mirror of
https://github.com/mendableai/firecrawl.git
synced 2024-11-16 11:42:24 +08:00
Merge branch 'main' into nsc/usage-based-overuse
This commit is contained in:
commit
5d55ef3f4d
2
.github/ISSUE_TEMPLATE/bug_report.md
vendored
2
.github/ISSUE_TEMPLATE/bug_report.md
vendored
|
|
@ -1,7 +1,7 @@
|
||||||
---
|
---
|
||||||
name: Bug report
|
name: Bug report
|
||||||
about: Create a report to help us improve
|
about: Create a report to help us improve
|
||||||
title: "[BUG]"
|
title: "[Bug] "
|
||||||
labels: bug
|
labels: bug
|
||||||
assignees: ''
|
assignees: ''
|
||||||
|
|
||||||
|
|
|
||||||
2
.github/ISSUE_TEMPLATE/feature_request.md
vendored
2
.github/ISSUE_TEMPLATE/feature_request.md
vendored
|
|
@ -1,7 +1,7 @@
|
||||||
---
|
---
|
||||||
name: Feature request
|
name: Feature request
|
||||||
about: Suggest an idea for this project
|
about: Suggest an idea for this project
|
||||||
title: "[Feat]"
|
title: "[Feat] "
|
||||||
labels: ''
|
labels: ''
|
||||||
assignees: ''
|
assignees: ''
|
||||||
|
|
||||||
|
|
|
||||||
40
.github/ISSUE_TEMPLATE/self_host_issue.md
vendored
Normal file
40
.github/ISSUE_TEMPLATE/self_host_issue.md
vendored
Normal file
|
|
@ -0,0 +1,40 @@
|
||||||
|
---
|
||||||
|
name: Self-host issue
|
||||||
|
about: Report an issue with self-hosting Firecrawl
|
||||||
|
title: "[Self-Host] "
|
||||||
|
labels: self-host
|
||||||
|
assignees: ''
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
**Describe the Issue**
|
||||||
|
Provide a clear and concise description of the self-hosting issue you're experiencing.
|
||||||
|
|
||||||
|
**To Reproduce**
|
||||||
|
Steps to reproduce the issue:
|
||||||
|
1. Configure the environment or settings with '...'
|
||||||
|
2. Run the command '...'
|
||||||
|
3. Observe the error or unexpected output at '...'
|
||||||
|
4. Log output/error message
|
||||||
|
|
||||||
|
**Expected Behavior**
|
||||||
|
A clear and concise description of what you expected to happen when self-hosting.
|
||||||
|
|
||||||
|
**Screenshots**
|
||||||
|
If applicable, add screenshots or copies of the command line output to help explain the self-hosting issue.
|
||||||
|
|
||||||
|
**Environment (please complete the following information):**
|
||||||
|
- OS: [e.g. macOS, Linux, Windows]
|
||||||
|
- Firecrawl Version: [e.g. 1.2.3]
|
||||||
|
- Node.js Version: [e.g. 14.x]
|
||||||
|
- Docker Version (if applicable): [e.g. 20.10.14]
|
||||||
|
- Database Type and Version: [e.g. PostgreSQL 13.4]
|
||||||
|
|
||||||
|
**Logs**
|
||||||
|
If applicable, include detailed logs to help understand the self-hosting problem.
|
||||||
|
|
||||||
|
**Configuration**
|
||||||
|
Provide relevant parts of your configuration files (with sensitive information redacted).
|
||||||
|
|
||||||
|
**Additional Context**
|
||||||
|
Add any other context about the self-hosting issue here, such as specific infrastructure details, network setup, or any modifications made to the original Firecrawl setup.
|
||||||
42
.github/archive/publish-rust-sdk.yml
vendored
Normal file
42
.github/archive/publish-rust-sdk.yml
vendored
Normal file
|
|
@ -0,0 +1,42 @@
|
||||||
|
name: Publish Rust SDK
|
||||||
|
|
||||||
|
on: []
|
||||||
|
|
||||||
|
env:
|
||||||
|
CRATES_IO_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
build-and-publish:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- name: Checkout repository
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
|
||||||
|
- name: Set up Rust
|
||||||
|
uses: actions-rs/toolchain@v1
|
||||||
|
with:
|
||||||
|
toolchain: stable
|
||||||
|
default: true
|
||||||
|
profile: minimal
|
||||||
|
|
||||||
|
- name: Install dependencies
|
||||||
|
run: cargo build --release
|
||||||
|
|
||||||
|
- name: Run version check script
|
||||||
|
id: version_check_script
|
||||||
|
run: |
|
||||||
|
VERSION_INCREMENTED=$(cargo search --limit 1 my_crate_name | grep my_crate_name)
|
||||||
|
echo "VERSION_INCREMENTED=$VERSION_INCREMENTED" >> $GITHUB_ENV
|
||||||
|
|
||||||
|
- name: Build the package
|
||||||
|
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
||||||
|
run: cargo package
|
||||||
|
working-directory: ./apps/rust-sdk
|
||||||
|
|
||||||
|
- name: Publish to crates.io
|
||||||
|
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
||||||
|
env:
|
||||||
|
CARGO_REG_TOKEN: ${{ secrets.CRATES_IO_TOKEN }}
|
||||||
|
run: cargo publish
|
||||||
|
working-directory: ./apps/rust-sdk
|
||||||
61
.github/archive/rust-sdk.yml
vendored
Normal file
61
.github/archive/rust-sdk.yml
vendored
Normal file
|
|
@ -0,0 +1,61 @@
|
||||||
|
name: Run Rust SDK E2E Tests
|
||||||
|
|
||||||
|
on: []
|
||||||
|
|
||||||
|
env:
|
||||||
|
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
||||||
|
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
||||||
|
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
|
||||||
|
HOST: ${{ secrets.HOST }}
|
||||||
|
LLAMAPARSE_API_KEY: ${{ secrets.LLAMAPARSE_API_KEY }}
|
||||||
|
LOGTAIL_KEY: ${{ secrets.LOGTAIL_KEY }}
|
||||||
|
POSTHOG_API_KEY: ${{ secrets.POSTHOG_API_KEY }}
|
||||||
|
POSTHOG_HOST: ${{ secrets.POSTHOG_HOST }}
|
||||||
|
NUM_WORKERS_PER_QUEUE: ${{ secrets.NUM_WORKERS_PER_QUEUE }}
|
||||||
|
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
||||||
|
PLAYWRIGHT_MICROSERVICE_URL: ${{ secrets.PLAYWRIGHT_MICROSERVICE_URL }}
|
||||||
|
PORT: ${{ secrets.PORT }}
|
||||||
|
REDIS_URL: ${{ secrets.REDIS_URL }}
|
||||||
|
SCRAPING_BEE_API_KEY: ${{ secrets.SCRAPING_BEE_API_KEY }}
|
||||||
|
SUPABASE_ANON_TOKEN: ${{ secrets.SUPABASE_ANON_TOKEN }}
|
||||||
|
SUPABASE_SERVICE_TOKEN: ${{ secrets.SUPABASE_SERVICE_TOKEN }}
|
||||||
|
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
|
||||||
|
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
||||||
|
HYPERDX_API_KEY: ${{ secrets.HYPERDX_API_KEY }}
|
||||||
|
HDX_NODE_BETA_MODE: 1
|
||||||
|
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
build:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
services:
|
||||||
|
redis:
|
||||||
|
image: redis
|
||||||
|
ports:
|
||||||
|
- 6379:6379
|
||||||
|
|
||||||
|
steps:
|
||||||
|
- name: Checkout repository
|
||||||
|
uses: actions/checkout@v3
|
||||||
|
- name: Install pnpm
|
||||||
|
run: npm install -g pnpm
|
||||||
|
- name: Install dependencies for API
|
||||||
|
run: pnpm install
|
||||||
|
working-directory: ./apps/api
|
||||||
|
- name: Start the application
|
||||||
|
run: npm start &
|
||||||
|
working-directory: ./apps/api
|
||||||
|
id: start_app
|
||||||
|
- name: Start workers
|
||||||
|
run: npm run workers &
|
||||||
|
working-directory: ./apps/api
|
||||||
|
id: start_workers
|
||||||
|
- name: Set up Rust
|
||||||
|
uses: actions/setup-rust@v1
|
||||||
|
with:
|
||||||
|
rust-version: stable
|
||||||
|
- name: Try the lib build
|
||||||
|
working-directory: ./apps/rust-sdk
|
||||||
|
run: cargo build
|
||||||
|
- name: Run E2E tests for Rust SDK
|
||||||
|
run: cargo test --test e2e_with_auth
|
||||||
45
.github/dependabot.yml
vendored
Normal file
45
.github/dependabot.yml
vendored
Normal file
|
|
@ -0,0 +1,45 @@
|
||||||
|
version: 2
|
||||||
|
updates:
|
||||||
|
# playwright-service
|
||||||
|
- package-ecosystem: "pip"
|
||||||
|
directory: "/apps/playwright-service"
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
|
open-pull-requests-limit: 0 # Disable version updates
|
||||||
|
security-updates: "all"
|
||||||
|
commit-message:
|
||||||
|
prefix: "apps/playwright-service"
|
||||||
|
include: "scope"
|
||||||
|
|
||||||
|
# python-sdk
|
||||||
|
- package-ecosystem: "pip"
|
||||||
|
directory: "/apps/python-sdk"
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
|
open-pull-requests-limit: 0 # Disable version updates
|
||||||
|
security-updates: "all"
|
||||||
|
commit-message:
|
||||||
|
prefix: "apps/python-sdk"
|
||||||
|
include: "scope"
|
||||||
|
|
||||||
|
# api
|
||||||
|
- package-ecosystem: "npm"
|
||||||
|
directory: "/apps/api"
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
|
open-pull-requests-limit: 0 # Disable version updates
|
||||||
|
security-updates: "all"
|
||||||
|
commit-message:
|
||||||
|
prefix: "apps/api"
|
||||||
|
include: "scope"
|
||||||
|
|
||||||
|
# test-suite
|
||||||
|
- package-ecosystem: "npm"
|
||||||
|
directory: "/apps/test-suite"
|
||||||
|
schedule:
|
||||||
|
interval: "weekly"
|
||||||
|
open-pull-requests-limit: 0 # Disable version updates
|
||||||
|
security-updates: "all"
|
||||||
|
commit-message:
|
||||||
|
prefix: "apps/test-suite"
|
||||||
|
include: "scope"
|
||||||
20
.github/scripts/check_version_has_incremented.py
vendored
20
.github/scripts/check_version_has_incremented.py
vendored
|
|
@ -15,6 +15,7 @@ false
|
||||||
|
|
||||||
"""
|
"""
|
||||||
import json
|
import json
|
||||||
|
import toml
|
||||||
import os
|
import os
|
||||||
import re
|
import re
|
||||||
import sys
|
import sys
|
||||||
|
|
@ -53,6 +54,19 @@ def get_npm_version(package_name: str) -> str:
|
||||||
version = response.json()['version']
|
version = response.json()['version']
|
||||||
return version.strip()
|
return version.strip()
|
||||||
|
|
||||||
|
def get_rust_version(file_path: str) -> str:
|
||||||
|
"""Extract version string from Cargo.toml."""
|
||||||
|
cargo_toml = toml.load(file_path)
|
||||||
|
if 'package' in cargo_toml and 'version' in cargo_toml['package']:
|
||||||
|
return cargo_toml['package']['version'].strip()
|
||||||
|
raise RuntimeError("Unable to find version string in Cargo.toml.")
