
||||||
});
|
|
||||||
|
|
||||||
if (!process.env.FIRE_ENGINE_BETA_URL) {
|
|
||||||
console.warn("(v1/map Beta) Results might differ from cloud offering currently.");
|
|
||||||
return [];
|
|
||||||
}
|
}
|
||||||
|
): Promise<SearchResult[]> {
|
||||||
|
try {
|
||||||
|
let data = JSON.stringify({
|
||||||
|
query: q,
|
||||||
|
lang: options.lang,
|
||||||
|
country: options.country,
|
||||||
|
location: options.location,
|
||||||
|
tbs: options.tbs,
|
||||||
|
numResults: options.numResults,
|
||||||
|
page: options.page ?? 1,
|
||||||
|
});
|
||||||
|
|
||||||
let config = {
|
if (!process.env.FIRE_ENGINE_BETA_URL) {
|
||||||
method: "POST",
|
console.warn(
|
||||||
url: `${process.env.FIRE_ENGINE_BETA_URL}/search`,
|
"(v1/map Beta) Results might differ from cloud offering currently."
|
||||||
headers: {
|
);
|
||||||
"Content-Type": "application/json",
|
return [];
|
||||||
},
|
}
|
||||||
data: data,
|
|
||||||
};
|
let config = {
|
||||||
const response = await axios(config);
|
method: "POST",
|
||||||
if (response && response) {
|
url: `${process.env.FIRE_ENGINE_BETA_URL}/search`,
|
||||||
return response.data
|
headers: {
|
||||||
} else {
|
"Content-Type": "application/json",
|
||||||
|
},
|
||||||
|
data: data,
|
||||||
|
};
|
||||||
|
const response = await axios(config);
|
||||||
|
if (response && response) {
|
||||||
|
return response.data;
|
||||||
|
} else {
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
Sentry.captureException(error);
|
||||||
return [];
|
return [];
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
823
apps/api/v1-openapi.json
Normal file
823
apps/api/v1-openapi.json
Normal file
|
|
@ -0,0 +1,823 @@
|
||||||
|
{
|
||||||
|
"openapi": "3.0.0",
|
||||||
|
"info": {
|
||||||
|
"title": "Firecrawl API",
|
||||||
|
"version": "v1",
|
||||||
|
"description": "API for interacting with Firecrawl services to perform web scraping and crawling tasks.",
|
||||||
|
"contact": {
|
||||||
|
"name": "Firecrawl Support",
|
||||||
|
"url": "https://firecrawl.dev",
|
||||||
|
"email": "support@firecrawl.dev"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"servers": [
|
||||||
|
{
|
||||||
|
"url": "https://api.firecrawl.dev/v1"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"paths": {
|
||||||
|
"/scrape": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Scrape a single URL and optionally extract information using an LLM",
|
||||||
|
"operationId": "scrapeAndExtractFromUrl",
|
||||||
|
"tags": ["Scraping"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The URL to scrape"
|
||||||
|
},
|
||||||
|
"formats": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "html", "rawHtml", "links", "screenshot", "extract", "screenshot@fullPage"]
|
||||||
|
},
|
||||||
|
"description": "Formats to include in the output.",
|
||||||
|
"default": ["markdown"]
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"includeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to include in the output."
|
||||||
|
},
|
||||||
|
"excludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to exclude from the output."
|
||||||
|
},
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Specify a delay in milliseconds before fetching the content, allowing the page sufficient time to load.",
|
||||||
|
"default": 0
|
||||||
|
},
|
||||||
|
"timeout": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Timeout in milliseconds for the request",
|
||||||
|
"default": 30000
|
||||||
|
},
|
||||||
|
"extract": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Extract object",
|
||||||
|
"properties": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "The schema to use for the extraction (Optional)"
|
||||||
|
},
|
||||||
|
"systemPrompt": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The system prompt to use for the extraction (Optional)"
|
||||||
|
},
|
||||||
|
"prompt": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The prompt to use for the extraction without a schema (Optional)"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/ScrapeResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl/{id}": {
|
||||||
|
"parameters": [
|
||||||
|
{
|
||||||
|
"name": "id",
|
||||||
|
"in": "path",
|
||||||
|
"description": "The ID of the crawl job",
|
||||||
|
"required": true,
|
||||||
|
"schema": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uuid"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"get": {
|
||||||
|
"summary": "Get the status of a crawl job",
|
||||||
|
"operationId": "getCrawlStatus",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"delete": {
|
||||||
|
"summary": "Cancel a crawl job",
|
||||||
|
"operationId": "cancelCrawl",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful cancellation",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean",
|
||||||
|
"example": true
|
||||||
|
},
|
||||||
|
"message": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Crawl job successfully cancelled."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"404": {
|
||||||
|
"description": "Crawl job not found",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Crawl job not found."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Crawl multiple URLs based on options",
|
||||||
|
"operationId": "crawlUrls",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The base URL to start crawling from"
|
||||||
|
},
|
||||||
|
"excludePaths": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to exclude"
|
||||||
|
},
|
||||||
|
"includePaths": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to include"
|
||||||
|
},
|
||||||
|
"maxDepth": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum depth to crawl relative to the entered URL.",
|
||||||
|
"default": 2
|
||||||
|
},
|
||||||
|
"ignoreSitemap": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Ignore the website sitemap when crawling",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of pages to crawl",
|
||||||
|
"default": 10
|
||||||
|
},
|
||||||
|
"allowBackwardLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Enables the crawler to navigate from a specific URL to previously linked pages.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"allowExternalLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Allows the crawler to follow links to external websites.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"webhook": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The URL to send the webhook to. This will trigger for crawl started (crawl.started) ,every page crawled (crawl.page) and when the crawl is completed (crawl.completed or crawl.failed). The response will be the same as the `/scrape` endpoint."
|
||||||
|
},
|
||||||
|
"scrapeOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"formats": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "html", "rawHtml", "links", "screenshot"]
|
||||||
|
},
|
||||||
|
"description": "Formats to include in the output.",
|
||||||
|
"default": ["markdown"]
|
||||||
|
},
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"includeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to include in the output."
|
||||||
|
},
|
||||||
|
"excludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags to exclude from the output."
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 123
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/CrawlResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/map": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Map multiple URLs based on options",
|
||||||
|
"operationId": "mapUrls",
|
||||||
|
"tags": ["Mapping"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The base URL to start crawling from"
|
||||||
|
},
|
||||||
|
"search": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "Search query to use for mapping. During the Alpha phase, the 'smart' part of the search functionality is limited to 100 search results. However, if map finds more results, there is no limit applied."
|
||||||
|
},
|
||||||
|
"ignoreSitemap": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Ignore the website sitemap when crawling",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"includeSubdomains": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include subdomains of the website",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of links to return",
|
||||||
|
"default": 5000,
|
||||||
|
"maximum": 5000
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/MapResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"components": {
|
||||||
|
"securitySchemes": {
|
||||||
|
"bearerAuth": {
|
||||||
|
"type": "http",
|
||||||
|
"scheme": "bearer"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"schemas": {
|
||||||
|
"ScrapeResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `html` is in `formats`"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `rawHtml` is in `formats`"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Screenshot of the page if `screenshot` is in `formats`"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "List of links on the page if `links` is in `formats`"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"llm_extraction": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Displayed when using LLM Extraction. Extracted data from the page following the schema defined.",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"warning": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Can be displayed when using LLM Extraction. Warning message will let you know any issues with the extraction."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlStatusResponseObj": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"status": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "The current status of the crawl. Can be `scraping`, `completed`, or `failed`."
|
||||||
|
},
|
||||||
|
"total": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The total number of pages that were attempted to be crawled."
|
||||||
|
},
|
||||||
|
"completed": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The number of pages that have been successfully crawled."
|
||||||
|
},
|
||||||
|
"creditsUsed": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The number of credits used for the crawl."
|
||||||
|
},
|
||||||
|
"expiresAt": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "date-time",
|
||||||
|
"description": "The date and time when the crawl will expire."
|
||||||
|
},
|
||||||
|
"next": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The URL to retrieve the next 10MB of data. Returned if the crawl is not completed or if the response is larger than 10MB."
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "array",
|
||||||
|
"description": "The data of the crawl.",
|
||||||
|
"items": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `includeHtml` is true"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `includeRawHtml` is true"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "List of links on the page if `includeLinks` is true"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Screenshot of the page if `includeScreenshot` is true"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"id": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"MapResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -228,7 +228,7 @@ class FirecrawlApp:
|
||||||
json_data = {'url': url}
|
json_data = {'url': url}
|
||||||
if params:
|
if params:
|
||||||
json_data.update(params)
|
json_data.update(params)
|
||||||
|
|
||||||
# Make the POST request with the prepared headers and JSON data
|
# Make the POST request with the prepared headers and JSON data
|
||||||
response = requests.post(
|
response = requests.post(
|
||||||
f'{self.api_url}{endpoint}',
|
f'{self.api_url}{endpoint}',
|
||||||
|
|
@ -238,7 +238,7 @@ class FirecrawlApp:
|
||||||
if response.status_code == 200:
|
if response.status_code == 200:
|
||||||
response = response.json()
|
response = response.json()
|
||||||
if response['success'] and 'links' in response:
|
if response['success'] and 'links' in response:
|
||||||
return response['links']
|
return response
|
||||||
else:
|
else:
|
||||||
raise Exception(f'Failed to map URL. Error: {response["error"]}')
|
raise Exception(f'Failed to map URL. Error: {response["error"]}')
|
||||||
else:
|
else:
|
||||||
|
|
@ -434,4 +434,4 @@ class CrawlWatcher:
|
||||||
self.dispatch_event('document', doc)
|
self.dispatch_event('document', doc)
|
||||||
elif msg['type'] == 'document':
|
elif msg['type'] == 'document':
|
||||||
self.data.append(msg['data'])
|
self.data.append(msg['data'])
|
||||||
self.dispatch_event('document', msg['data'])
|
self.dispatch_event('document', msg['data'])
|
||||||
|
|
|
||||||
229
apps/rust-sdk/Cargo.lock
generated
229
apps/rust-sdk/Cargo.lock
generated
|
|
@ -26,6 +26,21 @@ dependencies = [
|
||||||
"memchr",
|
"memchr",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "android-tzdata"
|
||||||
|
version = "0.1.1"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "e999941b234f3131b00bc13c22d06e8c5ff726d1b6318ac7eb276997bbb4fef0"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "android_system_properties"
|
||||||
|
version = "0.1.5"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "819e7219dbd41043ac279b19830f2efc897156490d7fd6ea916720117ee66311"
|
||||||
|
dependencies = [
|
||||||
|
"libc",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "arrayref"
|
name = "arrayref"
|
||||||
version = "0.3.7"
|
version = "0.3.7"
|
||||||
|
|