|
||||||
|
|
||||||
|
def get_crates_version(package_name: str) -> str:
|
||||||
|
"""Get latest version of Rust package from crates.io."""
|
||||||
|
response = requests.get(f"https://crates.io/api/v1/crates/{package_name}")
|
||||||
|
version = response.json()['crate']['newest_version']
|
||||||
|
return version.strip()
|
||||||
|
|
||||||
def is_version_incremented(local_version: str, published_version: str) -> bool:
|
def is_version_incremented(local_version: str, published_version: str) -> bool:
|
||||||
"""Compare local and published versions."""
|
"""Compare local and published versions."""
|
||||||
local_version_parsed: Version = parse_version(local_version)
|
local_version_parsed: Version = parse_version(local_version)
|
||||||
|
|
@ -74,6 +88,12 @@ if __name__ == "__main__":
|
||||||
current_version = get_js_version(os.path.join(package_path, 'package.json'))
|
current_version = get_js_version(os.path.join(package_path, 'package.json'))
|
||||||
# Get published version from npm
|
# Get published version from npm
|
||||||
published_version = get_npm_version(package_name)
|
published_version = get_npm_version(package_name)
|
||||||
|
if package_type == "rust":
|
||||||
|
# Get current version from Cargo.toml
|
||||||
|
current_version = get_rust_version(os.path.join(package_path, 'Cargo.toml'))
|
||||||
|
# Get published version from crates.io
|
||||||
|
published_version = get_crates_version(package_name)
|
||||||
|
|
||||||
else:
|
else:
|
||||||
raise ValueError("Invalid package type. Use 'python' or 'js'.")
|
raise ValueError("Invalid package type. Use 'python' or 'js'.")
|
||||||
|
|
||||||
|
|
|
||||||
1
.github/scripts/requirements.txt
vendored
1
.github/scripts/requirements.txt
vendored
|
|
@ -1,2 +1,3 @@
|
||||||
requests
|
requests
|
||||||
packaging
|
packaging
|
||||||
|
toml
|
||||||
4
.github/workflows/ci.yml
vendored
4
.github/workflows/ci.yml
vendored
|
|
@ -27,7 +27,9 @@ env:
|
||||||
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
||||||
HYPERDX_API_KEY: ${{ secrets.HYPERDX_API_KEY }}
|
HYPERDX_API_KEY: ${{ secrets.HYPERDX_API_KEY }}
|
||||||
HDX_NODE_BETA_MODE: 1
|
HDX_NODE_BETA_MODE: 1
|
||||||
|
FIRE_ENGINE_BETA_URL: ${{ secrets.FIRE_ENGINE_BETA_URL }}
|
||||||
|
USE_DB_AUTHENTICATION: ${{ secrets.USE_DB_AUTHENTICATION }}
|
||||||
|
ENV: ${{ secrets.ENV }}
|
||||||
|
|
||||||
jobs:
|
jobs:
|
||||||
pre-deploy:
|
pre-deploy:
|
||||||
|
|
|
||||||
|
|
@ -1,7 +1,7 @@
|
||||||
name: Clean Before 24h Completed Jobs
|
name: Clean Every 30 Minutes Before 24h Completed Jobs
|
||||||
on:
|
on:
|
||||||
schedule:
|
schedule:
|
||||||
- cron: '0 0 * * *'
|
- cron: '30 * * * *'
|
||||||
|
|
||||||
env:
|
env:
|
||||||
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
||||||
|
|
@ -12,7 +12,7 @@ jobs:
|
||||||
steps:
|
steps:
|
||||||
- name: Send GET request to clean jobs
|
- name: Send GET request to clean jobs
|
||||||
run: |
|
run: |
|
||||||
response=$(curl --write-out '%{http_code}' --silent --output /dev/null https://api.firecrawl.dev/admin/${{ secrets.BULL_AUTH_KEY }}/clean-before-24h-complete-jobs)
|
response=$(curl --write-out '%{http_code}' --silent --output /dev/null --max-time 180 https://api.firecrawl.dev/admin/${{ secrets.BULL_AUTH_KEY }}/clean-before-24h-complete-jobs)
|
||||||
if [ "$response" -ne 200 ]; then
|
if [ "$response" -ne 200 ]; then
|
||||||
echo "Failed to clean jobs. Response: $response"
|
echo "Failed to clean jobs. Response: $response"
|
||||||
exit 1
|
exit 1
|
||||||
|
|
|
||||||
32
.github/workflows/deploy-image.yml
vendored
Normal file
32
.github/workflows/deploy-image.yml
vendored
Normal file
|
|
@ -0,0 +1,32 @@
|
||||||
|
name: Deploy Images to GHCR
|
||||||
|
|
||||||
|
env:
|
||||||
|
DOTNET_VERSION: '6.0.x'
|
||||||
|
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches:
|
||||||
|
- main
|
||||||
|
workflow_dispatch:
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
push-app-image:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
defaults:
|
||||||
|
run:
|
||||||
|
working-directory: './apps/api'
|
||||||
|
steps:
|
||||||
|
- name: 'Checkout GitHub Action'
|
||||||
|
uses: actions/checkout@main
|
||||||
|
|
||||||
|
- name: 'Login to GitHub Container Registry'
|
||||||
|
uses: docker/login-action@v1
|
||||||
|
with:
|
||||||
|
registry: ghcr.io
|
||||||
|
username: ${{github.actor}}
|
||||||
|
password: ${{secrets.GITHUB_TOKEN}}
|
||||||
|
|
||||||
|
- name: 'Build Inventory Image'
|
||||||
|
run: |
|
||||||
|
docker build . --tag ghcr.io/mendableai/firecrawl:latest
|
||||||
|
docker push ghcr.io/mendableai/firecrawl:latest
|
||||||
37
.github/workflows/fly-direct.yml
vendored
37
.github/workflows/fly-direct.yml
vendored
|
|
@ -1,37 +0,0 @@
|
||||||
name: Fly Deploy Direct
|
|
||||||
on:
|
|
||||||
schedule:
|
|
||||||
- cron: '0 * * * *'
|
|
||||||
|
|
||||||
env:
|
|
||||||
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
|
||||||
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
|
||||||
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
|
|
||||||
HOST: ${{ secrets.HOST }}
|
|
||||||
LLAMAPARSE_API_KEY: ${{ secrets.LLAMAPARSE_API_KEY }}
|
|
||||||
LOGTAIL_KEY: ${{ secrets.LOGTAIL_KEY }}
|
|
||||||
POSTHOG_API_KEY: ${{ secrets.POSTHOG_API_KEY }}
|
|
||||||
POSTHOG_HOST: ${{ secrets.POSTHOG_HOST }}
|
|
||||||
NUM_WORKERS_PER_QUEUE: ${{ secrets.NUM_WORKERS_PER_QUEUE }}
|
|
||||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
|
||||||
PLAYWRIGHT_MICROSERVICE_URL: ${{ secrets.PLAYWRIGHT_MICROSERVICE_URL }}
|
|
||||||
PORT: ${{ secrets.PORT }}
|
|
||||||
REDIS_URL: ${{ secrets.REDIS_URL }}
|
|
||||||
SCRAPING_BEE_API_KEY: ${{ secrets.SCRAPING_BEE_API_KEY }}
|
|
||||||
SUPABASE_ANON_TOKEN: ${{ secrets.SUPABASE_ANON_TOKEN }}
|
|
||||||
SUPABASE_SERVICE_TOKEN: ${{ secrets.SUPABASE_SERVICE_TOKEN }}
|
|
||||||
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
|
|
||||||
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
deploy:
|
|
||||||
name: Deploy app
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Change directory
|
|
||||||
run: cd apps/api
|
|
||||||
- uses: superfly/flyctl-actions/setup-flyctl@master
|
|
||||||
- run: flyctl deploy ./apps/api --remote-only -a firecrawl-scraper-js
|
|
||||||
env:
|
|
||||||
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
|
|
||||||
265
.github/workflows/fly.yml
vendored
265
.github/workflows/fly.yml
vendored
|
|
@ -1,265 +0,0 @@
|
||||||
name: Fly Deploy
|
|
||||||
on:
|
|
||||||
push:
|
|
||||||
branches:
|
|
||||||
- main
|
|
||||||
|
|
||||||
env:
|
|
||||||
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
|
||||||
BULL_AUTH_KEY: ${{ secrets.BULL_AUTH_KEY }}
|
|
||||||
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
|
|
||||||
HOST: ${{ secrets.HOST }}
|
|
||||||
LLAMAPARSE_API_KEY: ${{ secrets.LLAMAPARSE_API_KEY }}
|
|
||||||
LOGTAIL_KEY: ${{ secrets.LOGTAIL_KEY }}
|
|
||||||
POSTHOG_API_KEY: ${{ secrets.POSTHOG_API_KEY }}
|
|
||||||
POSTHOG_HOST: ${{ secrets.POSTHOG_HOST }}
|
|
||||||
NUM_WORKERS_PER_QUEUE: ${{ secrets.NUM_WORKERS_PER_QUEUE }}
|
|
||||||
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
|
|
||||||
PLAYWRIGHT_MICROSERVICE_URL: ${{ secrets.PLAYWRIGHT_MICROSERVICE_URL }}
|
|
||||||
PORT: ${{ secrets.PORT }}
|
|
||||||
REDIS_URL: ${{ secrets.REDIS_URL }}
|
|
||||||
SCRAPING_BEE_API_KEY: ${{ secrets.SCRAPING_BEE_API_KEY }}
|
|
||||||
SUPABASE_ANON_TOKEN: ${{ secrets.SUPABASE_ANON_TOKEN }}
|
|
||||||
SUPABASE_SERVICE_TOKEN: ${{ secrets.SUPABASE_SERVICE_TOKEN }}
|
|
||||||
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
|
|
||||||
TEST_API_KEY: ${{ secrets.TEST_API_KEY }}
|
|
||||||
PYPI_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
|
||||||
PYPI_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
|
||||||
NPM_TOKEN: ${{ secrets.NPM_TOKEN }}
|
|
||||||
|
|
||||||
jobs:
|
|
||||||
pre-deploy-e2e-tests:
|
|
||||||
name: Pre-deploy checks
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: "20"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Run E2E tests
|
|
||||||
run: |
|
|
||||||
npm run test:prod
|
|
||||||
working-directory: ./apps/api
|
|
||||||
|
|
||||||
pre-deploy-test-suite:
|
|
||||||
name: Test Suite
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: "20"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/test-suite
|
|
||||||
- name: Run E2E tests
|
|
||||||
run: |
|
|
||||||
npm run test
|
|
||||||
working-directory: ./apps/test-suite
|
|
||||||
|
|
||||||
python-sdk-tests:
|
|
||||||
name: Python SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Python
|
|
||||||
uses: actions/setup-python@v4
|
|
||||||
with:
|
|
||||||
python-version: '3.x'
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install Python dependencies
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install -r requirements.txt
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
- name: Run E2E tests for Python SDK
|
|
||||||
run: |
|
|
||||||
pytest firecrawl/__tests__/e2e_withAuth/test.py
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
js-sdk-tests:
|
|
||||||
name: JavaScript SDK Tests
|
|
||||||
needs: pre-deploy-e2e-tests
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
services:
|
|
||||||
redis:
|
|
||||||
image: redis
|
|
||||||
ports:
|
|
||||||
- 6379:6379
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: "20"
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
- name: Install dependencies
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/api
|
|
||||||
- name: Start the application
|
|
||||||
run: npm start &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_app
|
|
||||||
- name: Start workers
|
|
||||||
run: npm run workers &
|
|
||||||
working-directory: ./apps/api
|
|
||||||
id: start_workers
|
|
||||||
- name: Install dependencies for JavaScript SDK
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
- name: Run E2E tests for JavaScript SDK
|
|
||||||
run: npm run test
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
|
|
||||||
deploy:
|
|
||||||
name: Deploy app
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: [pre-deploy-test-suite, python-sdk-tests, js-sdk-tests]
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Change directory
|
|
||||||
run: cd apps/api
|
|
||||||
- uses: superfly/flyctl-actions/setup-flyctl@master
|
|
||||||
- run: flyctl deploy ./apps/api --remote-only -a firecrawl-scraper-js
|
|
||||||
env:
|
|
||||||
FLY_API_TOKEN: ${{ secrets.FLY_API_TOKEN }}
|
|
||||||
|
|
||||||
build-and-publish-python-sdk:
|
|
||||||
name: Build and publish Python SDK
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: deploy
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- name: Checkout repository
|
|
||||||
uses: actions/checkout@v3
|
|
||||||
|
|
||||||
- name: Set up Python
|
|
||||||
uses: actions/setup-python@v4
|
|
||||||
with:
|
|
||||||
python-version: '3.x'
|
|
||||||
|
|
||||||
- name: Install dependencies
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install setuptools wheel twine build requests packaging
|
|
||||||
|
|
||||||
- name: Run version check script
|
|
||||||
id: version_check_script
|
|
||||||
run: |
|
|
||||||
PYTHON_SDK_VERSION_INCREMENTED=$(python .github/scripts/check_version_has_incremented.py python ./apps/python-sdk/firecrawl firecrawl-py)
|
|
||||||
echo "PYTHON_SDK_VERSION_INCREMENTED=$PYTHON_SDK_VERSION_INCREMENTED" >> $GITHUB_ENV
|
|
||||||
|
|
||||||
- name: Build the package
|
|
||||||
if: ${{ env.PYTHON_SDK_VERSION_INCREMENTED == 'true' }}
|
|
||||||
run: |
|
|
||||||
python -m build
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
- name: Publish to PyPI
|
|
||||||
if: ${{ env.PYTHON_SDK_VERSION_INCREMENTED == 'true' }}
|
|
||||||
env:
|
|
||||||
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
|
||||||
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
|
||||||
run: |
|
|
||||||
twine upload dist/*
|
|
||||||
working-directory: ./apps/python-sdk
|
|
||||||
|
|
||||||
build-and-publish-js-sdk:
|
|
||||||
name: Build and publish JavaScript SDK
|
|
||||||
runs-on: ubuntu-latest
|
|
||||||
needs: deploy
|
|
||||||
|
|
||||||
steps:
|
|
||||||
- uses: actions/checkout@v3
|
|
||||||
- name: Set up Node.js
|
|
||||||
uses: actions/setup-node@v3
|
|
||||||
with:
|
|
||||||
node-version: '20'
|
|
||||||
registry-url: 'https://registry.npmjs.org/'
|
|
||||||
scope: '@mendable'
|
|
||||||
always-auth: true
|
|
||||||
|
|
||||||
- name: Install pnpm
|
|
||||||
run: npm install -g pnpm
|
|
||||||
|
|
||||||
- name: Install python for running version check script
|
|
||||||
run: |
|
|
||||||
python -m pip install --upgrade pip
|
|
||||||
pip install setuptools wheel requests packaging
|
|
||||||
|
|
||||||
- name: Install dependencies for JavaScript SDK
|
|
||||||
run: pnpm install
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
|
|
||||||
- name: Run version check script
|
|
||||||
id: version_check_script
|
|
||||||
run: |
|
|
||||||
VERSION_INCREMENTED=$(python .github/scripts/check_version_has_incremented.py js ./apps/js-sdk/firecrawl @mendable/firecrawl-js)
|
|
||||||
echo "VERSION_INCREMENTED=$VERSION_INCREMENTED" >> $GITHUB_ENV
|
|
||||||
|
|
||||||
- name: Build and publish to npm
|
|
||||||
if: ${{ env.VERSION_INCREMENTED == 'true' }}
|
|
||||||
env:
|
|
||||||
NODE_AUTH_TOKEN: ${{ secrets.NPM_TOKEN }}
|
|
||||||
run: |
|
|
||||||
npm run build-and-publish
|
|
||||||
working-directory: ./apps/js-sdk/firecrawl
|
|
||||||
|
|
||||||
16
.gitignore
vendored
16
.gitignore
vendored
|
|
@ -14,3 +14,19 @@ apps/test-suite/node_modules/
|
||||||
|
|
||||||
apps/test-suite/.env
|
apps/test-suite/.env
|
||||||
apps/test-suite/logs
|
apps/test-suite/logs
|
||||||
|
apps/test-suite/load-test-results/test-run-report.json
|
||||||
|
|
||||||
|
apps/playwright-service-ts/node_modules/
|
||||||
|
apps/playwright-service-ts/package-lock.json
|
||||||
|
|
||||||
|
|
||||||
|
/examples/o1_web_crawler/venv
|
||||||
|
*.pyc
|
||||||
|
.rdb
|
||||||
|
|
||||||
|
apps/js-sdk/firecrawl/dist
|
||||||
|
|
||||||
|
/examples/o1_web_crawler/firecrawl_env
|
||||||
|
/examples/crm_lead_enrichment/crm_lead_enrichment_env
|
||||||
|
/.venv
|
||||||
|
/examples/claude_web_crawler/firecrawl_env
|
||||||
|
|
|
||||||
6
.gitmodules
vendored
Normal file
6
.gitmodules
vendored
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
[submodule "apps/go-sdk/firecrawl-go"]
|
||||||
|
path = apps/go-sdk/firecrawl-go
|
||||||
|
url = https://github.com/mendableai/firecrawl-go
|
||||||
|
[submodule "apps/go-sdk/firecrawl-go-examples"]
|
||||||
|
path = apps/go-sdk/firecrawl-go-examples
|
||||||
|
url = https://github.com/mendableai/firecrawl-go-examples
|
||||||
5
.vscode/settings.json
vendored
Normal file
5
.vscode/settings.json
vendored
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
{
|
||||||
|
"rust-analyzer.linkedProjects": [
|
||||||
|
"apps/rust-sdk/Cargo.toml"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -12,7 +12,7 @@ First, start by installing dependencies
|
||||||
2. pnpm [instructions](https://pnpm.io/installation)
|
2. pnpm [instructions](https://pnpm.io/installation)
|
||||||
3. redis [instructions](https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/)
|
3. redis [instructions](https://redis.io/docs/latest/operate/oss_and_stack/install/install-redis/)
|
||||||
|
|
||||||
Set environment variables in a .env in the /apps/api/ directoryyou can copy over the template in .env.example.
|
Set environment variables in a .env in the /apps/api/ directory you can copy over the template in .env.example.
|
||||||
|
|
||||||
To start, we wont set up authentication, or any optional sub services (pdf parsing, JS blocking support, AI features )
|
To start, we wont set up authentication, or any optional sub services (pdf parsing, JS blocking support, AI features )
|
||||||
|
|
||||||
|
|
@ -24,6 +24,7 @@ NUM_WORKERS_PER_QUEUE=8
|
||||||
PORT=3002
|
PORT=3002
|
||||||
HOST=0.0.0.0
|
HOST=0.0.0.0
|
||||||
REDIS_URL=redis://localhost:6379
|
REDIS_URL=redis://localhost:6379
|
||||||
|
REDIS_RATE_LIMIT_URL=redis://localhost:6379
|
||||||
|
|
||||||
## To turn on DB authentication, you need to set up supabase.
|
## To turn on DB authentication, you need to set up supabase.
|
||||||
USE_DB_AUTHENTICATION=false
|
USE_DB_AUTHENTICATION=false
|
||||||
|
|
@ -43,7 +44,6 @@ BULL_AUTH_KEY= @
|
||||||
LOGTAIL_KEY= # Use if you're configuring basic logging with logtail
|
LOGTAIL_KEY= # Use if you're configuring basic logging with logtail
|
||||||
PLAYWRIGHT_MICROSERVICE_URL= # set if you'd like to run a playwright fallback
|
PLAYWRIGHT_MICROSERVICE_URL= # set if you'd like to run a playwright fallback
|
||||||
LLAMAPARSE_API_KEY= #Set if you have a llamaparse key you'd like to use to parse pdfs
|
LLAMAPARSE_API_KEY= #Set if you have a llamaparse key you'd like to use to parse pdfs
|
||||||
SERPER_API_KEY= #Set if you have a serper key you'd like to use as a search api
|
|
||||||
SLACK_WEBHOOK_URL= # set if you'd like to send slack server health status messages
|
SLACK_WEBHOOK_URL= # set if you'd like to send slack server health status messages
|
||||||
POSTHOG_API_KEY= # set if you'd like to send posthog events like job logs
|
POSTHOG_API_KEY= # set if you'd like to send posthog events like job logs
|
||||||
POSTHOG_HOST= # set if you'd like to send posthog events like job logs
|
POSTHOG_HOST= # set if you'd like to send posthog events like job logs
|
||||||
|
|
@ -103,7 +103,7 @@ This should return the response Hello, world!
|
||||||
If you’d like to test the crawl endpoint, you can run this
|
If you’d like to test the crawl endpoint, you can run this
|
||||||
|
|
||||||
```curl
|
```curl
|
||||||
curl -X POST http://localhost:3002/v0/crawl \
|
curl -X POST http://localhost:3002/v1/crawl \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://mendable.ai"
|
||||||
|
|
|
||||||
209
LICENSE
209
LICENSE
|
|
@ -1,35 +1,35 @@
|
||||||
GNU AFFERO GENERAL PUBLIC LICENSE
|
GNU AFFERO GENERAL PUBLIC LICENSE
|
||||||
Version 3, 19 November 2007
|
Version 3, 19 November 2007
|
||||||
|
|
||||||
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
||||||
Everyone is permitted to copy and distribute verbatim copies
|
Everyone is permitted to copy and distribute verbatim copies
|
||||||
of this license document, but changing it is not allowed.
|
of this license document, but changing it is not allowed.
|
||||||
|
|
||||||
Preamble
|
Preamble
|
||||||
|
|
||||||
The GNU Affero General Public License is a free, copyleft license for
|
The GNU Affero General Public License is a free, copyleft license for
|
||||||
software and other kinds of works, specifically designed to ensure
|
software and other kinds of works, specifically designed to ensure
|
||||||
cooperation with the community in the case of network server software.
|
cooperation with the community in the case of network server software.
|
||||||
|
|
||||||
The licenses for most software and other practical works are designed
|
The licenses for most software and other practical works are designed
|
||||||
to take away your freedom to share and change the works. By contrast,
|
to take away your freedom to share and change the works. By contrast,
|
||||||
our General Public Licenses are intended to guarantee your freedom to
|
our General Public Licenses are intended to guarantee your freedom to
|
||||||
share and change all versions of a program--to make sure it remains free
|
share and change all versions of a program--to make sure it remains free
|
||||||
software for all its users.
|
software for all its users.