@ -151,6 +166,19 @@ version = "1.0.0"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "baf1de4339761588bc0619e3cbc0120ee582ebb74b53b4efbf79117bd2da40fd"
|
checksum = "baf1de4339761588bc0619e3cbc0120ee582ebb74b53b4efbf79117bd2da40fd"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "chrono"
|
||||||
|
version = "0.4.38"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "a21f936df1771bf62b77f047b726c4625ff2e8aa607c01ec06e5a05bd8463401"
|
||||||
|
dependencies = [
|
||||||
|
"android-tzdata",
|
||||||
|
"iana-time-zone",
|
||||||
|
"num-traits",
|
||||||
|
"serde",
|
||||||
|
"windows-targets 0.52.6",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "clippy"
|
name = "clippy"
|
||||||
version = "0.0.302"
|
version = "0.0.302"
|
||||||
|
|
@ -197,6 +225,51 @@ version = "0.8.20"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "22ec99545bb0ed0ea7bb9b8e1e9122ea386ff8a48c0922e43f36d45ab09e0e80"
|
checksum = "22ec99545bb0ed0ea7bb9b8e1e9122ea386ff8a48c0922e43f36d45ab09e0e80"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "darling"
|
||||||
|
version = "0.20.10"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "6f63b86c8a8826a49b8c21f08a2d07338eec8d900540f8630dc76284be802989"
|
||||||
|
dependencies = [
|
||||||
|
"darling_core",
|
||||||
|
"darling_macro",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "darling_core"
|
||||||
|
version = "0.20.10"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "95133861a8032aaea082871032f5815eb9e98cef03fa916ab4500513994df9e5"
|
||||||
|
dependencies = [
|
||||||
|
"fnv",
|
||||||
|
"ident_case",
|
||||||
|
"proc-macro2",
|
||||||
|
"quote",
|
||||||
|
"strsim",
|
||||||
|
"syn",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "darling_macro"
|
||||||
|
version = "0.20.10"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "d336a2a514f6ccccaa3e09b02d41d35330c07ddf03a62165fcec10bb561c7806"
|
||||||
|
dependencies = [
|
||||||
|
"darling_core",
|
||||||
|
"quote",
|
||||||
|
"syn",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "deranged"
|
||||||
|
version = "0.3.11"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "b42b6fa04a440b495c8b04d0e71b707c585f83cb9cb28cf8cd0d976c315e31b4"
|
||||||
|
dependencies = [
|
||||||
|
"powerfmt",
|
||||||
|
"serde",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "diff"
|
name = "diff"
|
||||||
version = "0.1.13"
|
version = "0.1.13"
|
||||||
|
|
@ -215,10 +288,10 @@ dependencies = [
|
||||||
]
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "dotenv"
|
name = "dotenvy"
|
||||||
version = "0.15.0"
|
version = "0.15.7"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "77c90badedccf4105eca100756a0b1289e191f6fcbdadd3cee1d2f614f97da8f"
|
checksum = "1aaf95b3e5c8f23aa320147307562d361db0ae0d51242340f558153b4eb2439b"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "encoding_rs"
|
name = "encoding_rs"
|
||||||
|
|
@ -276,16 +349,17 @@ checksum = "9fc0510504f03c51ada170672ac806f1f105a88aa97a5281117e1ddc3368e51a"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "firecrawl"
|
name = "firecrawl"
|
||||||
version = "0.1.0"
|
version = "1.0.0"
|
||||||
dependencies = [
|
dependencies = [
|
||||||
"assert_matches",
|
"assert_matches",
|
||||||
"clippy",
|
"clippy",
|
||||||
"dotenv",
|
"dotenvy",
|
||||||
"log 0.4.22",
|
"log 0.4.22",
|
||||||
"reqwest",
|
"reqwest",
|
||||||
"rustfmt",
|
"rustfmt",
|
||||||
"serde",
|
"serde",
|
||||||
"serde_json",
|
"serde_json",
|
||||||
|
"serde_with",
|
||||||
"thiserror",
|
"thiserror",
|
||||||
"tokio",
|
"tokio",
|
||||||
"uuid",
|
"uuid",
|
||||||
|
|
@ -426,13 +500,19 @@ dependencies = [
|
||||||
"futures-core",
|
"futures-core",
|
||||||
"futures-sink",
|
"futures-sink",
|
||||||
"http",
|
"http",
|
||||||
"indexmap",
|
"indexmap 2.2.6",
|
||||||
"slab",
|
"slab",
|
||||||
"tokio",
|
"tokio",
|
||||||
"tokio-util",
|
"tokio-util",
|
||||||
"tracing",
|
"tracing",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "hashbrown"
|
||||||
|
version = "0.12.3"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "8a9ee70c43aaf417c914396645a0fa852624801b24ebb7ae78fe8272889ac888"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "hashbrown"
|
name = "hashbrown"
|
||||||
version = "0.14.5"
|
version = "0.14.5"
|
||||||
|
|
@ -445,6 +525,12 @@ version = "0.3.9"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "d231dfb89cfffdbc30e7fc41579ed6066ad03abda9e567ccafae602b97ec5024"
|
checksum = "d231dfb89cfffdbc30e7fc41579ed6066ad03abda9e567ccafae602b97ec5024"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "hex"
|
||||||
|
version = "0.4.3"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "7f24254aa9a54b5c858eaee2f5bccdb46aaf0e486a595ed5fd8f86ba55232a70"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "http"
|
name = "http"
|
||||||
version = "1.1.0"
|
version = "1.1.0"
|
||||||
|
|
@ -558,6 +644,35 @@ dependencies = [
|
||||||
"tracing",
|
"tracing",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "iana-time-zone"
|
||||||
|
version = "0.1.61"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "235e081f3925a06703c2d0117ea8b91f042756fd6e7a6e5d901e8ca1a996b220"
|
||||||
|
dependencies = [
|
||||||
|
"android_system_properties",
|
||||||
|
"core-foundation-sys",
|
||||||
|
"iana-time-zone-haiku",
|
||||||
|
"js-sys",
|
||||||
|
"wasm-bindgen",
|
||||||
|
"windows-core",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "iana-time-zone-haiku"
|
||||||
|
version = "0.1.2"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "f31827a206f56af32e590ba56d5d2d085f558508192593743f16b2306495269f"
|
||||||
|
dependencies = [
|
||||||
|
"cc",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "ident_case"
|
||||||
|
version = "1.0.1"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "b9e0384b61958566e926dc50660321d12159025e767c18e043daf26b70104c39"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "idna"
|
name = "idna"
|
||||||
version = "0.5.0"
|
version = "0.5.0"
|
||||||
|
|
@ -568,6 +683,17 @@ dependencies = [
|
||||||
"unicode-normalization",
|
"unicode-normalization",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "indexmap"
|
||||||
|
version = "1.9.3"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "bd070e393353796e801d209ad339e89596eb4c8d430d18ede6a1cced8fafbd99"
|
||||||
|
dependencies = [
|
||||||
|
"autocfg 1.3.0",
|
||||||
|
"hashbrown 0.12.3",
|
||||||
|
"serde",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "indexmap"
|
name = "indexmap"
|
||||||
version = "2.2.6"
|
version = "2.2.6"
|
||||||
|
|
@ -575,7 +701,8 @@ source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "168fb715dda47215e360912c096649d23d58bf392ac62f73919e831745e40f26"
|
checksum = "168fb715dda47215e360912c096649d23d58bf392ac62f73919e831745e40f26"
|
||||||
dependencies = [
|
dependencies = [
|
||||||
"equivalent",
|
"equivalent",
|
||||||
"hashbrown",
|
"hashbrown 0.14.5",
|
||||||
|
"serde",
|
||||||
]
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
|
|
@ -701,6 +828,12 @@ dependencies = [
|
||||||
"tempfile",
|
"tempfile",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "num-conv"
|
||||||
|
version = "0.1.0"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "51d515d32fb182ee37cda2ccdcb92950d6a3c2893aa280e540671c2cd0f3b1d9"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "num-traits"
|
name = "num-traits"
|
||||||
version = "0.2.19"
|
version = "0.2.19"
|
||||||
|
|
@ -846,6 +979,12 @@ version = "0.3.30"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "d231b230927b5e4ad203db57bbcbee2802f6bce620b1e4a9024a07d94e2907ec"
|
checksum = "d231b230927b5e4ad203db57bbcbee2802f6bce620b1e4a9024a07d94e2907ec"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "powerfmt"
|
||||||
|
version = "0.2.0"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "439ee305def115ba05938db6eb1644ff94165c5ab5e9420d1c1bcedbba909391"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "proc-macro2"
|
name = "proc-macro2"
|
||||||
version = "1.0.86"
|
version = "1.0.86"
|
||||||
|
|
@ -1293,6 +1432,36 @@ dependencies = [
|
||||||
"serde",
|
"serde",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "serde_with"
|
||||||
|
version = "3.9.0"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "69cecfa94848272156ea67b2b1a53f20fc7bc638c4a46d2f8abde08f05f4b857"
|
||||||
|
dependencies = [
|
||||||
|
"base64 0.22.1",
|
||||||
|
"chrono",
|
||||||
|
"hex",
|
||||||
|
"indexmap 1.9.3",
|
||||||
|
"indexmap 2.2.6",
|
||||||
|
"serde",
|
||||||
|
"serde_derive",
|
||||||
|
"serde_json",
|
||||||
|
"serde_with_macros",
|
||||||
|
"time",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "serde_with_macros"
|
||||||
|
version = "3.9.0"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "a8fee4991ef4f274617a51ad4af30519438dacb2f56ac773b08a1922ff743350"
|
||||||
|
dependencies = [
|
||||||
|
"darling",
|
||||||
|
"proc-macro2",
|
||||||
|
"quote",
|
||||||
|
"syn",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "signal-hook-registry"
|
name = "signal-hook-registry"
|
||||||
version = "1.4.2"
|
version = "1.4.2"
|
||||||
|
|
@ -1342,6 +1511,12 @@ dependencies = [
|
||||||
"log 0.3.9",
|
"log 0.3.9",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "strsim"
|
||||||
|
version = "0.11.1"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "7da8b5736845d9f2fcb837ea5d9e2628564b3b043a70948a3f0b778838c5fb4f"
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "subtle"
|
name = "subtle"
|
||||||
version = "2.6.1"
|
version = "2.6.1"
|
||||||
|
|
@ -1489,6 +1664,37 @@ dependencies = [
|
||||||
"lazy_static",
|
"lazy_static",
|
||||||
]
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "time"
|
||||||
|
version = "0.3.36"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "5dfd88e563464686c916c7e46e623e520ddc6d79fa6641390f2e3fa86e83e885"
|
||||||
|
dependencies = [
|
||||||
|
"deranged",
|
||||||
|
"itoa",
|
||||||
|
"num-conv",
|
||||||
|
"powerfmt",
|
||||||
|
"serde",
|
||||||
|
"time-core",
|
||||||
|
"time-macros",
|
||||||
|
]
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "time-core"
|
||||||
|
version = "0.1.2"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "ef927ca75afb808a4d64dd374f00a2adf8d0fcff8e7b184af886c3c87ec4a3f3"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "time-macros"
|
||||||
|
version = "0.2.18"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "3f252a68540fde3a3877aeea552b832b40ab9a69e318efd078774a01ddee1ccf"
|
||||||
|
dependencies = [
|
||||||
|
"num-conv",
|
||||||
|
"time-core",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "tinyvec"
|
name = "tinyvec"
|
||||||
version = "1.7.0"
|
version = "1.7.0"
|
||||||
|
|
@ -1843,6 +2049,15 @@ version = "0.4.0"
|
||||||
source = "registry+https://github.com/rust-lang/crates.io-index"
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f"
|
checksum = "712e227841d057c1ee1cd2fb22fa7e5a5461ae8e48fa2ca79ec42cfc1931183f"
|
||||||
|
|
||||||
|
[[package]]
|
||||||
|
name = "windows-core"
|
||||||
|
version = "0.52.0"
|
||||||
|
source = "registry+https://github.com/rust-lang/crates.io-index"
|
||||||
|
checksum = "33ab640c8d7e35bf8ba19b884ba838ceb4fba93a4e8c65a9059d08afcfc683d9"
|
||||||
|
dependencies = [
|
||||||
|
"windows-targets 0.52.6",
|
||||||
|
]
|
||||||
|
|
||||||
[[package]]
|
[[package]]
|
||||||
name = "windows-sys"
|
name = "windows-sys"
|
||||||
version = "0.48.0"
|
version = "0.48.0"
|
||||||
|
|
|
||||||
|
|
@ -1,13 +1,13 @@
|
||||||
[package]
|
[package]
|
||||||
name = "firecrawl"
|
name = "firecrawl"
|
||||||
author="Mendable.ai"
|
author= "Mendable.ai"
|
||||||
version = "0.1.0"
|
version = "1.0.0"
|
||||||
edition = "2021"
|
edition = "2021"
|
||||||
license = "GPL-2.0-or-later"
|
license = "MIT"
|
||||||
homepage = "https://www.firecrawl.dev/"
|
homepage = "https://www.firecrawl.dev/"
|
||||||
repository ="https://github.com/mendableai/firecrawl"
|
repository ="https://github.com/mendableai/firecrawl"
|
||||||
description = "Rust SDK for Firecrawl API."
|
description = "Rust SDK for Firecrawl API."
|
||||||
authors = ["sanix-darker <sanixdk@gmail.com>"]
|
authors = ["Gergő Móricz <mogery@firecrawl.dev>", "sanix-darker <sanixdk@gmail.com>"]
|
||||||
|
|
||||||
[lib]
|
[lib]
|
||||||
path = "src/lib.rs"
|
path = "src/lib.rs"
|
||||||
|
|
@ -18,6 +18,7 @@ name = "firecrawl"
|
||||||
reqwest = { version = "^0.12", features = ["json", "blocking"] }
|
reqwest = { version = "^0.12", features = ["json", "blocking"] }
|
||||||
serde = { version = "^1.0", features = ["derive"] }
|
serde = { version = "^1.0", features = ["derive"] }
|
||||||
serde_json = "^1.0"
|
serde_json = "^1.0"
|
||||||
|
serde_with = "^3.9"
|
||||||
log = "^0.4"
|
log = "^0.4"
|
||||||
thiserror = "^1.0"
|
thiserror = "^1.0"
|
||||||
uuid = { version = "^1.10", features = ["v4"] }
|
uuid = { version = "^1.10", features = ["v4"] }
|
||||||
|
|
@ -27,7 +28,7 @@ tokio = { version = "^1", features = ["full"] }
|
||||||
clippy = "^0.0.302"
|
clippy = "^0.0.302"
|
||||||
rustfmt = "^0.10"
|
rustfmt = "^0.10"
|
||||||
assert_matches = "^1.5"
|
assert_matches = "^1.5"
|
||||||
dotenv = "^0.15"
|
dotenvy = "^0.15"
|
||||||
tokio = { version = "1", features = ["full"] }
|
tokio = { version = "1", features = ["full"] }
|
||||||
|
|
||||||
[build-dependencies]
|
[build-dependencies]
|
||||||
|
|
|
||||||
|
|
@ -1,5 +1,4 @@
|
||||||
# Firecrawl Rust SDK
|
# Firecrawl Rust SDK
|
||||||
|
|
||||||
The Firecrawl Rust SDK is a library that allows you to easily scrape and crawl websites, and output the data in a format ready for use with language models (LLMs). It provides a simple and intuitive interface for interacting with the Firecrawl API.