|
||||||
|
|
||||||
When we speak of free software, we are referring to freedom, not
|
When we speak of free software, we are referring to freedom, not
|
||||||
price. Our General Public Licenses are designed to make sure that you
|
price. Our General Public Licenses are designed to make sure that you
|
||||||
have the freedom to distribute copies of free software (and charge for
|
have the freedom to distribute copies of free software (and charge for
|
||||||
them if you wish), that you receive source code or can get it if you
|
them if you wish), that you receive source code or can get it if you
|
||||||
want it, that you can change the software or use pieces of it in new
|
want it, that you can change the software or use pieces of it in new
|
||||||
free programs, and that you know you can do these things.
|
free programs, and that you know you can do these things.
|
||||||
|
|
||||||
Developers that use our General Public Licenses protect your rights
|
Developers that use our General Public Licenses protect your rights
|
||||||
with two steps: (1) assert copyright on the software, and (2) offer
|
with two steps: (1) assert copyright on the software, and (2) offer
|
||||||
you this License which gives you legal permission to copy, distribute
|
you this License which gives you legal permission to copy, distribute
|
||||||
and/or modify the software.
|
and/or modify the software.
|
||||||
|
|
||||||
A secondary benefit of defending all users' freedom is that
|
A secondary benefit of defending all users' freedom is that
|
||||||
improvements made in alternate versions of the program, if they
|
improvements made in alternate versions of the program, if they
|
||||||
receive widespread use, become available for other developers to
|
receive widespread use, become available for other developers to
|
||||||
incorporate. Many developers of free software are heartened and
|
incorporate. Many developers of free software are heartened and
|
||||||
|
|
@ -39,7 +39,7 @@ The GNU General Public License permits making a modified version and
|
||||||
letting the public access it on a server without ever releasing its
|
letting the public access it on a server without ever releasing its
|
||||||
source code to the public.
|
source code to the public.
|
||||||
|
|
||||||
The GNU Affero General Public License is designed specifically to
|
The GNU Affero General Public License is designed specifically to
|
||||||
ensure that, in such cases, the modified source code becomes available
|
ensure that, in such cases, the modified source code becomes available
|
||||||
to the community. It requires the operator of a network server to
|
to the community. It requires the operator of a network server to
|
||||||
provide the source code of the modified version running there to the
|
provide the source code of the modified version running there to the
|
||||||
|
|
@ -47,48 +47,48 @@ users of that server. Therefore, public use of a modified version, on
|
||||||
a publicly accessible server, gives the public access to the source
|
a publicly accessible server, gives the public access to the source
|
||||||
code of the modified version.
|
code of the modified version.
|
||||||
|
|
||||||
An older license, called the Affero General Public License and
|
An older license, called the Affero General Public License and
|
||||||
published by Affero, was designed to accomplish similar goals. This is
|
published by Affero, was designed to accomplish similar goals. This is
|
||||||
a different license, not a version of the Affero GPL, but Affero has
|
a different license, not a version of the Affero GPL, but Affero has
|
||||||
released a new version of the Affero GPL which permits relicensing under
|
released a new version of the Affero GPL which permits relicensing under
|
||||||
this license.
|
this license.
|
||||||
|
|
||||||
The precise terms and conditions for copying, distribution and
|
The precise terms and conditions for copying, distribution and
|
||||||
modification follow.
|
modification follow.
|
||||||
|
|
||||||
TERMS AND CONDITIONS
|
TERMS AND CONDITIONS
|
||||||
|
|
||||||
0. Definitions.
|
0. Definitions.
|
||||||
|
|
||||||
"This License" refers to version 3 of the GNU Affero General Public License.
|
"This License" refers to version 3 of the GNU Affero General Public License.
|
||||||
|
|
||||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||||
works, such as semiconductor masks.
|
works, such as semiconductor masks.
|
||||||
|
|
||||||
"The Program" refers to any copyrightable work licensed under this
|
"The Program" refers to any copyrightable work licensed under this
|
||||||
License. Each licensee is addressed as "you". "Licensees" and
|
License. Each licensee is addressed as "you". "Licensees" and
|
||||||
"recipients" may be individuals or organizations.
|
"recipients" may be individuals or organizations.
|
||||||
|
|
||||||
To "modify" a work means to copy from or adapt all or part of the work
|
To "modify" a work means to copy from or adapt all or part of the work
|
||||||
in a fashion requiring copyright permission, other than the making of an
|
in a fashion requiring copyright permission, other than the making of an
|
||||||
exact copy. The resulting work is called a "modified version" of the
|
exact copy. The resulting work is called a "modified version" of the
|
||||||
earlier work or a work "based on" the earlier work.
|
earlier work or a work "based on" the earlier work.
|
||||||
|
|
||||||
A "covered work" means either the unmodified Program or a work based
|
A "covered work" means either the unmodified Program or a work based
|
||||||
on the Program.
|
on the Program.
|
||||||
|
|
||||||
To "propagate" a work means to do anything with it that, without
|
To "propagate" a work means to do anything with it that, without
|
||||||
permission, would make you directly or secondarily liable for
|
permission, would make you directly or secondarily liable for
|
||||||
infringement under applicable copyright law, except executing it on a
|
infringement under applicable copyright law, except executing it on a
|
||||||
computer or modifying a private copy. Propagation includes copying,
|
computer or modifying a private copy. Propagation includes copying,
|
||||||
distribution (with or without modification), making available to the
|
distribution (with or without modification), making available to the
|
||||||
public, and in some countries other activities as well.
|
public, and in some countries other activities as well.
|
||||||
|
|
||||||
To "convey" a work means any kind of propagation that enables other
|
To "convey" a work means any kind of propagation that enables other
|
||||||
parties to make or receive copies. Mere interaction with a user through
|
parties to make or receive copies. Mere interaction with a user through
|
||||||
a computer network, with no transfer of a copy, is not conveying.
|
a computer network, with no transfer of a copy, is not conveying.
|
||||||
|
|
||||||
An interactive user interface displays "Appropriate Legal Notices"
|
An interactive user interface displays "Appropriate Legal Notices"
|
||||||
to the extent that it includes a convenient and prominently visible
|
to the extent that it includes a convenient and prominently visible
|
||||||
feature that (1) displays an appropriate copyright notice, and (2)
|
feature that (1) displays an appropriate copyright notice, and (2)
|
||||||
tells the user that there is no warranty for the work (except to the
|
tells the user that there is no warranty for the work (except to the
|
||||||
|
|
@ -97,18 +97,18 @@ work under this License, and how to view a copy of this License. If
|
||||||
the interface presents a list of user commands or options, such as a
|
the interface presents a list of user commands or options, such as a
|
||||||
menu, a prominent item in the list meets this criterion.
|
menu, a prominent item in the list meets this criterion.
|
||||||
|
|
||||||
1. Source Code.
|
1. Source Code.
|
||||||
|
|
||||||
The "source code" for a work means the preferred form of the work
|
The "source code" for a work means the preferred form of the work
|
||||||
for making modifications to it. "Object code" means any non-source
|
for making modifications to it. "Object code" means any non-source
|
||||||
form of a work.
|
form of a work.
|
||||||
|
|
||||||
A "Standard Interface" means an interface that either is an official
|
A "Standard Interface" means an interface that either is an official
|
||||||
standard defined by a recognized standards body, or, in the case of
|
standard defined by a recognized standards body, or, in the case of
|
||||||
interfaces specified for a particular programming language, one that
|
interfaces specified for a particular programming language, one that
|
||||||
is widely used among developers working in that language.
|
is widely used among developers working in that language.
|
||||||
|
|
||||||
The "System Libraries" of an executable work include anything, other
|
The "System Libraries" of an executable work include anything, other
|
||||||
than the work as a whole, that (a) is included in the normal form of
|
than the work as a whole, that (a) is included in the normal form of
|
||||||
packaging a Major Component, but which is not part of that Major
|
packaging a Major Component, but which is not part of that Major
|
||||||
Component, and (b) serves only to enable use of the work with that
|
Component, and (b) serves only to enable use of the work with that
|
||||||
|
|
@ -119,7 +119,7 @@ implementation is available to the public in source code form. A
|
||||||
(if any) on which the executable work runs, or a compiler used to
|
(if any) on which the executable work runs, or a compiler used to
|
||||||
produce the work, or an object code interpreter used to run it.
|
produce the work, or an object code interpreter used to run it.
|
||||||
|
|
||||||
The "Corresponding Source" for a work in object code form means all
|
The "Corresponding Source" for a work in object code form means all
|
||||||
the source code needed to generate, install, and (for an executable
|
the source code needed to generate, install, and (for an executable
|
||||||
work) run the object code and to modify the work, including scripts to
|
work) run the object code and to modify the work, including scripts to
|
||||||
control those activities. However, it does not include the work's
|
control those activities. However, it does not include the work's
|
||||||
|
|
@ -132,16 +132,16 @@ linked subprograms that the work is specifically designed to require,
|
||||||
such as by intimate data communication or control flow between those
|
such as by intimate data communication or control flow between those
|
||||||
subprograms and other parts of the work.
|
subprograms and other parts of the work.
|
||||||
|
|
||||||
The Corresponding Source need not include anything that users
|
The Corresponding Source need not include anything that users
|
||||||
can regenerate automatically from other parts of the Corresponding
|
can regenerate automatically from other parts of the Corresponding
|
||||||
Source.
|
Source.
|
||||||
|
|
||||||
The Corresponding Source for a work in source code form is that
|
The Corresponding Source for a work in source code form is that
|
||||||
same work.
|
same work.
|
||||||
|
|
||||||
2. Basic Permissions.
|
2. Basic Permissions.
|
||||||
|
|
||||||
All rights granted under this License are granted for the term of
|
All rights granted under this License are granted for the term of
|
||||||
copyright on the Program, and are irrevocable provided the stated
|
copyright on the Program, and are irrevocable provided the stated
|
||||||
conditions are met. This License explicitly affirms your unlimited
|
conditions are met. This License explicitly affirms your unlimited
|
||||||
permission to run the unmodified Program. The output from running a
|
permission to run the unmodified Program. The output from running a
|
||||||
|
|
@ -149,7 +149,7 @@ covered work is covered by this License only if the output, given its
|
||||||
content, constitutes a covered work. This License acknowledges your
|
content, constitutes a covered work. This License acknowledges your
|
||||||
rights of fair use or other equivalent, as provided by copyright law.
|
rights of fair use or other equivalent, as provided by copyright law.
|
||||||
|
|
||||||
You may make, run and propagate covered works that you do not
|
You may make, run and propagate covered works that you do not
|
||||||
convey, without conditions so long as your license otherwise remains
|
convey, without conditions so long as your license otherwise remains
|
||||||
in force. You may convey covered works to others for the sole purpose
|
in force. You may convey covered works to others for the sole purpose
|
||||||
of having them make modifications exclusively for you, or provide you
|
of having them make modifications exclusively for you, or provide you
|
||||||
|
|
@ -160,19 +160,19 @@ for you must do so exclusively on your behalf, under your direction
|
||||||
and control, on terms that prohibit them from making any copies of
|
and control, on terms that prohibit them from making any copies of
|
||||||
your copyrighted material outside their relationship with you.
|
your copyrighted material outside their relationship with you.
|
||||||
|
|
||||||
Conveying under any other circumstances is permitted solely under
|
Conveying under any other circumstances is permitted solely under
|
||||||
the conditions stated below. Sublicensing is not allowed; section 10
|
the conditions stated below. Sublicensing is not allowed; section 10
|
||||||
makes it unnecessary.
|
makes it unnecessary.
|
||||||
|
|
||||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||||
|
|
||||||
No covered work shall be deemed part of an effective technological
|
No covered work shall be deemed part of an effective technological
|
||||||
measure under any applicable law fulfilling obligations under article
|
measure under any applicable law fulfilling obligations under article
|
||||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||||
similar laws prohibiting or restricting circumvention of such
|
similar laws prohibiting or restricting circumvention of such
|
||||||
measures.
|
measures.
|
||||||
|
|
||||||
When you convey a covered work, you waive any legal power to forbid
|
When you convey a covered work, you waive any legal power to forbid
|
||||||
circumvention of technological measures to the extent such circumvention
|
circumvention of technological measures to the extent such circumvention
|
||||||
is effected by exercising rights under this License with respect to
|
is effected by exercising rights under this License with respect to
|
||||||
the covered work, and you disclaim any intention to limit operation or
|
the covered work, and you disclaim any intention to limit operation or
|
||||||
|
|
@ -180,9 +180,9 @@ modification of the work as a means of enforcing, against the work's
|
||||||
users, your or third parties' legal rights to forbid circumvention of
|
users, your or third parties' legal rights to forbid circumvention of
|
||||||
technological measures.
|
technological measures.
|
||||||
|
|
||||||
4. Conveying Verbatim Copies.
|
4. Conveying Verbatim Copies.
|
||||||
|
|
||||||
You may convey verbatim copies of the Program's source code as you
|
You may convey verbatim copies of the Program's source code as you
|
||||||
receive it, in any medium, provided that you conspicuously and
|
receive it, in any medium, provided that you conspicuously and
|
||||||
appropriately publish on each copy an appropriate copyright notice;
|
appropriately publish on each copy an appropriate copyright notice;
|
||||||
keep intact all notices stating that this License and any
|
keep intact all notices stating that this License and any
|
||||||
|
|
@ -190,12 +190,12 @@ non-permissive terms added in accord with section 7 apply to the code;
|
||||||
keep intact all notices of the absence of any warranty; and give all
|
keep intact all notices of the absence of any warranty; and give all
|
||||||
recipients a copy of this License along with the Program.
|
recipients a copy of this License along with the Program.
|
||||||
|
|
||||||
You may charge any price or no price for each copy that you convey,
|
You may charge any price or no price for each copy that you convey,
|
||||||
and you may offer support or warranty protection for a fee.
|
and you may offer support or warranty protection for a fee.
|
||||||
|
|
||||||
5. Conveying Modified Source Versions.
|
5. Conveying Modified Source Versions.
|
||||||
|
|
||||||
You may convey a work based on the Program, or the modifications to
|
You may convey a work based on the Program, or the modifications to
|
||||||
produce it from the Program, in the form of source code under the
|
produce it from the Program, in the form of source code under the
|
||||||
terms of section 4, provided that you also meet all of these conditions:
|
terms of section 4, provided that you also meet all of these conditions:
|
||||||
|
|
||||||
|
|
@ -220,7 +220,7 @@ terms of section 4, provided that you also meet all of these conditions:
|
||||||
interfaces that do not display Appropriate Legal Notices, your
|
interfaces that do not display Appropriate Legal Notices, your
|
||||||
work need not make them do so.
|
work need not make them do so.
|
||||||
|
|
||||||
A compilation of a covered work with other separate and independent
|
A compilation of a covered work with other separate and independent
|
||||||
works, which are not by their nature extensions of the covered work,
|
works, which are not by their nature extensions of the covered work,
|
||||||
and which are not combined with it such as to form a larger program,
|
and which are not combined with it such as to form a larger program,
|
||||||
in or on a volume of a storage or distribution medium, is called an
|
in or on a volume of a storage or distribution medium, is called an
|
||||||
|
|
@ -230,9 +230,9 @@ beyond what the individual works permit. Inclusion of a covered work
|
||||||
in an aggregate does not cause this License to apply to the other
|
in an aggregate does not cause this License to apply to the other
|
||||||
parts of the aggregate.
|
parts of the aggregate.
|
||||||
|
|
||||||
6. Conveying Non-Source Forms.
|
6. Conveying Non-Source Forms.
|
||||||
|
|
||||||
You may convey a covered work in object code form under the terms
|
You may convey a covered work in object code form under the terms
|
||||||
of sections 4 and 5, provided that you also convey the
|
of sections 4 and 5, provided that you also convey the
|
||||||
machine-readable Corresponding Source under the terms of this License,
|
machine-readable Corresponding Source under the terms of this License,
|
||||||
in one of these ways:
|
in one of these ways:
|
||||||
|
|
@ -278,11 +278,11 @@ in one of these ways:
|
||||||
Source of the work are being offered to the general public at no
|
Source of the work are being offered to the general public at no
|
||||||
charge under subsection 6d.
|
charge under subsection 6d.
|
||||||
|
|
||||||
A separable portion of the object code, whose source code is excluded
|
A separable portion of the object code, whose source code is excluded
|
||||||
from the Corresponding Source as a System Library, need not be
|
from the Corresponding Source as a System Library, need not be
|
||||||
included in conveying the object code work.
|
included in conveying the object code work.
|
||||||
|
|
||||||
A "User Product" is either (1) a "consumer product", which means any
|
A "User Product" is either (1) a "consumer product", which means any
|
||||||
tangible personal property which is normally used for personal, family,
|
tangible personal property which is normally used for personal, family,
|
||||||
or household purposes, or (2) anything designed or sold for incorporation
|
or household purposes, or (2) anything designed or sold for incorporation
|
||||||
into a dwelling. In determining whether a product is a consumer product,
|
into a dwelling. In determining whether a product is a consumer product,
|
||||||
|
|
@ -295,7 +295,7 @@ is a consumer product regardless of whether the product has substantial
|
||||||
commercial, industrial or non-consumer uses, unless such uses represent
|
commercial, industrial or non-consumer uses, unless such uses represent
|
||||||
the only significant mode of use of the product.
|
the only significant mode of use of the product.
|
||||||
|
|
||||||
"Installation Information" for a User Product means any methods,
|
"Installation Information" for a User Product means any methods,
|
||||||
procedures, authorization keys, or other information required to install
|
procedures, authorization keys, or other information required to install
|
||||||
and execute modified versions of a covered work in that User Product from
|
and execute modified versions of a covered work in that User Product from
|
||||||
a modified version of its Corresponding Source. The information must
|
a modified version of its Corresponding Source. The information must
|
||||||
|
|
@ -303,7 +303,7 @@ suffice to ensure that the continued functioning of the modified object
|
||||||
code is in no case prevented or interfered with solely because
|
code is in no case prevented or interfered with solely because
|
||||||
modification has been made.
|
modification has been made.
|
||||||
|
|
||||||
If you convey an object code work under this section in, or with, or
|
If you convey an object code work under this section in, or with, or
|
||||||
specifically for use in, a User Product, and the conveying occurs as
|
specifically for use in, a User Product, and the conveying occurs as
|
||||||
part of a transaction in which the right of possession and use of the
|
part of a transaction in which the right of possession and use of the
|
||||||
User Product is transferred to the recipient in perpetuity or for a
|
User Product is transferred to the recipient in perpetuity or for a
|
||||||
|
|
@ -314,7 +314,7 @@ if neither you nor any third party retains the ability to install
|
||||||
modified object code on the User Product (for example, the work has
|
modified object code on the User Product (for example, the work has
|
||||||
been installed in ROM).
|
been installed in ROM).
|
||||||
|
|
||||||
The requirement to provide Installation Information does not include a
|
The requirement to provide Installation Information does not include a
|
||||||
requirement to continue to provide support service, warranty, or updates
|
requirement to continue to provide support service, warranty, or updates
|
||||||
for a work that has been modified or installed by the recipient, or for
|
for a work that has been modified or installed by the recipient, or for
|
||||||
the User Product in which it has been modified or installed. Access to a
|
the User Product in which it has been modified or installed. Access to a
|
||||||
|
|
@ -322,15 +322,15 @@ network may be denied when the modification itself materially and
|
||||||
adversely affects the operation of the network or violates the rules and
|
adversely affects the operation of the network or violates the rules and
|
||||||
protocols for communication across the network.
|
protocols for communication across the network.
|
||||||
|
|
||||||
Corresponding Source conveyed, and Installation Information provided,
|
Corresponding Source conveyed, and Installation Information provided,
|
||||||
in accord with this section must be in a format that is publicly
|
in accord with this section must be in a format that is publicly
|
||||||
documented (and with an implementation available to the public in
|
documented (and with an implementation available to the public in
|
||||||
source code form), and must require no special password or key for
|
source code form), and must require no special password or key for
|
||||||
unpacking, reading or copying.
|
unpacking, reading or copying.
|
||||||
|
|
||||||
7. Additional Terms.
|
7. Additional Terms.
|
||||||
|
|
||||||
"Additional permissions" are terms that supplement the terms of this
|
"Additional permissions" are terms that supplement the terms of this
|
||||||
License by making exceptions from one or more of its conditions.
|
License by making exceptions from one or more of its conditions.
|
||||||
Additional permissions that are applicable to the entire Program shall
|
Additional permissions that are applicable to the entire Program shall
|
||||||
be treated as though they were included in this License, to the extent
|
be treated as though they were included in this License, to the extent
|
||||||
|
|
@ -339,14 +339,14 @@ apply only to part of the Program, that part may be used separately
|
||||||
under those permissions, but the entire Program remains governed by
|
under those permissions, but the entire Program remains governed by
|
||||||
this License without regard to the additional permissions.
|
this License without regard to the additional permissions.
|
||||||
|
|
||||||
When you convey a copy of a covered work, you may at your option
|
When you convey a copy of a covered work, you may at your option
|
||||||
remove any additional permissions from that copy, or from any part of
|
remove any additional permissions from that copy, or from any part of
|
||||||
it. (Additional permissions may be written to require their own
|
it. (Additional permissions may be written to require their own
|
||||||
removal in certain cases when you modify the work.) You may place
|
removal in certain cases when you modify the work.) You may place
|
||||||
additional permissions on material, added by you to a covered work,
|
additional permissions on material, added by you to a covered work,
|
||||||
for which you have or can give appropriate copyright permission.
|
for which you have or can give appropriate copyright permission.
|
||||||
|
|
||||||
Notwithstanding any other provision of this License, for material you
|
Notwithstanding any other provision of this License, for material you
|
||||||
add to a covered work, you may (if authorized by the copyright holders of
|
add to a covered work, you may (if authorized by the copyright holders of
|
||||||
that material) supplement the terms of this License with terms:
|
that material) supplement the terms of this License with terms:
|
||||||
|
|
||||||
|
|
@ -373,7 +373,7 @@ that material) supplement the terms of this License with terms:
|
||||||
any liability that these contractual assumptions directly impose on
|
any liability that these contractual assumptions directly impose on
|
||||||
those licensors and authors.
|
those licensors and authors.
|
||||||
|
|
||||||
All other non-permissive additional terms are considered "further
|
All other non-permissive additional terms are considered "further
|
||||||
restrictions" within the meaning of section 10. If the Program as you
|
restrictions" within the meaning of section 10. If the Program as you
|
||||||
received it, or any part of it, contains a notice stating that it is
|
received it, or any part of it, contains a notice stating that it is
|
||||||
governed by this License along with a term that is a further
|
governed by this License along with a term that is a further
|
||||||
|
|
@ -383,46 +383,46 @@ License, you may add to a covered work material governed by the terms
|
||||||
of that license document, provided that the further restriction does
|
of that license document, provided that the further restriction does
|
||||||
not survive such relicensing or conveying.