|
The Firecrawl Rust SDK is a library that allows you to easily scrape and crawl websites, and output the data in a format ready for use with language models (LLMs). It provides a simple and intuitive interface for interacting with the Firecrawl API.
|
||||||
|
|
||||||
## Installation
|
## Installation
|
||||||
|
|
@ -10,53 +9,41 @@ To install the Firecrawl Rust SDK, add the following to your `Cargo.toml`:
|
||||||
[dependencies]
|
[dependencies]
|
||||||
firecrawl = "^0.1"
|
firecrawl = "^0.1"
|
||||||
tokio = { version = "^1", features = ["full"] }
|
tokio = { version = "^1", features = ["full"] }
|
||||||
serde = { version = "^1.0", features = ["derive"] }
|
|
||||||
serde_json = "^1.0"
|
|
||||||
uuid = { version = "^1.10", features = ["v4"] }
|
|
||||||
|
|
||||||
[build-dependencies]
|
|
||||||
tokio = { version = "1", features = ["full"] }
|
|
||||||
```
|
```
|
||||||
|
|
||||||
To add it in your codebase.
|
To add it in your codebase.
|
||||||
|
|
||||||
## Usage
|
## Usage
|
||||||
|
|
||||||
1. Get an API key from [firecrawl.dev](https://firecrawl.dev)
|
First, you need to obtain an API key from [firecrawl.dev](https://firecrawl.dev). Then, you need to initialize the `FirecrawlApp` like so:
|
||||||
2. Set the API key as an environment variable named `FIRECRAWL_API_KEY` or pass it as a parameter to the `FirecrawlApp` struct.
|
|
||||||
|
|
||||||
Here's an example of how to use the SDK in [example.rs](./examples/example.rs):
|
|
||||||
All below example can start with :
|
|
||||||
```rust
|
```rust
|
||||||
use firecrawl::FirecrawlApp;
|
use firecrawl::FirecrawlApp;
|
||||||
|
|
||||||
#[tokio::main]
|
#[tokio::main]
|
||||||
async fn main() {
|
async fn main() {
|
||||||
// Initialize the FirecrawlApp with the API key
|
// Initialize the FirecrawlApp with the API key
|
||||||
let api_key = ...;
|
let app = FirecrawlApp::new("fc-YOUR-API-KEY").expect("Failed to initialize FirecrawlApp");
|
||||||
let api_url = ...;
|
|
||||||
let app = FirecrawlApp::new(api_key, api_url).expect("Failed to initialize FirecrawlApp");
|
|
||||||
|
|
||||||
// your code here...
|
// ...
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Scraping a URL
|
### Scraping a URL
|
||||||
|
|
||||||
To scrape a single URL, use the `scrape_url` method. It takes the URL as a parameter and returns the scraped data as a `serde_json::Value`.
|
To scrape a single URL, use the `scrape_url` method. It takes the URL as a parameter and returns the scraped data as a `Document`.
|
||||||
|
|
||||||
```rust
|
```rust
|
||||||
// Example scrape code...
|
let scrape_result = app.scrape_url("https://firecrawl.dev", None).await;
|
||||||
let scrape_result = app.scrape_url("https://example.com", None).await;
|
|
||||||
match scrape_result {
|
match scrape_result {
|
||||||
Ok(data) => println!("Scrape Result:\n{}", data["markdown"]),
|
Ok(data) => println!("Scrape result:\n{}", data.markdown),
|
||||||
Err(e) => eprintln!("Scrape failed: {}", e),
|
Err(e) => eprintln!("Scrape failed: {}", e),
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Extracting structured data from a URL
|
### Scraping with Extract
|
||||||
|
|
||||||
With LLM extraction, you can easily extract structured data from any URL. We support Serde for JSON schema validation to make it easier for you too. Here is how you use it:
|
With Extract, you can easily extract structured data from any URL. You need to specify your schema in the JSON Schema format, using the `serde_json::json!` macro.
|
||||||
|
|
||||||
```rust
|
```rust
|
||||||
let json_schema = json!({
|
let json_schema = json!({
|
||||||
|
|
@ -82,83 +69,81 @@ let json_schema = json!({
|
||||||
"required": ["top"]
|
"required": ["top"]
|
||||||
});
|
});
|
||||||
|
|
||||||
let llm_extraction_params = json!({
|
let llm_extraction_options = ScrapeOptions {
|
||||||
"extractorOptions": {
|
formats: vec![ ScrapeFormats::Extract ].into(),
|
||||||
"extractionSchema": json_schema,
|
extract: ExtractOptions {
|
||||||
"mode": "llm-extraction"
|
schema: json_schema.into(),
|
||||||
},
|
..Default::default()
|
||||||
"pageOptions": {
|
}.into(),
|
||||||
"onlyMainContent": true
|
..Default::default()
|
||||||
}
|
};
|
||||||
});
|
|
||||||
|
|
||||||
// Example scrape code...
|
|
||||||
let llm_extraction_result = app
|
let llm_extraction_result = app
|
||||||
.scrape_url("https://news.ycombinator.com", Some(llm_extraction_params))
|
.scrape_url("https://news.ycombinator.com", llm_extraction_options)
|
||||||
.await;
|
.await;
|
||||||
|
|
||||||
match llm_extraction_result {
|
match llm_extraction_result {
|
||||||
Ok(data) => println!("LLM Extraction Result:\n{}", data["llm_extraction"]),
|
Ok(data) => println!("LLM Extraction Result:\n{:#?}", data.extract.unwrap()),
|
||||||
Err(e) => eprintln!("LLM Extraction failed: {}", e),
|
Err(e) => eprintln!("LLM Extraction failed: {}", e),
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Search for a query
|
|
||||||
|
|
||||||
Used to search the web, get the most relevant results, scrape each page, and return the markdown.
|
|
||||||
|
|
||||||
```rust
|
|
||||||
// Example query search code...
|
|
||||||
let query = "what is mendable?";
|
|
||||||
let search_result = app.search(query).await;
|
|
||||||
match search_result {
|
|
||||||
Ok(data) => println!("Search Result:\n{}", data),
|
|
||||||
Err(e) => eprintln!("Search failed: {}", e),
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### Crawling a Website
|
### Crawling a Website
|
||||||
|
|
||||||
To crawl a website, use the `crawl_url` method. It takes the starting URL and optional parameters as arguments. The `params` argument allows you to specify additional options for the crawl job, such as the maximum number of pages to crawl, allowed domains, and the output format.
|
To crawl a website, use the `crawl_url` method. This will wait for the crawl to complete, which may take a long time based on your starting URL and your options.
|
||||||
|
|
||||||
The `wait_until_done` parameter determines whether the method should wait for the crawl job to complete before returning the result. If set to `true`, the method will periodically check the status of the crawl job until it is completed or the specified `timeout` (in seconds) is reached. If set to `false`, the method will return immediately with the job ID, and you can manually check the status of the crawl job using the `check_crawl_status` method.
|
|
||||||
|
|
||||||
```rust
|
```rust
|
||||||
let random_uuid = String::from(Uuid::new_v4());
|
let crawl_options = CrawlOptions {
|
||||||
let idempotency_key = Some(random_uuid); // optional idempotency key
|
exclude_paths: vec![ "blog/*".into() ].into(),
|
||||||
let crawl_params = json!({
|
..Default::default()
|
||||||
"crawlerOptions": {
|
};
|
||||||
"excludes": ["blog/*"]
|
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
// Example crawl code...
|
|
||||||
let crawl_result = app
|
let crawl_result = app
|
||||||
.crawl_url("https://example.com", Some(crawl_params), true, 2, idempotency_key)
|
.crawl_url("https://mendable.ai", crawl_options)
|
||||||
.await;
|
.await;
|
||||||
|
|
||||||
match crawl_result {
|
match crawl_result {
|
||||||
Ok(data) => println!("Crawl Result:\n{}", data),
|
Ok(data) => println!("Crawl Result (used {} credits):\n{:#?}", data.credits_used, data.data),
|
||||||
Err(e) => eprintln!("Crawl failed: {}", e),
|
Err(e) => eprintln!("Crawl failed: {}", e),
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
If `wait_until_done` is set to `true`, the `crawl_url` method will return the crawl result once the job is completed. If the job fails or is stopped, an exception will be raised.
|
#### Crawling asynchronously
|
||||||
|
|
||||||
### Checking Crawl Status
|
To crawl without waiting for the result, use the `crawl_url_async` method. It takes the same parameters, but it returns a `CrawlAsyncRespone` struct, containing the crawl's ID. You can use that ID with the `check_crawl_status` method to check the status at any time. Do note that completed crawls are deleted after 24 hours.
|
||||||
|
|
||||||
To check the status of a crawl job, use the `check_crawl_status` method. It takes the job ID as a parameter and returns the current status of the crawl job.
|
|
||||||
|
|
||||||
```rust
|
```rust
|
||||||
let job_id = crawl_result["jobId"].as_str().expect("Job ID not found");
|
let crawl_id = app.crawl_url_async("https://mendable.ai", None).await?.id;
|
||||||
let status = app.check_crawl_status(job_id).await;
|
|
||||||
match status {
|
// ... later ...
|
||||||
Ok(data) => println!("Crawl Status:\n{}", data),
|
|
||||||
Err(e) => eprintln!("Failed to check crawl status: {}", e),
|
let status = app.check_crawl_status(crawl_id).await?;
|
||||||
|
|
||||||
|
if status.status == CrawlStatusTypes::Completed {
|
||||||
|
println!("Crawl is done: {:#?}", status.data);
|
||||||
|
} else {
|
||||||
|
// ... wait some more ...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Map a URL (Alpha)
|
||||||
|
|
||||||
|
Map all associated links from a starting URL.
|
||||||
|
|
||||||
|
```rust
|
||||||
|
let map_result = app
|
||||||
|
.map_url("https://firecrawl.dev", None)
|
||||||
|
.await;
|
||||||
|
|
||||||
|
match map_result {
|
||||||
|
Ok(data) => println!("Mapped URLs: {:#?}", data),
|
||||||
|
Err(e) => eprintln!("Map failed: {}", e),
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## Error Handling
|
## Error Handling
|
||||||
|
|
||||||
The SDK handles errors returned by the Firecrawl API and raises appropriate exceptions. If an error occurs during a request, an exception will be raised with a descriptive error message.
|
The SDK handles errors returned by the Firecrawl API and by our dependencies, and combines them into the `FirecrawlError` enum, implementing `Error`, `Debug` and `Display`. All of our methods return a `Result<T, FirecrawlError>`.