|
not survive such relicensing or conveying.
|
||||||
|
|
||||||
If you add terms to a covered work in accord with this section, you
|
If you add terms to a covered work in accord with this section, you
|
||||||
must place, in the relevant source files, a statement of the
|
must place, in the relevant source files, a statement of the
|
||||||
additional terms that apply to those files, or a notice indicating
|
additional terms that apply to those files, or a notice indicating
|
||||||
where to find the applicable terms.
|
where to find the applicable terms.
|
||||||
|
|
||||||
Additional terms, permissive or non-permissive, may be stated in the
|
Additional terms, permissive or non-permissive, may be stated in the
|
||||||
form of a separately written license, or stated as exceptions;
|
form of a separately written license, or stated as exceptions;
|
||||||
the above requirements apply either way.
|
the above requirements apply either way.
|
||||||
|
|
||||||
8. Termination.
|
8. Termination.
|
||||||
|
|
||||||
You may not propagate or modify a covered work except as expressly
|
You may not propagate or modify a covered work except as expressly
|
||||||
provided under this License. Any attempt otherwise to propagate or
|
provided under this License. Any attempt otherwise to propagate or
|
||||||
modify it is void, and will automatically terminate your rights under
|
modify it is void, and will automatically terminate your rights under
|
||||||
this License (including any patent licenses granted under the third
|
this License (including any patent licenses granted under the third
|
||||||
paragraph of section 11).
|
paragraph of section 11).
|
||||||
|
|
||||||
However, if you cease all violation of this License, then your
|
However, if you cease all violation of this License, then your
|
||||||
license from a particular copyright holder is reinstated (a)
|
license from a particular copyright holder is reinstated (a)
|
||||||
provisionally, unless and until the copyright holder explicitly and
|
provisionally, unless and until the copyright holder explicitly and
|
||||||
finally terminates your license, and (b) permanently, if the copyright
|
finally terminates your license, and (b) permanently, if the copyright
|
||||||
holder fails to notify you of the violation by some reasonable means
|
holder fails to notify you of the violation by some reasonable means
|
||||||
prior to 60 days after the cessation.
|
prior to 60 days after the cessation.
|
||||||
|
|
||||||
Moreover, your license from a particular copyright holder is
|
Moreover, your license from a particular copyright holder is
|
||||||
reinstated permanently if the copyright holder notifies you of the
|
reinstated permanently if the copyright holder notifies you of the
|
||||||
violation by some reasonable means, this is the first time you have
|
violation by some reasonable means, this is the first time you have
|
||||||
received notice of violation of this License (for any work) from that
|
received notice of violation of this License (for any work) from that
|
||||||
copyright holder, and you cure the violation prior to 30 days after
|
copyright holder, and you cure the violation prior to 30 days after
|
||||||
your receipt of the notice.
|
your receipt of the notice.
|
||||||
|
|
||||||
Termination of your rights under this section does not terminate the
|
Termination of your rights under this section does not terminate the
|
||||||
licenses of parties who have received copies or rights from you under
|
licenses of parties who have received copies or rights from you under
|
||||||
this License. If your rights have been terminated and not permanently
|
this License. If your rights have been terminated and not permanently
|
||||||
reinstated, you do not qualify to receive new licenses for the same
|
reinstated, you do not qualify to receive new licenses for the same
|
||||||
material under section 10.
|
material under section 10.
|
||||||
|
|
||||||
9. Acceptance Not Required for Having Copies.
|
9. Acceptance Not Required for Having Copies.
|
||||||
|
|
||||||
You are not required to accept this License in order to receive or
|
You are not required to accept this License in order to receive or
|
||||||
run a copy of the Program. Ancillary propagation of a covered work
|
run a copy of the Program. Ancillary propagation of a covered work
|
||||||
occurring solely as a consequence of using peer-to-peer transmission
|
occurring solely as a consequence of using peer-to-peer transmission
|
||||||
to receive a copy likewise does not require acceptance. However,
|
to receive a copy likewise does not require acceptance. However,
|
||||||
|
|
@ -431,14 +431,14 @@ modify any covered work. These actions infringe copyright if you do
|
||||||
not accept this License. Therefore, by modifying or propagating a
|
not accept this License. Therefore, by modifying or propagating a
|
||||||
covered work, you indicate your acceptance of this License to do so.
|
covered work, you indicate your acceptance of this License to do so.
|
||||||
|
|
||||||
10. Automatic Licensing of Downstream Recipients.
|
10. Automatic Licensing of Downstream Recipients.
|
||||||
|
|
||||||
Each time you convey a covered work, the recipient automatically
|
Each time you convey a covered work, the recipient automatically
|
||||||
receives a license from the original licensors, to run, modify and
|
receives a license from the original licensors, to run, modify and
|
||||||
propagate that work, subject to this License. You are not responsible
|
propagate that work, subject to this License. You are not responsible
|
||||||
for enforcing compliance by third parties with this License.
|
for enforcing compliance by third parties with this License.
|
||||||
|
|
||||||
An "entity transaction" is a transaction transferring control of an
|
An "entity transaction" is a transaction transferring control of an
|
||||||
organization, or substantially all assets of one, or subdividing an
|
organization, or substantially all assets of one, or subdividing an
|
||||||
organization, or merging organizations. If propagation of a covered
|
organization, or merging organizations. If propagation of a covered
|
||||||
work results from an entity transaction, each party to that
|
work results from an entity transaction, each party to that
|
||||||
|
|
@ -448,7 +448,7 @@ give under the previous paragraph, plus a right to possession of the
|
||||||
Corresponding Source of the work from the predecessor in interest, if
|
Corresponding Source of the work from the predecessor in interest, if
|
||||||
the predecessor has it or can get it with reasonable efforts.
|
the predecessor has it or can get it with reasonable efforts.
|
||||||
|
|
||||||
You may not impose any further restrictions on the exercise of the
|
You may not impose any further restrictions on the exercise of the
|
||||||
rights granted or affirmed under this License. For example, you may
|
rights granted or affirmed under this License. For example, you may
|
||||||
not impose a license fee, royalty, or other charge for exercise of
|
not impose a license fee, royalty, or other charge for exercise of
|
||||||
rights granted under this License, and you may not initiate litigation
|
rights granted under this License, and you may not initiate litigation
|
||||||
|
|
@ -456,13 +456,13 @@ rights granted under this License, and you may not initiate litigation
|
||||||
any patent claim is infringed by making, using, selling, offering for
|
any patent claim is infringed by making, using, selling, offering for
|
||||||
sale, or importing the Program or any portion of it.
|
sale, or importing the Program or any portion of it.
|
||||||
|
|
||||||
11. Patents.
|
11. Patents.
|
||||||
|
|
||||||
A "contributor" is a copyright holder who authorizes use under this
|
A "contributor" is a copyright holder who authorizes use under this
|
||||||
License of the Program or a work on which the Program is based. The
|
License of the Program or a work on which the Program is based. The
|
||||||
work thus licensed is called the contributor's "contributor version".
|
work thus licensed is called the contributor's "contributor version".
|
||||||
|
|
||||||
A contributor's "essential patent claims" are all patent claims
|
A contributor's "essential patent claims" are all patent claims
|
||||||
owned or controlled by the contributor, whether already acquired or
|
owned or controlled by the contributor, whether already acquired or
|
||||||
hereafter acquired, that would be infringed by some manner, permitted
|
hereafter acquired, that would be infringed by some manner, permitted
|
||||||
by this License, of making, using, or selling its contributor version,
|
by this License, of making, using, or selling its contributor version,
|
||||||
|
|
@ -472,19 +472,19 @@ purposes of this definition, "control" includes the right to grant
|
||||||
patent sublicenses in a manner consistent with the requirements of
|
patent sublicenses in a manner consistent with the requirements of
|
||||||
this License.
|
this License.
|
||||||
|
|
||||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||||
patent license under the contributor's essential patent claims, to
|
patent license under the contributor's essential patent claims, to
|
||||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||||
propagate the contents of its contributor version.
|
propagate the contents of its contributor version.
|
||||||
|
|
||||||
In the following three paragraphs, a "patent license" is any express
|
In the following three paragraphs, a "patent license" is any express
|
||||||
agreement or commitment, however denominated, not to enforce a patent
|
agreement or commitment, however denominated, not to enforce a patent
|
||||||
(such as an express permission to practice a patent or covenant not to
|
(such as an express permission to practice a patent or covenant not to
|
||||||
sue for patent infringement). To "grant" such a patent license to a
|
sue for patent infringement). To "grant" such a patent license to a
|
||||||
party means to make such an agreement or commitment not to enforce a
|
party means to make such an agreement or commitment not to enforce a
|
||||||
patent against the party.
|
patent against the party.
|
||||||
|
|
||||||
If you convey a covered work, knowingly relying on a patent license,
|
If you convey a covered work, knowingly relying on a patent license,
|
||||||
and the Corresponding Source of the work is not available for anyone
|
and the Corresponding Source of the work is not available for anyone
|
||||||
to copy, free of charge and under the terms of this License, through a
|
to copy, free of charge and under the terms of this License, through a
|
||||||
publicly available network server or other readily accessible means,
|
publicly available network server or other readily accessible means,
|
||||||
|
|
@ -498,7 +498,7 @@ covered work in a country, or your recipient's use of the covered work
|
||||||
in a country, would infringe one or more identifiable patents in that
|
in a country, would infringe one or more identifiable patents in that
|
||||||
country that you have reason to believe are valid.
|
country that you have reason to believe are valid.
|
||||||
|
|
||||||
If, pursuant to or in connection with a single transaction or
|
If, pursuant to or in connection with a single transaction or
|
||||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||||
covered work, and grant a patent license to some of the parties
|
covered work, and grant a patent license to some of the parties
|
||||||
receiving the covered work authorizing them to use, propagate, modify
|
receiving the covered work authorizing them to use, propagate, modify
|
||||||
|
|
@ -506,7 +506,7 @@ or convey a specific copy of the covered work, then the patent license
|
||||||
you grant is automatically extended to all recipients of the covered
|
you grant is automatically extended to all recipients of the covered
|
||||||
work and works based on it.
|
work and works based on it.
|
||||||
|
|
||||||
A patent license is "discriminatory" if it does not include within
|
A patent license is "discriminatory" if it does not include within
|
||||||
the scope of its coverage, prohibits the exercise of, or is
|
the scope of its coverage, prohibits the exercise of, or is
|
||||||
conditioned on the non-exercise of one or more of the rights that are
|
conditioned on the non-exercise of one or more of the rights that are
|
||||||
specifically granted under this License. You may not convey a covered
|
specifically granted under this License. You may not convey a covered
|
||||||
|
|
@ -521,13 +521,13 @@ for and in connection with specific products or compilations that
|
||||||
contain the covered work, unless you entered into that arrangement,
|
contain the covered work, unless you entered into that arrangement,
|
||||||
or that patent license was granted, prior to 28 March 2007.
|
or that patent license was granted, prior to 28 March 2007.
|
||||||
|
|
||||||
Nothing in this License shall be construed as excluding or limiting
|
Nothing in this License shall be construed as excluding or limiting
|
||||||
any implied license or other defenses to infringement that may
|
any implied license or other defenses to infringement that may
|
||||||
otherwise be available to you under applicable patent law.
|
otherwise be available to you under applicable patent law.
|
||||||
|
|
||||||
12. No Surrender of Others' Freedom.
|
12. No Surrender of Others' Freedom.
|
||||||
|
|
||||||
If conditions are imposed on you (whether by court order, agreement or
|
If conditions are imposed on you (whether by court order, agreement or
|
||||||
otherwise) that contradict the conditions of this License, they do not
|
otherwise) that contradict the conditions of this License, they do not
|
||||||
excuse you from the conditions of this License. If you cannot convey a
|
excuse you from the conditions of this License. If you cannot convey a
|
||||||
covered work so as to satisfy simultaneously your obligations under this
|
covered work so as to satisfy simultaneously your obligations under this
|
||||||
|
|
@ -537,9 +537,9 @@ to collect a royalty for further conveying from those to whom you convey
|
||||||
the Program, the only way you could satisfy both those terms and this
|
the Program, the only way you could satisfy both those terms and this
|
||||||
License would be to refrain entirely from conveying the Program.
|
License would be to refrain entirely from conveying the Program.
|
||||||
|
|
||||||
13. Remote Network Interaction; Use with the GNU General Public License.
|
13. Remote Network Interaction; Use with the GNU General Public License.
|
||||||
|
|
||||||
Notwithstanding any other provision of this License, if you modify the
|
Notwithstanding any other provision of this License, if you modify the
|
||||||
Program, your modified version must prominently offer all users
|
Program, your modified version must prominently offer all users
|
||||||
interacting with it remotely through a computer network (if your version
|
interacting with it remotely through a computer network (if your version
|
||||||
supports such interaction) an opportunity to receive the Corresponding
|
supports such interaction) an opportunity to receive the Corresponding
|
||||||
|
|
@ -550,7 +550,7 @@ shall include the Corresponding Source for any work covered by version 3
|
||||||
of the GNU General Public License that is incorporated pursuant to the
|
of the GNU General Public License that is incorporated pursuant to the
|
||||||
following paragraph.
|
following paragraph.
|
||||||
|
|
||||||
Notwithstanding any other provision of this License, you have
|
Notwithstanding any other provision of this License, you have
|
||||||
permission to link or combine any covered work with a work licensed
|
permission to link or combine any covered work with a work licensed
|
||||||
under version 3 of the GNU General Public License into a single
|
under version 3 of the GNU General Public License into a single
|
||||||
combined work, and to convey the resulting work. The terms of this
|
combined work, and to convey the resulting work. The terms of this
|
||||||
|
|
@ -558,14 +558,14 @@ License will continue to apply to the part which is the covered work,
|
||||||
but the work with which it is combined will remain governed by version
|
but the work with which it is combined will remain governed by version
|
||||||
3 of the GNU General Public License.
|
3 of the GNU General Public License.
|
||||||
|
|
||||||
14. Revised Versions of this License.
|
14. Revised Versions of this License.
|
||||||
|
|
||||||
The Free Software Foundation may publish revised and/or new versions of
|
The Free Software Foundation may publish revised and/or new versions of
|
||||||
the GNU Affero General Public License from time to time. Such new versions
|
the GNU Affero General Public License from time to time. Such new versions
|
||||||
will be similar in spirit to the present version, but may differ in detail to
|
will be similar in spirit to the present version, but may differ in detail to
|
||||||
address new problems or concerns.
|
address new problems or concerns.
|
||||||
|
|
||||||
Each version is given a distinguishing version number. If the
|
Each version is given a distinguishing version number. If the
|
||||||
Program specifies that a certain numbered version of the GNU Affero General
|
Program specifies that a certain numbered version of the GNU Affero General
|
||||||
Public License "or any later version" applies to it, you have the
|
Public License "or any later version" applies to it, you have the
|
||||||
option of following the terms and conditions either of that numbered
|
option of following the terms and conditions either of that numbered
|
||||||
|
|
@ -574,19 +574,19 @@ Foundation. If the Program does not specify a version number of the
|
||||||
GNU Affero General Public License, you may choose any version ever published
|
GNU Affero General Public License, you may choose any version ever published
|
||||||
by the Free Software Foundation.
|
by the Free Software Foundation.
|
||||||
|
|
||||||
If the Program specifies that a proxy can decide which future
|
If the Program specifies that a proxy can decide which future
|
||||||
versions of the GNU Affero General Public License can be used, that proxy's
|
versions of the GNU Affero General Public License can be used, that proxy's
|
||||||
public statement of acceptance of a version permanently authorizes you
|
public statement of acceptance of a version permanently authorizes you
|
||||||
to choose that version for the Program.
|
to choose that version for the Program.
|
||||||
|
|
||||||
Later license versions may give you additional or different
|
Later license versions may give you additional or different
|
||||||
permissions. However, no additional obligations are imposed on any
|
permissions. However, no additional obligations are imposed on any
|
||||||
author or copyright holder as a result of your choosing to follow a
|
author or copyright holder as a result of your choosing to follow a
|
||||||
later version.
|
later version.
|
||||||
|
|
||||||
15. Disclaimer of Warranty.
|
15. Disclaimer of Warranty.
|
||||||
|
|
||||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||||
|
|
@ -595,9 +595,9 @@ PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||||
|
|
||||||
16. Limitation of Liability.
|
16. Limitation of Liability.
|
||||||
|
|
||||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||||
|
|
@ -607,9 +607,9 @@ PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||||
SUCH DAMAGES.
|
SUCH DAMAGES.
|
||||||
|
|
||||||
17. Interpretation of Sections 15 and 16.
|
17. Interpretation of Sections 15 and 16.
|
||||||
|
|
||||||
If the disclaimer of warranty and limitation of liability provided
|
If the disclaimer of warranty and limitation of liability provided
|
||||||
above cannot be given local legal effect according to their terms,
|
above cannot be given local legal effect according to their terms,
|
||||||
reviewing courts shall apply local law that most closely approximates
|
reviewing courts shall apply local law that most closely approximates
|
||||||
an absolute waiver of all civil liability in connection with the
|
an absolute waiver of all civil liability in connection with the
|
||||||
|
|
@ -620,11 +620,11 @@ copy of the Program in return for a fee.
|
||||||
|
|
||||||
How to Apply These Terms to Your New Programs
|
How to Apply These Terms to Your New Programs
|
||||||
|
|
||||||
If you develop a new program, and you want it to be of the greatest
|
If you develop a new program, and you want it to be of the greatest
|
||||||
possible use to the public, the best way to achieve this is to make it
|
possible use to the public, the best way to achieve this is to make it
|
||||||
free software which everyone can redistribute and change under these terms.
|
free software which everyone can redistribute and change under these terms.
|
||||||
|
|
||||||
To do so, attach the following notices to the program. It is safest
|
To do so, attach the following notices to the program. It is safest
|
||||||
to attach them to the start of each source file to most effectively
|
to attach them to the start of each source file to most effectively
|
||||||
state the exclusion of warranty; and each file should have at least
|
state the exclusion of warranty; and each file should have at least
|
||||||
the "copyright" line and a pointer to where the full notice is found.
|
the "copyright" line and a pointer to where the full notice is found.
|
||||||
|
|
@ -647,7 +647,7 @@ the "copyright" line and a pointer to where the full notice is found.
|
||||||
|
|
||||||
Also add information on how to contact you by electronic and paper mail.
|
Also add information on how to contact you by electronic and paper mail.
|
||||||
|
|
||||||
If your software can interact with users remotely through a computer
|
If your software can interact with users remotely through a computer
|
||||||
network, you should also make sure that it provides a way for users to
|
network, you should also make sure that it provides a way for users to
|
||||||
get its source. For example, if your program is a web application, its
|
get its source. For example, if your program is a web application, its
|
||||||
interface could display a "Source" link that leads users to an archive
|
interface could display a "Source" link that leads users to an archive
|
||||||
|
|
@ -655,7 +655,26 @@ of the code. There are many ways you could offer source, and different
|
||||||
solutions will be better for different programs; see section 13 for the
|
solutions will be better for different programs; see section 13 for the
|
||||||
specific requirements.
|
specific requirements.
|
||||||
|
|
||||||
You should also get your employer (if you work as a programmer) or school,
|
You should also get your employer (if you work as a programmer) or school,
|
||||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||||
For more information on this, and how to apply and follow the GNU AGPL, see
|
For more information on this, and how to apply and follow the GNU AGPL, see
|
||||||
<https://www.gnu.org/licenses/>.
|
<https://www.gnu.org/licenses/>.
|
||||||
|
|
||||||
|
Firecrawl - Web scraping and crawling tool
|
||||||
|
Copyright (c) 2024 Sideguide Technologies Inc.
|
||||||
|
|
||||||
|
This program is free software: you can redistribute it and/or modify
|
||||||
|
it under the terms of the GNU Affero General Public License as published
|
||||||
|
by the Free Software Foundation, either version 3 of the License, or
|
||||||
|
(at your option) any later version.
|
||||||
|
|
||||||
|
This program is distributed in the hope that it will be useful,
|
||||||
|
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||||
|
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||||
|
GNU Affero General Public License for more details.
|
||||||
|
|
||||||
|
You should have received a copy of the GNU Affero General Public License
|
||||||
|
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
||||||
|
|
||||||
|
For more information, please contact:
|
||||||
|
Sideguide Technologies Inc.
|
||||||
|
|
|
||||||
491
README.md
491
README.md
|
|
@ -1,27 +1,64 @@
|
||||||
|
<h3 align="center">
|
||||||
|
<a name="readme-top"></a>
|
||||||
|
<img
|
||||||
|
src="https://raw.githubusercontent.com/mendableai/firecrawl/main/img/firecrawl_logo.png"
|
||||||
|
height="200"
|
||||||
|
>
|
||||||
|
</h3>
|
||||||
|
<div align="center">
|
||||||
|
<a href="https://github.com/mendableai/firecrawl/blob/main/LICENSE">
|
||||||
|
<img src="https://img.shields.io/github/license/mendableai/firecrawl" alt="License">
|
||||||
|
</a>
|
||||||
|
<a href="https://pepy.tech/project/firecrawl-py">
|
||||||
|
<img src="https://static.pepy.tech/badge/firecrawl-py" alt="Downloads">
|
||||||
|
</a>
|
||||||
|
<a href="https://GitHub.com/mendableai/firecrawl/graphs/contributors">
|
||||||
|
<img src="https://img.shields.io/github/contributors/mendableai/firecrawl.svg" alt="GitHub Contributors">
|
||||||
|
</a>
|
||||||
|
<a href="https://firecrawl.dev">
|
||||||
|
<img src="https://img.shields.io/badge/Visit-firecrawl.dev-orange" alt="Visit firecrawl.dev">
|
||||||
|
</a>
|
||||||
|
</div>
|
||||||
|
<div>
|
||||||
|
<p align="center">
|
||||||
|
<a href="https://twitter.com/firecrawl_dev">
|
||||||
|
<img src="https://img.shields.io/badge/Follow%20on%20X-000000?style=for-the-badge&logo=x&logoColor=white" alt="Follow on X" />
|
||||||
|
</a>
|
||||||
|
<a href="https://www.linkedin.com/company/104100957">
|
||||||
|
<img src="https://img.shields.io/badge/Follow%20on%20LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white" alt="Follow on LinkedIn" />
|
||||||
|
</a>
|
||||||
|
<a href="https://discord.com/invite/gSmWdAkdwd">
|
||||||
|
<img src="https://img.shields.io/badge/Join%20our%20Discord-5865F2?style=for-the-badge&logo=discord&logoColor=white" alt="Join our Discord" />
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
</div>
|
||||||
|
|
||||||
# 🔥 Firecrawl
|
# 🔥 Firecrawl
|
||||||
|
|
||||||
Crawl and convert any website into LLM-ready markdown or structured data. Built by [Mendable.ai](https://mendable.ai?ref=gfirecrawl) and the Firecrawl community. Includes powerful scraping, crawling and data extraction capabilities.