|
||||||
|
|
||||||
## Running the Tests with Cargo
|
## Running the Tests with Cargo
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -1,44 +1,38 @@
|
||||||
use firecrawl::FirecrawlApp;
|
use firecrawl::{crawl::CrawlOptions, scrape::{ExtractOptions, ScrapeFormats, ScrapeOptions}, FirecrawlApp};
|
||||||
use serde_json::json;
|
use serde_json::json;
|
||||||
use uuid::Uuid;
|
|
||||||
|
|
||||||
#[tokio::main]
|
#[tokio::main]
|
||||||
async fn main() {
|
async fn main() {
|
||||||
// Initialize the FirecrawlApp with the API key
|
// Initialize the FirecrawlApp with the API key
|
||||||
let api_key = Some("fc-YOUR_API_KEY".to_string());
|
let app = FirecrawlApp::new("fc-YOUR-API-KEY").expect("Failed to initialize FirecrawlApp");
|
||||||
let api_url = Some("http://0.0.0.0:3002".to_string());
|
|
||||||
let app = FirecrawlApp::new(api_key, api_url).expect("Failed to initialize FirecrawlApp");
|
// Or, connect to a self-hosted instance:
|
||||||
|
// let app = FirecrawlApp::new_selfhosted("http://localhost:3002", None).expect("Failed to initialize FirecrawlApp");
|
||||||
|
|
||||||
// Scrape a website
|
// Scrape a website
|
||||||
let scrape_result = app.scrape_url("https://firecrawl.dev", None).await;
|
let scrape_result = app.scrape_url("https://firecrawl.dev", None).await;
|
||||||
|
|
||||||
match scrape_result {
|
match scrape_result {
|
||||||
Ok(data) => println!("Scrape Result:\n{}", data["markdown"]),
|
Ok(data) => println!("Scrape Result:\n{}", data.markdown.unwrap()),
|
||||||
Err(e) => eprintln!("Scrape failed: {}", e),
|
Err(e) => eprintln!("Scrape failed: {:#?}", e),
|
||||||
}
|
}
|
||||||
|
|
||||||
// Crawl a website
|
// Crawl a website
|
||||||
let random_uuid = String::from(Uuid::new_v4());
|
let crawl_options = CrawlOptions {
|
||||||
let idempotency_key = Some(random_uuid); // optional idempotency key
|
exclude_paths: vec![ "blog/*".into() ].into(),
|
||||||
let crawl_params = json!({
|
..Default::default()
|
||||||
"crawlerOptions": {
|
};
|
||||||
"excludes": ["blog/*"]
|
|
||||||
}
|
|
||||||
});
|
|
||||||
let crawl_result = app
|
let crawl_result = app
|
||||||
.crawl_url(
|
.crawl_url("https://mendable.ai", crawl_options)
|
||||||
"https://mendable.ai",
|
|
||||||
Some(crawl_params),
|
|
||||||
true,
|
|
||||||
2,
|
|
||||||
idempotency_key,
|
|
||||||
)
|
|
||||||
.await;
|
.await;
|
||||||
|
|
||||||
match crawl_result {
|
match crawl_result {
|
||||||
Ok(data) => println!("Crawl Result:\n{}", data),
|
Ok(data) => println!("Crawl Result (used {} credits):\n{:#?}", data.credits_used, data.data),
|
||||||
Err(e) => eprintln!("Crawl failed: {}", e),
|
Err(e) => eprintln!("Crawl failed: {}", e),
|
||||||
}
|
}
|
||||||
|
|
||||||
// LLM Extraction with a JSON schema
|
// Scrape with Extract
|
||||||
let json_schema = json!({
|
let json_schema = json!({
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
|
|
@ -62,21 +56,31 @@ async fn main() {
|
||||||
"required": ["top"]
|
"required": ["top"]
|
||||||
});
|
});
|
||||||
|
|
||||||
let llm_extraction_params = json!({
|
let llm_extraction_options = ScrapeOptions {
|
||||||
"extractorOptions": {
|
formats: vec![ ScrapeFormats::Extract ].into(),
|
||||||
"extractionSchema": json_schema,
|
extract: ExtractOptions {
|
||||||
"mode": "llm-extraction"
|
schema: json_schema.into(),
|
||||||
},
|
..Default::default()
|
||||||
"pageOptions": {
|
}.into(),
|
||||||
"onlyMainContent": true
|
..Default::default()
|
||||||
}
|
};
|
||||||
});
|
|
||||||
|
|
||||||
let llm_extraction_result = app
|
let llm_extraction_result = app
|
||||||
.scrape_url("https://news.ycombinator.com", Some(llm_extraction_params))
|
.scrape_url("https://news.ycombinator.com", llm_extraction_options)
|
||||||
.await;
|
.await;
|
||||||
|
|
||||||
match llm_extraction_result {
|
match llm_extraction_result {
|
||||||
Ok(data) => println!("LLM Extraction Result:\n{}", data["llm_extraction"]),
|
Ok(data) => println!("LLM Extraction Result:\n{:#?}", data.extract.unwrap()),
|
||||||
Err(e) => eprintln!("LLM Extraction failed: {}", e),
|
Err(e) => eprintln!("LLM Extraction failed: {}", e),
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// Map a website (Alpha)
|
||||||
|
let map_result = app
|
||||||
|
.map_url("https://firecrawl.dev", None)
|
||||||
|
.await;
|
||||||
|
|
||||||
|
match map_result {
|
||||||
|
Ok(data) => println!("Mapped URLs: {:#?}", data),
|
||||||
|
Err(e) => eprintln!("Map failed: {}", e),
|
||||||
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
319
apps/rust-sdk/src/crawl.rs
Normal file
319
apps/rust-sdk/src/crawl.rs
Normal file
|
|
@ -0,0 +1,319 @@
|
||||||
|
use std::collections::HashMap;
|
||||||
|
|
||||||
|
use serde::{Deserialize, Serialize};
|
||||||
|
|
||||||
|
use crate::{document::Document, scrape::{ScrapeFormats, ScrapeOptions}, FirecrawlApp, FirecrawlError, API_VERSION};
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Clone, Copy, Debug)]
|
||||||
|
pub enum CrawlScrapeFormats {
|
||||||
|
/// Will result in a copy of the Markdown content of the page.
|
||||||
|
#[serde(rename = "markdown")]
|
||||||
|
Markdown,
|
||||||
|
|
||||||
|
/// Will result in a copy of the filtered, content-only HTML of the page.
|
||||||
|
#[serde(rename = "html")]
|
||||||
|
HTML,
|
||||||
|
|
||||||
|
/// Will result in a copy of the raw HTML of the page.
|
||||||
|
#[serde(rename = "rawHtml")]
|
||||||
|
RawHTML,
|
||||||
|
|
||||||
|
/// Will result in a Vec of URLs found on the page.
|
||||||
|
#[serde(rename = "links")]
|
||||||
|
Links,
|
||||||
|
|
||||||
|
/// Will result in a URL to a screenshot of the page.
|
||||||
|
///
|
||||||
|
/// Can not be used in conjunction with `CrawlScrapeFormats::ScreenshotFullPage`.
|
||||||
|
#[serde(rename = "screenshot")]
|
||||||
|
Screenshot,
|
||||||
|
|
||||||
|
/// Will result in a URL to a full-page screenshot of the page.
|
||||||
|
///
|
||||||
|
/// Can not be used in conjunction with `CrawlScrapeFormats::Screenshot`.
|
||||||
|
#[serde(rename = "screenshot@fullPage")]
|
||||||
|
ScreenshotFullPage,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl From<CrawlScrapeFormats> for ScrapeFormats {
|
||||||
|
fn from(value: CrawlScrapeFormats) -> Self {
|
||||||
|
match value {
|
||||||
|
CrawlScrapeFormats::Markdown => Self::Markdown,
|
||||||
|
CrawlScrapeFormats::HTML => Self::HTML,
|
||||||
|
CrawlScrapeFormats::RawHTML => Self::RawHTML,
|
||||||
|
CrawlScrapeFormats::Links => Self::Links,
|
||||||
|
CrawlScrapeFormats::Screenshot => Self::Screenshot,
|
||||||
|
CrawlScrapeFormats::ScreenshotFullPage => Self::ScreenshotFullPage,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct CrawlScrapeOptions {
|
||||||
|
/// Formats to extract from the page. (default: `[ Markdown ]`)
|
||||||
|
pub formats: Option<Vec<CrawlScrapeFormats>>,
|
||||||
|
|
||||||
|
/// Only extract the main content of the page, excluding navigation and other miscellaneous content. (default: `true`)
|
||||||
|
pub only_main_content: Option<bool>,
|
||||||
|
|
||||||
|
/// HTML tags to exclusively include.
|
||||||
|
///
|
||||||
|
/// For example, if you pass `div`, you will only get content from `<div>`s and their children.
|
||||||
|
pub include_tags: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// HTML tags to exclude.
|
||||||
|
///
|
||||||
|
/// For example, if you pass `img`, you will never get image URLs in your results.
|
||||||
|
pub exclude_tags: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// Additional HTTP headers to use when loading the page.
|
||||||
|
pub headers: Option<HashMap<String, String>>,
|
||||||
|
|
||||||
|
// Amount of time to wait after loading the page, and before grabbing the content, in milliseconds. (default: `0`)
|
||||||
|
pub wait_for: Option<u32>,
|
||||||
|
|
||||||
|
// Timeout before returning an error, in milliseconds. (default: `60000`)
|
||||||
|
pub timeout: Option<u32>,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl From<CrawlScrapeOptions> for ScrapeOptions {
|
||||||
|
fn from(value: CrawlScrapeOptions) -> Self {
|
||||||
|
ScrapeOptions {
|
||||||
|
formats: value.formats.map(|formats| formats.into_iter().map(|x| x.into()).collect()),
|
||||||
|
only_main_content: value.only_main_content,
|
||||||
|
include_tags: value.include_tags,
|
||||||
|
exclude_tags: value.exclude_tags,
|
||||||
|
headers: value.headers,
|
||||||
|
wait_for: value.wait_for,
|
||||||
|
timeout: value.timeout,
|
||||||
|
..Default::default()
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct CrawlOptions {
|
||||||
|
/// Options to pass through to the scraper.
|
||||||
|
pub scrape_options: Option<CrawlScrapeOptions>,
|
||||||
|
|
||||||
|
/// URL RegEx patterns to (exclusively) include.
|
||||||
|
///
|
||||||
|
/// For example, if you specified `"blog"`, only pages that have `blog` somewhere in the URL would be crawled.
|
||||||
|
pub include_paths: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// URL RegEx patterns to exclude.
|
||||||
|
///
|
||||||
|
/// For example, if you specified `"blog"`, pages that have `blog` somewhere in the URL would not be crawled.
|
||||||
|
pub exclude_paths: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// Maximum URL depth to crawl, relative to the base URL. (default: `2`)
|
||||||
|
pub max_depth: Option<u32>,
|
||||||
|
|
||||||
|
/// Tells the crawler to ignore the sitemap when crawling. (default: `true`)
|
||||||
|
pub ignore_sitemap: Option<bool>,
|
||||||
|
|
||||||
|
/// Maximum number of pages to crawl. (default: `10`)
|
||||||
|
pub limit: Option<u32>,
|
||||||
|
|
||||||
|
/// Allows the crawler to navigate links that are backwards in the URL hierarchy. (default: `false`)
|
||||||
|
pub allow_backward_links: Option<bool>,
|
||||||
|
|
||||||
|
/// Allows the crawler to follow links to external URLs. (default: `false`)
|
||||||
|
pub allow_external_links: Option<bool>,
|
||||||
|
|
||||||
|
/// URL to send Webhook crawl events to.
|
||||||
|
pub webhook: Option<String>,
|
||||||
|
|
||||||
|
/// Idempotency key to send to the crawl endpoint.
|
||||||
|
#[serde(skip)]
|
||||||
|
pub idempotency_key: Option<String>,
|
||||||
|
|
||||||
|
/// When using `FirecrawlApp::crawl_url`, this is how often the status of the job should be checked, in milliseconds. (default: `2000`)
|
||||||
|
#[serde(skip)]
|
||||||
|
pub poll_interval: Option<u64>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct CrawlRequestBody {
|
||||||
|
url: String,
|
||||||
|
|
||||||
|
#[serde(flatten)]
|
||||||
|
options: CrawlOptions,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct CrawlResponse {
|
||||||
|
/// This will always be `true` due to `FirecrawlApp::handle_response`.
|
||||||
|
/// No need to expose.
|
||||||
|
success: bool,
|
||||||
|
|
||||||
|
/// The resulting document.
|
||||||
|
data: Document,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, PartialEq, Eq, Clone, Copy)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub enum CrawlStatusTypes {
|
||||||
|
/// The crawl job is in progress.
|
||||||
|
Scraping,
|
||||||
|
|
||||||
|
/// The crawl job has been completed successfully.
|
||||||
|
Completed,
|
||||||
|
|
||||||
|
/// The crawl job has failed.
|
||||||
|
Failed,
|
||||||
|
|
||||||
|
/// The crawl job has been cancelled.
|
||||||
|
Cancelled,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct CrawlStatus {
|
||||||
|
/// The status of the crawl.
|
||||||
|
pub status: CrawlStatusTypes,
|
||||||
|
|
||||||
|
/// Number of pages that will be scraped in total. This number may grow as the crawler discovers new pages.
|
||||||
|
pub total: u32,
|
||||||
|
|
||||||
|
/// Number of pages that have been successfully scraped.
|
||||||
|
pub completed: u32,
|
||||||
|
|
||||||
|
/// Amount of credits used by the crawl job.
|
||||||
|
pub credits_used: u32,
|
||||||
|
|
||||||
|
/// Expiry time of crawl data. After this date, the crawl data will be unavailable from the API.
|
||||||
|
pub expires_at: String, // TODO: parse into date
|
||||||
|
|
||||||
|
/// URL to call to get the next batch of documents.
|
||||||
|
/// Unless you are sidestepping the SDK, you do not need to deal with this.
|
||||||
|
pub next: Option<String>,
|
||||||
|
|
||||||
|
/// List of documents returned by the crawl
|
||||||
|
pub data: Vec<Document>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct CrawlAsyncResponse {
|
||||||
|
success: bool,
|
||||||
|
|
||||||
|
/// Crawl ID
|
||||||
|
pub id: String,
|
||||||
|
|
||||||
|
/// URL to get the status of the crawl job
|
||||||
|
pub url: String,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl FirecrawlApp {
|
||||||
|
/// Initiates a crawl job for a URL using the Firecrawl API.
|
||||||
|
pub async fn crawl_url_async(
|
||||||
|
&self,
|
||||||
|
url: impl AsRef<str>,
|
||||||
|
options: Option<CrawlOptions>,
|
||||||
|
) -> Result<CrawlAsyncResponse, FirecrawlError> {
|
||||||
|
let body = CrawlRequestBody {
|
||||||
|
url: url.as_ref().to_string(),
|
||||||
|
options: options.unwrap_or_default(),
|
||||||
|
};
|
||||||
|
|
||||||
|
let headers = self.prepare_headers(body.options.idempotency_key.as_ref());
|
||||||
|
|
||||||
|
let response = self
|
||||||
|
.client
|
||||||
|
.post(&format!("{}{}/crawl", self.api_url, API_VERSION))
|
||||||
|
.headers(headers.clone())
|
||||||
|
.json(&body)
|
||||||
|
.send()
|
||||||
|
.await
|
||||||
|
.map_err(|e| FirecrawlError::HttpError(format!("Crawling {:?}", url.as_ref()), e))?;
|
||||||
|
|
||||||
|
self.handle_response::<CrawlAsyncResponse>(response, "start crawl job").await
|
||||||
|
}
|
||||||
|
|
||||||
|
/// Performs a crawl job for a URL using the Firecrawl API, waiting for the end result. This may take a long time depending on the size of the target page and your options (namely `CrawlOptions.limit`).
|
||||||
|
pub async fn crawl_url(
|
||||||
|
&self,
|
||||||
|
url: impl AsRef<str>,
|
||||||
|
options: impl Into<Option<CrawlOptions>>,
|
||||||
|
) -> Result<CrawlStatus, FirecrawlError> {
|
||||||
|
let options = options.into();
|
||||||
|
let poll_interval = options.as_ref().and_then(|x| x.poll_interval).unwrap_or(2000);
|
||||||
|
let res = self.crawl_url_async(url, options).await?;
|
||||||
|
|
||||||
|
self.monitor_job_status(&res.id, poll_interval).await
|
||||||
|
}
|
||||||
|
|
||||||
|
async fn check_crawl_status_next(&self, next: impl AsRef<str>) -> Result<CrawlStatus, FirecrawlError> {
|
||||||
|
let response = self
|
||||||
|
.client
|
||||||
|
.get(next.as_ref())
|
||||||
|
.headers(self.prepare_headers(None))
|
||||||
|
.send()
|
||||||
|
.await
|
||||||
|
.map_err(|e| FirecrawlError::HttpError(format!("Paginating crawl using URL {:?}", next.as_ref()), e))?;
|
||||||
|
|
||||||
|
self.handle_response(response, format!("Paginating crawl using URL {:?}", next.as_ref())).await
|
||||||
|
}
|
||||||
|
|
||||||
|
/// Checks for the status of a crawl, based on the crawl's ID. To be used in conjunction with `FirecrawlApp::crawl_url_async`.
|
||||||
|
pub async fn check_crawl_status(&self, id: impl AsRef<str>) -> Result<CrawlStatus, FirecrawlError> {
|
||||||
|
let response = self
|
||||||
|
.client
|
||||||
|
.get(&format!(
|
||||||
|
"{}{}/crawl/{}",
|
||||||
|
self.api_url, API_VERSION, id.as_ref()
|
||||||
|
))
|
||||||
|
.headers(self.prepare_headers(None))
|
||||||
|
.send()
|
||||||
|
.await
|
||||||
|
.map_err(|e| FirecrawlError::HttpError(format!("Checking status of crawl {}", id.as_ref()), e))?;
|
||||||
|
|
||||||
|
let mut status: CrawlStatus = self.handle_response(response, format!("Checking status of crawl {}", id.as_ref())).await?;
|
||||||
|
|
||||||
|
if status.status == CrawlStatusTypes::Completed {
|
||||||
|
while let Some(next) = status.next {
|
||||||
|
let new_status = self.check_crawl_status_next(next).await?;
|
||||||
|
status.data.extend_from_slice(&new_status.data);
|
||||||
|
status.next = new_status.next;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
Ok(status)
|
||||||
|
}
|
||||||
|
|
||||||
|
async fn monitor_job_status(
|
||||||
|
&self,
|
||||||
|
id: &str,
|
||||||
|
poll_interval: u64,
|
||||||
|
) -> Result<CrawlStatus, FirecrawlError> {
|
||||||
|
loop {
|
||||||
|
let status_data = self.check_crawl_status(id).await?;
|
||||||
|
match status_data.status {
|
||||||
|
CrawlStatusTypes::Completed => {
|
||||||
|
break Ok(status_data);
|
||||||
|
}
|
||||||
|
CrawlStatusTypes::Scraping => {
|
||||||
|
tokio::time::sleep(tokio::time::Duration::from_millis(poll_interval)).await;
|
||||||
|
}
|
||||||
|
CrawlStatusTypes::Failed => {
|
||||||
|
break Err(FirecrawlError::CrawlJobFailed(format!(
|
||||||
|
"Crawl job failed."
|
||||||
|
), status_data));
|
||||||
|
}
|
||||||
|
CrawlStatusTypes::Cancelled => {
|
||||||
|
break Err(FirecrawlError::CrawlJobFailed(format!(
|
||||||
|
"Crawl job was cancelled."
|
||||||
|
), status_data));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
86
apps/rust-sdk/src/document.rs
Normal file
86
apps/rust-sdk/src/document.rs
Normal file
|
|
@ -0,0 +1,86 @@
|
||||||
|
use serde::{Deserialize, Serialize};
|
||||||
|
use serde_json::Value;
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct DocumentMetadata {
|
||||||
|
// firecrawl specific
|
||||||
|
#[serde(rename = "sourceURL")]
|
||||||
|
pub source_url: String,
|
||||||
|
pub status_code: u16,
|
||||||
|
pub error: Option<String>,
|
||||||
|
|
||||||
|
// basic meta tags
|
||||||
|
pub title: Option<String>,
|
||||||
|
pub description: Option<String>,
|
||||||
|
pub language: Option<String>,
|
||||||
|
pub keywords: Option<String>,
|
||||||
|
pub robots: Option<String>,
|
||||||
|
|
||||||
|
// og: namespace
|
||||||
|
pub og_title: Option<String>,
|
||||||
|
pub og_description: Option<String>,
|
||||||
|
pub og_url: Option<String>,
|
||||||
|
pub og_image: Option<String>,
|
||||||
|
pub og_audio: Option<String>,
|
||||||
|
pub og_determiner: Option<String>,
|
||||||
|
pub og_locale: Option<String>,
|
||||||
|
pub og_locale_alternate: Option<Vec<String>>,
|
||||||
|
pub og_site_name: Option<String>,
|
||||||
|
pub og_video: Option<String>,
|
||||||
|
|
||||||
|
// article: namespace
|
||||||
|
pub article_section: Option<String>,
|
||||||
|
pub article_tag: Option<String>,
|
||||||
|
pub published_time: Option<String>,
|
||||||
|
pub modified_time: Option<String>,
|
||||||
|
|
||||||
|
// dc./dcterms. namespace
|
||||||
|
pub dcterms_keywords: Option<String>,
|
||||||
|
pub dc_description: Option<String>,
|
||||||
|
pub dc_subject: Option<String>,
|
||||||
|
pub dcterms_subject: Option<String>,
|
||||||
|
pub dcterms_audience: Option<String>,
|
||||||
|
pub dc_type: Option<String>,
|
||||||
|
pub dcterms_type: Option<String>,
|
||||||
|
pub dc_date: Option<String>,
|
||||||
|
pub dc_date_created: Option<String>,
|
||||||
|
pub dcterms_created: Option<String>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default, Clone)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct Document {
|
||||||
|
/// A list of the links on the page, present if `ScrapeFormats::Markdown` is present in `ScrapeOptions.formats`. (default)
|
||||||
|
pub markdown: Option<String>,
|
||||||
|
|
||||||
|
/// The HTML of the page, present if `ScrapeFormats::HTML` is present in `ScrapeOptions.formats`.
|
||||||
|
///
|
||||||
|
/// This contains HTML that has non-content tags removed. If you need the original HTML, use `ScrapeFormats::RawHTML`.
|
||||||
|
pub html: Option<String>,
|
||||||
|
|
||||||
|
/// The raw HTML of the page, present if `ScrapeFormats::RawHTML` is present in `ScrapeOptions.formats`.
|
||||||
|
///
|
||||||
|
/// This contains the original, untouched HTML on the page. If you only need human-readable content, use `ScrapeFormats::HTML`.
|
||||||
|
pub raw_html: Option<String>,
|
||||||
|
|
||||||
|
/// The URL to the screenshot of the page, present if `ScrapeFormats::Screenshot` or `ScrapeFormats::ScreenshotFullPage` is present in `ScrapeOptions.formats`.
|
||||||
|
pub screenshot: Option<String>,
|
||||||
|
|
||||||
|
/// A list of the links on the page, present if `ScrapeFormats::Links` is present in `ScrapeOptions.formats`.
|
||||||
|
pub links: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// The extracted data from the page, present if `ScrapeFormats::Extract` is present in `ScrapeOptions.formats`.
|
||||||
|
/// If `ScrapeOptions.extract.schema` is `Some`, this `Value` is guaranteed to match the provided schema.
|
||||||
|
pub extract: Option<Value>,
|
||||||
|
|
||||||
|
/// The metadata from the page.
|
||||||
|
pub metadata: DocumentMetadata,
|
||||||
|
|
||||||
|
/// Can be present if `ScrapeFormats::Extract` is present in `ScrapeOptions.formats`.
|
||||||
|
/// The warning message will contain any errors encountered during the extraction.
|
||||||
|
pub warning: Option<String>,
|
||||||
|
}
|
||||||
|
|
||||||
45
apps/rust-sdk/src/error.rs
Normal file
45
apps/rust-sdk/src/error.rs
Normal file
|
|
@ -0,0 +1,45 @@
|
||||||
|
use std::fmt::Display;
|
||||||
|
|
||||||
|
use serde::{Deserialize, Serialize};
|
||||||
|
use serde_json::Value;
|
||||||
|
use thiserror::Error;
|
||||||
|
|
||||||
|
use crate::crawl::CrawlStatus;
|
||||||
|
|
||||||
|
#[derive(Debug, Deserialize, Serialize, Clone)]
|
||||||
|
pub struct FirecrawlAPIError {
|
||||||
|
/// Always false.
|
||||||
|
success: bool,
|
||||||
|
|
||||||
|
/// Error message
|
||||||
|
pub error: String,
|
||||||
|
|
||||||
|
/// Additional details of this error. Schema depends on the error itself.
|
||||||
|
pub details: Option<Value>,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl Display for FirecrawlAPIError {
|
||||||
|
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
|
||||||
|
if let Some(details) = self.details.as_ref() {
|
||||||
|
write!(f, "{} ({})", self.error, details)
|
||||||
|
} else {
|
||||||
|
write!(f, "{}", self.error)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Error, Debug)]
|
||||||
|
pub enum FirecrawlError {
|
||||||
|
#[error("{0} failed: HTTP error {1}: {2}")]
|
||||||
|
HttpRequestFailed(String, u16, String),
|
||||||
|
#[error("{0} failed: HTTP error: {1}")]
|
||||||
|
HttpError(String, reqwest::Error),
|
||||||
|
#[error("Failed to parse response as text: {0}")]
|
||||||
|
ResponseParseErrorText(reqwest::Error),
|
||||||
|
#[error("Failed to parse response: {0}")]
|
||||||
|
ResponseParseError(serde_json::Error),
|
||||||
|
#[error("{0} failed: {1}")]
|
||||||
|
APIError(String, FirecrawlAPIError),
|
||||||
|
#[error("Crawl job failed: {0}")]
|
||||||
|
CrawlJobFailed(String, CrawlStatus),
|
||||||
|
}
|
||||||
|
|
@ -1,373 +1,85 @@
|
||||||
/*
|
|
||||||
*
|
|
||||||
* - Structs and Enums:
|
|
||||||
* FirecrawlError: Custom error enum for handling various errors.
|
|
||||||
* FirecrawlApp: Main struct for the application, holding API key, URL, and HTTP client.
|
|
||||||
*
|
|
||||||
* - Initialization:
|
|
||||||
*
|
|
||||||
* FirecrawlApp::new initializes the struct, fetching the API key and URL from environment variables if not provided.
|
|
||||||
*
|
|
||||||
* - API Methods:
|
|
||||||
* scrape_url, search, crawl_url, check_crawl_status:
|
|
||||||
* Methods for interacting with the Firecrawl API, similar to the Python methods.
|
|
||||||
* monitor_job_status: Polls the API to monitor the status of a crawl job until completion.
|
|
||||||
*/
|
|
||||||
|
|
||||||
use std::env;
|
|
||||||
use std::thread;
|
|
||||||
use std::time::Duration;
|
|
||||||
|
|
||||||
use log::debug;
|
|
||||||
use reqwest::{Client, Response};
|
use reqwest::{Client, Response};
|
||||||
use serde_json::json;
|
use serde::de::DeserializeOwned;
|
||||||
use serde_json::Value;
|
use serde_json::Value;
|
||||||
use thiserror::Error;
|
|
||||||
|
|
||||||
#[derive(Error, Debug)]
|
pub mod crawl;
|
||||||
pub enum FirecrawlError {
|
pub mod document;
|
||||||
#[error("HTTP request failed: {0}")]
|
mod error;
|
||||||
HttpRequestFailed(String),
|
pub mod map;
|
||||||
#[error("API key not provided")]
|
pub mod scrape;
|
||||||
ApiKeyNotProvided,
|
|
||||||
#[error("Failed to parse response: {0}")]
|
pub use error::FirecrawlError;
|
||||||
ResponseParseError(String),
|
|
||||||
#[error("Crawl job failed or stopped: {0}")]
|
|
||||||
CrawlJobFailed(String),
|
|
||||||
}
|
|
||||||
|
|
||||||
#[derive(Clone, Debug)]
|
#[derive(Clone, Debug)]
|
||||||
pub struct FirecrawlApp {
|
pub struct FirecrawlApp {
|
||||||
api_key: String,
|
api_key: Option<String>,
|
||||||
api_url: String,
|
api_url: String,
|
||||||
client: Client,
|
client: Client,
|
||||||
}
|
}
|
||||||
// the api verstion of firecrawl
|
|
||||||
const API_VERSION: &str = "/v0";
|
pub(crate) const API_VERSION: &str = "/v1";
|
||||||
|
|
||||||
impl FirecrawlApp {
|
impl FirecrawlApp {
|
||||||
/// Initialize the FirecrawlApp instance.
|
pub fn new(api_key: impl AsRef<str>) -> Result<Self, FirecrawlError> {
|
||||||
///
|
FirecrawlApp::new_selfhosted("https://api.firecrawl.dev", Some(api_key))
|
||||||
/// # Arguments:
|
}
|
||||||
/// * `api_key` (Optional[str]): API key for authenticating with the Firecrawl API.
|
|
||||||
/// * `api_url` (Optional[str]): Base URL for the Firecrawl API.
|
|
||||||
pub fn new(api_key: Option<String>, api_url: Option<String>) -> Result<Self, FirecrawlError> {
|
|
||||||
let api_key = api_key
|
|
||||||
.or_else(|| env::var("FIRECRAWL_API_KEY").ok())
|
|
||||||
.ok_or(FirecrawlError::ApiKeyNotProvided)?;
|
|
||||||
let api_url = api_url.unwrap_or_else(|| {
|
|
||||||
env::var("FIRECRAWL_API_URL")
|
|
||||||
.unwrap_or_else(|_| "https://api.firecrawl.dev".to_string())
|
|
||||||
});
|
|
||||||
|
|
||||||
debug!("Initialized FirecrawlApp with API key: {}", api_key);
|
|
||||||
debug!("Initialized FirecrawlApp with API URL: {}", api_url);
|
|
||||||
|
|
||||||
|
pub fn new_selfhosted(api_url: impl AsRef<str>, api_key: Option<impl AsRef<str>>) -> Result<Self, FirecrawlError> {
|
||||||
Ok(FirecrawlApp {
|
Ok(FirecrawlApp {
|
||||||
api_key,
|
api_key: api_key.map(|x| x.as_ref().to_string()),
|
||||||
api_url,
|
api_url: api_url.as_ref().to_string(),
|
||||||
client: Client::new(),
|
client: Client::new(),
|
||||||
})
|
})
|
||||||
}
|
}
|
||||||
|
|
||||||
/// Scrape the specified URL using the Firecrawl API.
|
fn prepare_headers(&self, idempotency_key: Option<&String>) -> reqwest::header::HeaderMap {
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `url` (str): The URL to scrape.
|
|
||||||
/// * `params` (Optional[Dict[str, Any]]): Additional parameters for the scrape request.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// * `Any`: The scraped data if the request is successful.
|
|
||||||
///
|
|
||||||
/// # Raises:
|
|
||||||
/// * `Exception`: If the scrape request fails.
|
|
||||||
pub async fn scrape_url(
|
|
||||||
&self,
|
|
||||||
url: &str,
|
|
||||||
params: Option<Value>,
|
|
||||||
) -> Result<Value, FirecrawlError> {
|
|
||||||
let headers = self.prepare_headers(None);
|
|
||||||
let mut scrape_params = json!({"url": url});
|
|
||||||
|
|
||||||
if let Some(mut params) = params {
|
|
||||||
if let Some(extractor_options) = params.get_mut("extractorOptions") {
|
|
||||||
if let Some(extraction_schema) = extractor_options.get_mut("extractionSchema") {
|
|
||||||
if extraction_schema.is_object() && extraction_schema.get("schema").is_some() {
|
|
||||||
extractor_options["extractionSchema"] = extraction_schema["schema"].clone();
|
|
||||||
}
|
|
||||||
extractor_options["mode"] = extractor_options
|
|
||||||
.get("mode")
|
|
||||||
.cloned()
|
|
||||||
.unwrap_or_else(|| json!("llm-extraction"));
|
|
||||||
}
|
|
||||||
scrape_params["extractorOptions"] = extractor_options.clone();
|
|
||||||
}
|
|
||||||
for (key, value) in params.as_object().unwrap() {
|
|
||||||
if key != "extractorOptions" {
|
|
||||||
scrape_params[key] = value.clone();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
let response = self
|
|
||||||
.client
|
|
||||||
.post(&format!("{}{}/scrape", self.api_url, API_VERSION))
|
|
||||||
.headers(headers)
|
|
||||||
.json(&scrape_params)
|
|
||||||
.send()
|
|
||||||
.await
|
|
||||||
.map_err(|e| FirecrawlError::HttpRequestFailed(e.to_string()))?;
|
|
||||||
|
|
||||||
self.handle_response(response, "scrape URL").await
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Perform a search using the Firecrawl API.
|
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `query` (str): The search query.
|
|
||||||
/// * `params` (Optional[Dict[str, Any]]): Additional parameters for the search request.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// * `Any`: The search results if the request is successful.
|
|
||||||
///
|
|
||||||
/// # Raises:
|
|
||||||
/// * `Exception`: If the search request fails.
|
|
||||||
pub async fn search(
|
|
||||||
&self,
|
|
||||||
query: &str,
|
|
||||||
params: Option<Value>,
|
|
||||||
) -> Result<Value, FirecrawlError> {
|
|
||||||
let headers = self.prepare_headers(None);
|
|
||||||
let mut json_data = json!({"query": query});
|
|
||||||
if let Some(params) = params {
|
|
||||||
for (key, value) in params.as_object().unwrap() {
|
|
||||||
json_data[key] = value.clone();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
let response = self
|
|
||||||
.client
|
|
||||||
.post(&format!("{}{}/search", self.api_url, API_VERSION))
|
|
||||||
.headers(headers)
|
|
||||||
.json(&json_data)
|
|
||||||
.send()
|
|
||||||
.await
|
|
||||||
.map_err(|e| FirecrawlError::HttpRequestFailed(e.to_string()))?;
|
|
||||||
|
|
||||||
self.handle_response(response, "search").await
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Initiate a crawl job for the specified URL using the Firecrawl API.
|
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `url` (str): The URL to crawl.
|
|
||||||
/// * `params` (Optional[Dict[str, Any]]): Additional parameters for the crawl request.
|
|
||||||
/// * `wait_until_done` (bool): Whether to wait until the crawl job is completed.
|
|
||||||
/// * `poll_interval` (int): Time in seconds between status checks when waiting for job completion.
|
|
||||||
/// * `idempotency_key` (Optional[str]): A unique uuid key to ensure idempotency of requests.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// * `Any`: The crawl job ID or the crawl results if waiting until completion.
|
|
||||||
///
|
|
||||||
/// # `Raises`:
|
|
||||||
/// * `Exception`: If the crawl job initiation or monitoring fails.
|
|
||||||
pub async fn crawl_url(
|
|
||||||
&self,
|
|
||||||
url: &str,
|
|
||||||
params: Option<Value>,
|
|
||||||
wait_until_done: bool,
|
|
||||||
poll_interval: u64,
|
|
||||||
idempotency_key: Option<String>,
|
|
||||||
) -> Result<Value, FirecrawlError> {
|
|
||||||
let headers = self.prepare_headers(idempotency_key);
|
|
||||||
let mut json_data = json!({"url": url});
|
|
||||||
if let Some(params) = params {
|
|
||||||
for (key, value) in params.as_object().unwrap() {
|
|
||||||
json_data[key] = value.clone();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
let response = self
|
|
||||||
.client
|
|
||||||
.post(&format!("{}{}/crawl", self.api_url, API_VERSION))
|
|
||||||
.headers(headers.clone())
|
|
||||||
.json(&json_data)
|
|
||||||
.send()
|
|
||||||
.await
|
|
||||||
.map_err(|e| FirecrawlError::HttpRequestFailed(e.to_string()))?;
|
|
||||||
|
|
||||||
let response_json = self.handle_response(response, "start crawl job").await?;
|
|
||||||
let job_id = response_json["jobId"].as_str().unwrap().to_string();
|
|
||||||
|
|
||||||
if wait_until_done {
|
|
||||||
self.monitor_job_status(&job_id, headers, poll_interval)
|
|
||||||
.await
|
|
||||||
} else {
|
|
||||||
Ok(json!({"jobId": job_id}))
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Check the status of a crawl job using the Firecrawl API.
|
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `job_id` (str): The ID of the crawl job.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// * `Any`: The status of the crawl job.
|
|
||||||
///
|
|
||||||
/// # Raises:
|
|
||||||
/// * `Exception`: If the status check request fails.
|
|
||||||
pub async fn check_crawl_status(&self, job_id: &str) -> Result<Value, FirecrawlError> {
|
|
||||||
let headers = self.prepare_headers(None);
|
|
||||||
let response = self
|
|
||||||
.client
|
|
||||||
.get(&format!(
|
|
||||||
"{}{}/crawl/status/{}",
|
|
||||||
self.api_url, API_VERSION, job_id
|
|
||||||
))
|
|
||||||
.headers(headers)
|
|
||||||
.send()
|
|
||||||
.await
|
|
||||||
.map_err(|e| FirecrawlError::HttpRequestFailed(e.to_string()))?;
|
|
||||||
|
|
||||||
self.handle_response(response, "check crawl status").await
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Monitor the status of a crawl job until completion.
|
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `job_id` (str): The ID of the crawl job.
|
|
||||||
/// * `headers` (Dict[str, str]): The headers to include in the status check requests.
|
|
||||||
/// * `poll_interval` (int): Secounds between status checks.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// * `Any`: The crawl results if the job is completed successfully.
|
|
||||||
///
|
|
||||||
/// # Raises:
|
|
||||||
/// Exception: If the job fails or an error occurs during status checks.
|
|
||||||
async fn monitor_job_status(
|
|
||||||
&self,
|
|
||||||
job_id: &str,
|
|
||||||
headers: reqwest::header::HeaderMap,
|
|
||||||
poll_interval: u64,
|
|
||||||
) -> Result<Value, FirecrawlError> {
|
|
||||||
loop {
|
|
||||||
let response = self
|
|
||||||
.client
|
|
||||||
.get(&format!(
|
|
||||||
"{}{}/crawl/status/{}",
|
|
||||||
self.api_url, API_VERSION, job_id
|
|
||||||
))
|
|
||||||
.headers(headers.clone())
|
|
||||||
.send()
|
|
||||||
.await
|
|
||||||
.map_err(|e| FirecrawlError::HttpRequestFailed(e.to_string()))?;
|
|
||||||
|
|
||||||
let status_data = self.handle_response(response, "check crawl status").await?;
|
|
||||||
match status_data["status"].as_str() {
|
|
||||||
Some("completed") => {
|
|
||||||
if status_data["data"].is_object() {
|
|
||||||
return Ok(status_data["data"].clone());
|
|
||||||
} else {
|
|
||||||
return Err(FirecrawlError::CrawlJobFailed(
|
|
||||||
"Crawl job completed but no data was returned".to_string(),
|
|
||||||
));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
Some("active") | Some("paused") | Some("pending") | Some("queued")
|
|
||||||
| Some("waiting") => {
|
|
||||||
thread::sleep(Duration::from_secs(poll_interval));
|
|
||||||
}
|
|
||||||
Some(status) => {
|
|
||||||
return Err(FirecrawlError::CrawlJobFailed(format!(
|
|
||||||
"Crawl job failed or was stopped. Status: {}",
|
|
||||||
status
|
|
||||||
)));
|
|
||||||
}
|
|
||||||
None => {
|
|
||||||
return Err(FirecrawlError::CrawlJobFailed(
|
|
||||||
"Unexpected response: no status field".to_string(),
|
|
||||||
));
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
/// Prepare the headers for API requests.
|
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// `idempotency_key` (Optional[str]): A unique key to ensure idempotency of requests.
|
|
||||||
///
|
|
||||||
/// # Returns:
|
|
||||||
/// Dict[str, str]: The headers including content type, authorization, and optionally idempotency key.
|
|
||||||
fn prepare_headers(&self, idempotency_key: Option<String>) -> reqwest::header::HeaderMap {
|
|
||||||
let mut headers = reqwest::header::HeaderMap::new();
|
let mut headers = reqwest::header::HeaderMap::new();
|
||||||
headers.insert("Content-Type", "application/json".parse().unwrap());
|
headers.insert("Content-Type", "application/json".parse().unwrap());
|
||||||
headers.insert(
|
if let Some(api_key) = self.api_key.as_ref() {
|
||||||
"Authorization",
|
headers.insert(
|
||||||
format!("Bearer {}", self.api_key).parse().unwrap(),
|
"Authorization",
|
||||||
);
|
format!("Bearer {}", api_key).parse().unwrap(),
|
||||||
|
);
|
||||||
|
}
|
||||||
if let Some(key) = idempotency_key {
|
if let Some(key) = idempotency_key {
|
||||||
headers.insert("x-idempotency-key", key.parse().unwrap());
|
headers.insert("x-idempotency-key", key.parse().unwrap());
|
||||||
}
|
}
|
||||||
headers
|
headers
|
||||||
}
|
}
|
||||||
|
|
||||||
/// Handle errors from API responses.
|
async fn handle_response<'a, T: DeserializeOwned>(
|
||||||
///
|
|
||||||
/// # Arguments:
|
|
||||||
/// * `response` (requests.Response): The response object from the API request.
|
|
||||||
/// * `action` (str): Description of the action that was being performed.
|
|
||||||
///
|
|
||||||
/// # Raises:
|
|
||||||
/// Exception: An exception with a message containing the status code and error details from the response.
|
|
||||||
async fn handle_response(
|
|
||||||
&self,
|
&self,
|
||||||
response: Response,
|
response: Response,
|
||||||
action: &str,
|
action: impl AsRef<str>,
|
||||||
) -> Result<Value, FirecrawlError> {
|
) -> Result<T, FirecrawlError> {
|
||||||
if response.status().is_success() {
|
let (is_success, status) = (response.status().is_success(), response.status());
|
||||||
let response_json: Value = response
|
|
||||||
.json()
|
let response = response
|
||||||
.await
|
.text()
|
||||||
.map_err(|e| FirecrawlError::ResponseParseError(e.to_string()))?;
|
.await
|
||||||
if response_json["success"].as_bool().unwrap_or(false) {
|
.map_err(|e| FirecrawlError::ResponseParseErrorText(e))
|
||||||
Ok(response_json["data"].clone())
|
.and_then(|response_json| serde_json::from_str::<Value>(&response_json).map_err(|e| FirecrawlError::ResponseParseError(e)))
|
||||||
} else {
|
.and_then(|response_value| {
|
||||||
Err(FirecrawlError::HttpRequestFailed(format!(
|
if response_value["success"].as_bool().unwrap_or(false) {
|
||||||
"Failed to {}: {}",
|
Ok(serde_json::from_value::<T>(response_value).map_err(|e| FirecrawlError::ResponseParseError(e))?)
|
||||||
action, response_json["error"]
|
} else {
|
||||||
)))
|
Err(FirecrawlError::APIError(
|
||||||
}
|
action.as_ref().to_string(),
|
||||||
} else {
|
serde_json::from_value(response_value).map_err(|e| FirecrawlError::ResponseParseError(e))?
|
||||||
let status_code = response.status().as_u16();
|
))
|
||||||
let error_message = response
|
}
|
||||||
.json::<Value>()
|
});
|
||||||
.await
|
|
||||||
.unwrap_or_else(|_| json!({"error": "No additional error details provided."}));
|
match &response {
|
||||||
let message = match status_code {
|
Ok(_) => response,
|
||||||
402 => format!(
|
Err(FirecrawlError::ResponseParseError(_)) | Err(FirecrawlError::ResponseParseErrorText(_)) => {
|
||||||
"Payment Required: Failed to {}. {}",
|
if is_success {
|
||||||
action, error_message["error"]
|
response
|
||||||
),
|
} else {
|
||||||
408 => format!(
|
Err(FirecrawlError::HttpRequestFailed(action.as_ref().to_string(), status.as_u16(), status.as_str().to_string()))
|
||||||
"Request Timeout: Failed to {} as the request timed out. {}",
|
}
|
||||||
action, error_message["error"]
|
},
|
||||||
),
|
Err(_) => response,
|
||||||
409 => format!(
|
|
||||||
"Conflict: Failed to {} due to a conflict. {}",
|
|
||||||
action, error_message["error"]
|
|
||||||
),
|
|
||||||
500 => format!(
|
|
||||||
"Internal Server Error: Failed to {}. {}",
|
|
||||||
action, error_message["error"]
|
|
||||||
),
|
|
||||||
_ => format!(
|
|
||||||
"Unexpected error during {}: Status code {}. {}",
|
|
||||||
action, status_code, error_message["error"]
|
|
||||||
),
|
|
||||||
};
|
|
||||||
Err(FirecrawlError::HttpRequestFailed(message))
|
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
66
apps/rust-sdk/src/map.rs
Normal file
66
apps/rust-sdk/src/map.rs
Normal file
|
|
@ -0,0 +1,66 @@
|
||||||
|
use serde::{Deserialize, Serialize};
|
||||||
|
|
||||||
|
use crate::{FirecrawlApp, FirecrawlError, API_VERSION};
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct MapOptions {
|
||||||
|
/// Search query to use for mapping
|
||||||
|
pub search: Option<String>,
|
||||||
|
|
||||||
|
/// Ignore the website sitemap when crawling (default: `true`)
|
||||||
|
pub ignore_sitemap: Option<bool>,
|
||||||
|
|
||||||
|
/// Include subdomains of the website (default: `true`)
|
||||||
|
pub include_subdomains: Option<bool>,
|
||||||
|
|
||||||
|
/// Maximum number of links to return (default: `5000`)
|
||||||
|
pub exclude_tags: Option<u32>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct MapRequestBody {
|
||||||
|
url: String,
|
||||||
|
|
||||||
|
#[serde(flatten)]
|
||||||
|
options: MapOptions,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct MapResponse {
|
||||||
|
success: bool,
|
||||||
|
|
||||||
|
links: Vec<String>,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl FirecrawlApp {
|
||||||
|
/// Returns links from a URL using the Firecrawl API.
|
||||||
|
pub async fn map_url(
|
||||||
|
&self,
|
||||||
|
url: impl AsRef<str>,
|
||||||
|
options: impl Into<Option<MapOptions>>,
|
||||||
|
) -> Result<Vec<String>, FirecrawlError> {
|
||||||
|
let body = MapRequestBody {
|
||||||
|
url: url.as_ref().to_string(),
|
||||||
|
options: options.into().unwrap_or_default(),
|
||||||
|
};
|
||||||
|
|
||||||
|
let headers = self.prepare_headers(None);
|
||||||
|
|
||||||
|
let response = self
|
||||||
|
.client
|
||||||
|
.post(&format!("{}{}/map", self.api_url, API_VERSION))
|
||||||
|
.headers(headers)
|
||||||
|
.json(&body)
|
||||||
|
.send()
|
||||||
|
.await
|
||||||
|
.map_err(|e| FirecrawlError::HttpError(format!("Mapping {:?}", url.as_ref()), e))?;
|
||||||
|
|
||||||
|
let response = self.handle_response::<MapResponse>(response, "scrape URL").await?;
|
||||||
|
|
||||||
|
Ok(response.links)
|
||||||
|
}
|
||||||
|
}
|
||||||
138
apps/rust-sdk/src/scrape.rs
Normal file
138
apps/rust-sdk/src/scrape.rs
Normal file
|
|
@ -0,0 +1,138 @@
|
||||||
|
use std::collections::HashMap;
|
||||||
|
|
||||||
|
use serde::{Deserialize, Serialize};
|
||||||
|
use serde_json::Value;
|
||||||
|
|
||||||
|
use crate::{document::Document, FirecrawlApp, FirecrawlError, API_VERSION};
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Clone, Copy, Debug)]
|
||||||
|
pub enum ScrapeFormats {
|
||||||
|
/// Will result in a copy of the Markdown content of the page.
|
||||||
|
#[serde(rename = "markdown")]
|
||||||
|
Markdown,
|
||||||
|
|
||||||
|
/// Will result in a copy of the filtered, content-only HTML of the page.
|
||||||
|
#[serde(rename = "html")]
|
||||||
|
HTML,
|
||||||
|
|
||||||
|
/// Will result in a copy of the raw HTML of the page.
|
||||||
|
#[serde(rename = "rawHtml")]
|
||||||
|
RawHTML,
|
||||||
|
|
||||||
|
/// Will result in a Vec of URLs found on the page.
|
||||||
|
#[serde(rename = "links")]
|
||||||
|
Links,
|
||||||
|
|
||||||
|
/// Will result in a URL to a screenshot of the page.
|
||||||
|
///
|
||||||
|
/// Can not be used in conjunction with `ScrapeFormats::ScreenshotFullPage`.
|
||||||
|
#[serde(rename = "screenshot")]
|
||||||
|
Screenshot,
|
||||||
|
|
||||||
|
/// Will result in a URL to a full-page screenshot of the page.
|
||||||
|
///
|
||||||
|
/// Can not be used in conjunction with `ScrapeFormats::Screenshot`.
|
||||||
|
#[serde(rename = "screenshot@fullPage")]
|
||||||
|
ScreenshotFullPage,
|
||||||
|
|
||||||
|
/// Will result in the results of an LLM extraction.
|
||||||
|
///
|
||||||
|
/// See `ScrapeOptions.extract` for more options.
|
||||||
|
#[serde(rename = "extract")]
|
||||||
|
Extract,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct ExtractOptions {
|
||||||
|
/// Schema the output should adhere to, provided in JSON Schema format.
|
||||||
|
pub schema: Option<Value>,
|
||||||
|
|
||||||
|
pub system_prompt: Option<String>,
|
||||||
|
|
||||||
|
/// Extraction prompt to send to the LLM agent along with the page content.
|
||||||
|
pub prompt: Option<String>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[serde_with::skip_serializing_none]
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
pub struct ScrapeOptions {
|
||||||
|
/// Formats to extract from the page. (default: `[ Markdown ]`)
|
||||||
|
pub formats: Option<Vec<ScrapeFormats>>,
|
||||||
|
|
||||||
|
/// Only extract the main content of the page, excluding navigation and other miscellaneous content. (default: `true`)
|
||||||
|
pub only_main_content: Option<bool>,
|
||||||
|
|
||||||
|
/// HTML tags to exclusively include.
|
||||||
|
///
|
||||||
|
/// For example, if you pass `div`, you will only get content from `<div>`s and their children.
|
||||||
|
pub include_tags: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// HTML tags to exclude.
|
||||||
|
///
|
||||||
|
/// For example, if you pass `img`, you will never get image URLs in your results.
|
||||||
|
pub exclude_tags: Option<Vec<String>>,
|
||||||
|
|
||||||
|
/// Additional HTTP headers to use when loading the page.
|
||||||
|
pub headers: Option<HashMap<String, String>>,
|
||||||
|
|
||||||
|
// Amount of time to wait after loading the page, and before grabbing the content, in milliseconds. (default: `0`)
|
||||||
|
pub wait_for: Option<u32>,
|
||||||
|
|
||||||
|
// Timeout before returning an error, in milliseconds. (default: `60000`)
|
||||||
|
pub timeout: Option<u32>,
|
||||||
|
|
||||||
|
/// Extraction options, to be used in conjunction with `ScrapeFormats::Extract`.
|
||||||
|
pub extract: Option<ExtractOptions>,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct ScrapeRequestBody {
|
||||||
|
url: String,
|
||||||
|
|
||||||
|
#[serde(flatten)]
|
||||||
|
options: ScrapeOptions,
|
||||||
|
}
|
||||||
|
|
||||||
|
#[derive(Deserialize, Serialize, Debug, Default)]
|
||||||
|
#[serde(rename_all = "camelCase")]
|
||||||
|
struct ScrapeResponse {
|
||||||
|
/// This will always be `true` due to `FirecrawlApp::handle_response`.
|
||||||
|
/// No need to expose.
|
||||||
|
success: bool,
|
||||||
|
|
||||||
|
/// The resulting document.
|
||||||
|
data: Document,
|
||||||
|
}
|
||||||
|
|
||||||
|
impl FirecrawlApp {
|
||||||
|
/// Scrapes a URL using the Firecrawl API.
|
||||||
|
pub async fn scrape_url(
|
||||||
|
&self,
|
||||||
|
url: impl AsRef<str>,
|
||||||
|
options: impl Into<Option<ScrapeOptions>>,
|
||||||
|
) -> Result<Document, FirecrawlError> {
|
||||||
|
let body = ScrapeRequestBody {
|
||||||
|
url: url.as_ref().to_string(),
|
||||||
|
options: options.into().unwrap_or_default(),
|
||||||
|
};
|
||||||
|
|
||||||
|
let headers = self.prepare_headers(None);
|
||||||
|
|
||||||
|
let response = self
|
||||||
|
.client
|
||||||
|
.post(&format!("{}{}/scrape", self.api_url, API_VERSION))
|
||||||
|
.headers(headers)
|
||||||
|
.json(&body)
|
||||||
|
.send()
|
||||||
|
.await
|
||||||
|
.map_err(|e| FirecrawlError::HttpError(format!("Scraping {:?}", url.as_ref()), e))?;
|
||||||
|
|
||||||
|
let response = self.handle_response::<ScrapeResponse>(response, "scrape URL").await?;
|
||||||
|
|
||||||
|
Ok(response.data)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -1,24 +1,16 @@
|
||||||
use assert_matches::assert_matches;
|
use assert_matches::assert_matches;
|
||||||
use dotenv::dotenv;
|
use dotenvy::dotenv;
|
||||||
|
use firecrawl::scrape::{ExtractOptions, ScrapeFormats, ScrapeOptions};
|
||||||
use firecrawl::FirecrawlApp;
|
use firecrawl::FirecrawlApp;
|
||||||
use serde_json::json;
|
use serde_json::json;
|
||||||
use std::env;
|
use std::env;
|
||||||
use std::time::Duration;
|
|
||||||
use tokio::time::sleep;
|
|
||||||
|
|
||||||
#[tokio::test]
|
|
||||||
async fn test_no_api_key() {
|
|
||||||
dotenv().ok();
|
|
||||||
let api_url = env::var("API_URL").expect("API_URL environment variable is not set");
|
|
||||||
assert_matches!(FirecrawlApp::new(None, Some(api_url)), Err(e) if e.to_string() == "API key not provided");
|
|
||||||
}
|
|
||||||
|
|
||||||
#[tokio::test]
|
#[tokio::test]
|
||||||
async fn test_blocklisted_url() {
|
async fn test_blocklisted_url() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let blocklisted_url = "https://facebook.com/fake-test";
|
let blocklisted_url = "https://facebook.com/fake-test";
|
||||||
let result = app.scrape_url(blocklisted_url, None).await;
|
let result = app.scrape_url(blocklisted_url, None).await;
|
||||||
|
|
||||||
|
|
@ -32,74 +24,65 @@ async fn test_blocklisted_url() {
|
||||||
async fn test_successful_response_with_valid_preview_token() {
|
async fn test_successful_response_with_valid_preview_token() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let app = FirecrawlApp::new(
|
let app = FirecrawlApp::new_selfhosted(
|
||||||
Some("this_is_just_a_preview_token".to_string()),
|
api_url,
|
||||||
Some(api_url),
|
Some("this_is_just_a_preview_token"),
|
||||||
)
|
)
|
||||||
.unwrap();
|
.unwrap();
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://roastmywebsite.ai", None)
|
.scrape_url("https://roastmywebsite.ai", None)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
assert!(result.as_object().unwrap().contains_key("content"));
|
assert!(result.markdown.is_some());
|
||||||
assert!(result["content"].as_str().unwrap().contains("_Roast_"));
|
assert!(result.markdown.unwrap().contains("_Roast_"));
|
||||||
}
|
}
|
||||||
|
|
||||||
#[tokio::test]
|
#[tokio::test]
|
||||||
async fn test_scrape_url_e2e() {
|
async fn test_scrape_url_e2e() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://roastmywebsite.ai", None)
|
.scrape_url("https://roastmywebsite.ai", None)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
assert!(result.as_object().unwrap().contains_key("content"));
|
assert!(result.markdown.is_some());
|
||||||
assert!(result.as_object().unwrap().contains_key("markdown"));
|
assert!(result.markdown.unwrap().contains("_Roast_"));
|
||||||
assert!(result.as_object().unwrap().contains_key("metadata"));
|
|
||||||
assert!(!result.as_object().unwrap().contains_key("html"));
|
|
||||||
assert!(result["content"].as_str().unwrap().contains("_Roast_"));
|
|
||||||
}
|
}
|
||||||
|
|
||||||
#[tokio::test]
|
#[tokio::test]
|
||||||
async fn test_successful_response_with_valid_api_key_and_include_html() {
|
async fn test_successful_response_with_valid_api_key_and_include_html() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let params = json!({
|
let params = ScrapeOptions {
|
||||||
"pageOptions": {
|
formats: vec! [ ScrapeFormats::Markdown, ScrapeFormats::HTML ].into(),
|
||||||
"includeHtml": true
|
..Default::default()
|
||||||
}
|
};
|
||||||
});
|
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://roastmywebsite.ai", Some(params))
|
.scrape_url("https://roastmywebsite.ai", params)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
assert!(result.as_object().unwrap().contains_key("content"));
|
assert!(result.markdown.is_some());
|
||||||
assert!(result.as_object().unwrap().contains_key("markdown"));
|
assert!(result.html.is_some());
|
||||||
assert!(result.as_object().unwrap().contains_key("html"));
|
assert!(result.markdown.unwrap().contains("_Roast_"));
|
||||||
assert!(result.as_object().unwrap().contains_key("metadata"));
|
assert!(result.html.unwrap().contains("<h1"));
|
||||||
assert!(result["content"].as_str().unwrap().contains("_Roast_"));
|
|
||||||
assert!(result["markdown"].as_str().unwrap().contains("_Roast_"));
|
|
||||||
assert!(result["html"].as_str().unwrap().contains("<h1"));
|
|
||||||
}
|
}
|
||||||
|
|
||||||
#[tokio::test]
|
#[tokio::test]
|
||||||
async fn test_successful_response_for_valid_scrape_with_pdf_file() {
|
async fn test_successful_response_for_valid_scrape_with_pdf_file() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://arxiv.org/pdf/astro-ph/9301001.pdf", None)
|
.scrape_url("https://arxiv.org/pdf/astro-ph/9301001.pdf", None)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
assert!(result.as_object().unwrap().contains_key("content"));
|
assert!(result.markdown.is_some());
|
||||||
assert!(result.as_object().unwrap().contains_key("metadata"));
|
assert!(result.markdown
|
||||||
assert!(result["content"]
|
|
||||||
.as_str()
|
|
||||||
.unwrap()
|
.unwrap()
|
||||||
.contains("We present spectrophotometric observations of the Broad Line Radio Galaxy"));
|
.contains("We present spectrophotometric observations of the Broad Line Radio Galaxy"));
|
||||||
}
|
}
|
||||||
|
|
@ -108,17 +91,14 @@ async fn test_successful_response_for_valid_scrape_with_pdf_file() {
|
||||||
async fn test_successful_response_for_valid_scrape_with_pdf_file_without_explicit_extension() {
|
async fn test_successful_response_for_valid_scrape_with_pdf_file_without_explicit_extension() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://arxiv.org/pdf/astro-ph/9301001", None)
|
.scrape_url("https://arxiv.org/pdf/astro-ph/9301001", None)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
sleep(Duration::from_secs(6)).await; // wait for 6 seconds
|
assert!(result.markdown.is_some());
|
||||||
assert!(result.as_object().unwrap().contains_key("content"));
|
assert!(result.markdown
|
||||||
assert!(result.as_object().unwrap().contains_key("metadata"));
|
|
||||||
assert!(result["content"]
|
|
||||||
.as_str()
|
|
||||||
.unwrap()
|
.unwrap()
|
||||||
.contains("We present spectrophotometric observations of the Broad Line Radio Galaxy"));
|
.contains("We present spectrophotometric observations of the Broad Line Radio Galaxy"));
|
||||||
}
|
}
|
||||||
|
|
@ -127,10 +107,10 @@ async fn test_successful_response_for_valid_scrape_with_pdf_file_without_explici
|
||||||
async fn test_should_return_error_for_blocklisted_url() {
|
async fn test_should_return_error_for_blocklisted_url() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let blocklisted_url = "https://twitter.com/fake-test";
|
let blocklisted_url = "https://twitter.com/fake-test";
|
||||||
let result = app.crawl_url(blocklisted_url, None, true, 1, None).await;
|
let result = app.crawl_url(blocklisted_url, None).await;
|
||||||
|
|
||||||
assert_matches!(
|
assert_matches!(
|
||||||
result,
|
result,
|
||||||
|
|
@ -142,13 +122,13 @@ async fn test_should_return_error_for_blocklisted_url() {
|
||||||
async fn test_llm_extraction() {
|
async fn test_llm_extraction() {
|
||||||
dotenv().ok();
|
dotenv().ok();
|
||||||
let api_url = env::var("API_URL").unwrap();
|
let api_url = env::var("API_URL").unwrap();
|
||||||
let api_key = env::var("TEST_API_KEY").unwrap();
|
let api_key = env::var("TEST_API_KEY").ok();
|
||||||
let app = FirecrawlApp::new(Some(api_key), Some(api_url)).unwrap();
|
let app = FirecrawlApp::new_selfhosted(api_url, api_key).unwrap();
|
||||||
let params = json!({
|
let options = ScrapeOptions {
|
||||||
"extractorOptions": {
|
formats: vec! [ ScrapeFormats::Extract ].into(),
|
||||||
"mode": "llm-extraction",
|
extract: ExtractOptions {
|
||||||
"extractionPrompt": "Based on the information on the page, find what the company's mission is and whether it supports SSO, and whether it is open source",
|
prompt: "Based on the information on the page, find what the company's mission is and whether it supports SSO, and whether it is open source".to_string().into(),
|
||||||
"extractionSchema": {
|
schema: json!({
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
"company_mission": {"type": "string"},
|
"company_mission": {"type": "string"},
|
||||||
|
|
@ -156,15 +136,17 @@ async fn test_llm_extraction() {
|
||||||
"is_open_source": {"type": "boolean"}
|
"is_open_source": {"type": "boolean"}
|
||||||
},
|
},
|
||||||
"required": ["company_mission", "supports_sso", "is_open_source"]
|
"required": ["company_mission", "supports_sso", "is_open_source"]
|
||||||
}
|
}).into(),
|
||||||
}
|
..Default::default()
|
||||||
});
|
}.into(),
|
||||||
|
..Default::default()
|
||||||
|
};
|
||||||
let result = app
|
let result = app
|
||||||
.scrape_url("https://mendable.ai", Some(params))
|
.scrape_url("https://mendable.ai", options)
|
||||||
.await
|
.await
|
||||||
.unwrap();
|
.unwrap();
|
||||||
assert!(result.as_object().unwrap().contains_key("llm_extraction"));
|
assert!(result.extract.is_some());
|
||||||
let llm_extraction = &result["llm_extraction"];
|
let llm_extraction = &result.extract.unwrap();
|
||||||
assert!(llm_extraction
|
assert!(llm_extraction
|
||||||
.as_object()
|
.as_object()
|
||||||
.unwrap()
|
.unwrap()
|
||||||
|
|
|
||||||
|
|
@ -1,6 +1,14 @@
|
||||||
# Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
# Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
||||||
# Before installing
|
# Before installing
|
||||||
1. Set [secret.yaml](secret.yaml) and [configmap.yaml](configmap.yaml) and do not check in secrets
|
1. Set [secret.yaml](secret.yaml) and [configmap.yaml](configmap.yaml) and do not check in secrets
|
||||||
|
- **Note**: If `REDIS_PASSWORD` is configured in the secret, please modify the ConfigMap to reflect the following format for `REDIS_URL` and `REDIS_RATE_LIMIT_URL`:
|
||||||
|
```yaml
|
||||||
|
REDIS_URL: "redis://:password@host:port"
|
||||||
|
REDIS_RATE_LIMIT_URL: "redis://:password@host:port"
|
||||||
|
```
|
||||||
|
Replace `password`, `host`, and `port` with the appropriate values.
|
||||||
|
|
||||||
|
|
||||||
2. Build Docker images, and host it in your Docker Registry (replace the target registry with your own)
|
2. Build Docker images, and host it in your Docker Registry (replace the target registry with your own)
|
||||||
1. API (which is also used as a worker image)
|
1. API (which is also used as a worker image)
|
||||||
1. ```bash
|
1. ```bash
|
||||||
|
|
@ -38,4 +46,4 @@ kubectl delete -f playwright-service.yaml
|
||||||
kubectl delete -f api.yaml
|
kubectl delete -f api.yaml
|
||||||
kubectl delete -f worker.yaml
|
kubectl delete -f worker.yaml
|
||||||
kubectl delete -f redis.yaml
|
kubectl delete -f redis.yaml
|
||||||
```
|
```
|
||||||
|
|
|
||||||
|
|
@ -15,7 +15,22 @@ spec:
|
||||||
containers:
|
containers:
|
||||||
- name: redis
|
- name: redis
|
||||||
image: redis:alpine
|
image: redis:alpine
|
||||||
args: ["redis-server", "--bind", "0.0.0.0"]
|
command: [ "/bin/sh", "-c" ] # Run a shell script as entrypoint
|
||||||
|
args:
|
||||||
|
- |
|
||||||
|
if [ -n "$REDIS_PASSWORD" ]; then
|
||||||
|
echo "Starting Redis with authentication"
|
||||||
|
exec redis-server --bind 0.0.0.0 --requirepass "$REDIS_PASSWORD"
|
||||||
|
else
|
||||||
|
echo "Starting Redis without authentication"
|
||||||
|
exec redis-server --bind 0.0.0.0
|
||||||
|
fi
|
||||||
|
env:
|
||||||
|
- name: REDIS_PASSWORD
|
||||||
|
valueFrom:
|
||||||
|
secretKeyRef:
|
||||||
|
name: firecrawl-secret
|
||||||
|
key: REDIS_PASSWORD
|
||||||
---
|
---
|
||||||
apiVersion: v1
|
apiVersion: v1
|
||||||
kind: Service
|
kind: Service
|
||||||
|
|
|
||||||
|
|
@ -17,3 +17,4 @@ data:
|
||||||
STRIPE_PRICE_ID_SCALE: ""
|
STRIPE_PRICE_ID_SCALE: ""
|
||||||
HYPERDX_API_KEY: ""
|
HYPERDX_API_KEY: ""
|
||||||
FIRE_ENGINE_BETA_URL: ""
|
FIRE_ENGINE_BETA_URL: ""
|
||||||
|
REDIS_PASSWORD: ""
|
||||||
|
|
|
||||||
BIN
img/open-source-cloud.png
Normal file
BIN
img/open-source-cloud.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 194 KiB |
Loading…
Reference in New Issue
Block a user