|
Empower your AI apps with clean data from any website. Featuring advanced scraping, crawling, and data extraction capabilities.
|
||||||
|
|
||||||
_This repository is in its early development stages. We are still merging custom modules in the mono repo. It's not completely yet ready for full self-host deployment, but you can already run it locally._
|
_This repository is in development, and we’re still integrating custom modules into the mono repo. It's not fully ready for self-hosted deployment yet, but you can run it locally._
|
||||||
|
|
||||||
## What is Firecrawl?
|
## What is Firecrawl?
|
||||||
|
|
||||||
[Firecrawl](https://firecrawl.dev?ref=github) is an API service that takes a URL, crawls it, and converts it into clean markdown or structured data. We crawl all accessible subpages and give you clean data for each. No sitemap required.
|
[Firecrawl](https://firecrawl.dev?ref=github) is an API service that takes a URL, crawls it, and converts it into clean markdown or structured data. We crawl all accessible subpages and give you clean data for each. No sitemap required. Check out our [documentation](https://docs.firecrawl.dev).
|
||||||
|
|
||||||
_Pst. hey, you, join our stargazers :)_
|
_Pst. hey, you, join our stargazers :)_
|
||||||
|
|
||||||
<img src="https://github.com/mendableai/firecrawl/assets/44934913/53c4483a-0f0e-40c6-bd84-153a07f94d29" width="200">
|
<a href="https://github.com/mendableai/firecrawl">
|
||||||
|
<img src="https://img.shields.io/github/stars/mendableai/firecrawl.svg?style=social&label=Star&maxAge=2592000" alt="GitHub stars">
|
||||||
|
</a>
|
||||||
|
|
||||||
## How to use it?
|
## How to use it?
|
||||||
|
|
||||||
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
We provide an easy to use API with our hosted version. You can find the playground and documentation [here](https://firecrawl.dev/playground). You can also self host the backend if you'd like.
|
||||||
|
|
||||||
- [x] [API](https://firecrawl.dev/playground)
|
Check out the following resources to get started:
|
||||||
- [x] [Python SDK](https://github.com/mendableai/firecrawl/tree/main/apps/python-sdk)
|
- [x] **API**: [Documentation](https://docs.firecrawl.dev/api-reference/introduction)
|
||||||
- [x] [Node SDK](https://github.com/mendableai/firecrawl/tree/main/apps/js-sdk)
|
- [x] **SDKs**: [Python](https://docs.firecrawl.dev/sdks/python), [Node](https://docs.firecrawl.dev/sdks/node), [Go](https://docs.firecrawl.dev/sdks/go), [Rust](https://docs.firecrawl.dev/sdks/rust)
|
||||||
- [x] [Langchain Integration 🦜🔗](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/)
|
- [x] **LLM Frameworks**: [Langchain (python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/), [Langchain (js)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl), [Llama Index](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader), [Crew.ai](https://docs.crewai.com/), [Composio](https://composio.dev/tools/firecrawl/all), [PraisonAI](https://docs.praison.ai/firecrawl/)
|
||||||
- [x] [Llama Index Integration 🦙](https://docs.llamaindex.ai/en/latest/examples/data_connectors/WebPageDemo/#using-firecrawl-reader)
|
- [x] **Low-code Frameworks**: [Dify](https://dify.ai/blog/dify-ai-blog-integrated-with-firecrawl), [Langflow](https://docs.langflow.org/), [Flowise AI](https://docs.flowiseai.com/integrations/langchain/document-loaders/firecrawl), [Cargo](https://docs.getcargo.io/integration/firecrawl), [Pipedream](https://pipedream.com/apps/firecrawl/)
|
||||||
- [X] [Langchain JS Integration 🦜🔗](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl)
|
- [x] **Others**: [Zapier](https://zapier.com/apps/firecrawl/integrations), [Pabbly Connect](https://www.pabbly.com/connect/integrations/firecrawl/)
|
||||||
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
- [ ] Want an SDK or Integration? Let us know by opening an issue.
|
||||||
|
|
||||||
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md).
|
To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md).
|
||||||
|
|
@ -30,23 +67,48 @@ To run locally, refer to guide [here](https://github.com/mendableai/firecrawl/bl
|
||||||
|
|
||||||
To use the API, you need to sign up on [Firecrawl](https://firecrawl.dev) and get an API key.
|
To use the API, you need to sign up on [Firecrawl](https://firecrawl.dev) and get an API key.
|
||||||
|
|
||||||
|
### Features
|
||||||
|
|
||||||
|
- [**Scrape**](#scraping): scrapes a URL and get its content in LLM-ready format (markdown, structured data via [LLM Extract](#llm-extraction-beta), screenshot, html)
|
||||||
|
- [**Crawl**](#crawling): scrapes all the URLs of a web page and return content in LLM-ready format
|
||||||
|
- [**Map**](#map-alpha): input a website and get all the website urls - extremely fast
|
||||||
|
|
||||||
|
### Powerful Capabilities
|
||||||
|
- **LLM-ready formats**: markdown, structured data, screenshot, HTML, links, metadata
|
||||||
|
- **The hard stuff**: proxies, anti-bot mechanisms, dynamic content (js-rendered), output parsing, orchestration
|
||||||
|
- **Customizability**: exclude tags, crawl behind auth walls with custom headers, max crawl depth, etc...
|
||||||
|
- **Media parsing**: pdfs, docx, images.
|
||||||
|
- **Reliability first**: designed to get the data you need - no matter how hard it is.
|
||||||
|
- **Actions**: click, scroll, input, wait and more before extracting data
|
||||||
|
- **Batching (New)**: scrape thousands of URLs at the same time with a new async endpoint
|
||||||
|
|
||||||
|
You can find all of Firecrawl's capabilities and how to use them in our [documentation](https://docs.firecrawl.dev)
|
||||||
|
|
||||||
### Crawling
|
### Crawling
|
||||||
|
|
||||||
Used to crawl a URL and all accessible subpages. This submits a crawl job and returns a job ID to check the status of the crawl.
|
Used to crawl a URL and all accessible subpages. This submits a crawl job and returns a job ID to check the status of the crawl.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -X POST https://api.firecrawl.dev/v0/crawl \
|
curl -X POST https://api.firecrawl.dev/v1/crawl \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-H 'Authorization: Bearer YOUR_API_KEY' \
|
-H 'Authorization: Bearer fc-YOUR_API_KEY' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://docs.firecrawl.dev",
|
||||||
|
"limit": 100,
|
||||||
|
"scrapeOptions": {
|
||||||
|
"formats": ["markdown", "html"]
|
||||||
|
}
|
||||||
}'
|
}'
|
||||||
```
|
```
|
||||||
|
|
||||||
Returns a jobId
|
Returns a crawl job id and the url to check the status of the crawl.
|
||||||
|
|
||||||
```json
|
```json
|
||||||
{ "jobId": "1234-5678-9101" }
|
{
|
||||||
|
"success": true,
|
||||||
|
"id": "123-456-789",
|
||||||
|
"url": "https://api.firecrawl.dev/v1/crawl/123-456-789"
|
||||||
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Check Crawl Job
|
### Check Crawl Job
|
||||||
|
|
@ -54,7 +116,7 @@ Returns a jobId
|
||||||
Used to check the status of a crawl job and get its result.
|
Used to check the status of a crawl job and get its result.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -X GET https://api.firecrawl.dev/v0/crawl/status/1234-5678-9101 \
|
curl -X GET https://api.firecrawl.dev/v1/crawl/123-456-789 \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-H 'Authorization: Bearer YOUR_API_KEY'
|
-H 'Authorization: Bearer YOUR_API_KEY'
|
||||||
```
|
```
|
||||||
|
|
@ -62,18 +124,20 @@ curl -X GET https://api.firecrawl.dev/v0/crawl/status/1234-5678-9101 \
|
||||||
```json
|
```json
|
||||||
{
|
{
|
||||||
"status": "completed",
|
"status": "completed",
|
||||||
"current": 22,
|
"total": 36,
|
||||||
"total": 22,
|
"creditsUsed": 36,
|
||||||
|
"expiresAt": "2024-00-00T00:00:00.000Z",
|
||||||
"data": [
|
"data": [
|
||||||
{
|
{
|
||||||
"content": "Raw Content ",
|
"markdown": "[Firecrawl Docs home page!...",
|
||||||
"markdown": "# Markdown Content",
|
"html": "<!DOCTYPE html><html lang=\"en\" class=\"js-focus-visible lg:[--scroll-mt:9.5rem]\" data-js-focus-visible=\"\">...",
|
||||||
"provider": "web-scraper",
|
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"title": "Mendable | AI for CX and Sales",
|
"title": "Build a 'Chat with website' using Groq Llama 3 | Firecrawl",
|
||||||
"description": "AI for CX and Sales",
|
"language": "en",
|
||||||
"language": null,
|
"sourceURL": "https://docs.firecrawl.dev/learn/rag-llama3",
|
||||||
"sourceURL": "https://www.mendable.ai/"
|
"description": "Learn how to use Firecrawl, Groq Llama 3, and Langchain to build a 'Chat with your website' bot.",
|
||||||
|
"ogLocaleAlternate": [],
|
||||||
|
"statusCode": 200
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
]
|
]
|
||||||
|
|
@ -82,14 +146,15 @@ curl -X GET https://api.firecrawl.dev/v0/crawl/status/1234-5678-9101 \
|
||||||
|
|
||||||
### Scraping
|
### Scraping
|
||||||
|
|
||||||
Used to scrape a URL and get its content.
|
Used to scrape a URL and get its content in the specified formats.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -X POST https://api.firecrawl.dev/v0/scrape \
|
curl -X POST https://api.firecrawl.dev/v1/scrape \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-H 'Authorization: Bearer YOUR_API_KEY' \
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://mendable.ai"
|
"url": "https://docs.firecrawl.dev",
|
||||||
|
"formats" : ["markdown", "html"]
|
||||||
}'
|
}'
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
@ -99,68 +164,95 @@ Response:
|
||||||
{
|
{
|
||||||
"success": true,
|
"success": true,
|
||||||
"data": {
|
"data": {
|
||||||
"content": "Raw Content ",
|
"markdown": "Launch Week I is here! [See our Day 2 Release 🚀](https://www.firecrawl.dev/blog/launch-week-i-day-2-doubled-rate-limits)[💥 Get 2 months free...",
|
||||||
"markdown": "# Markdown Content",
|
"html": "<!DOCTYPE html><html lang=\"en\" class=\"light\" style=\"color-scheme: light;\"><body class=\"__variable_36bd41 __variable_d7dc5d font-inter ...",
|
||||||
"provider": "web-scraper",
|
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"title": "Mendable | AI for CX and Sales",
|
"title": "Home - Firecrawl",
|
||||||
"description": "AI for CX and Sales",
|
"description": "Firecrawl crawls and converts any website into clean markdown.",
|
||||||
"language": null,
|
"language": "en",
|
||||||
"sourceURL": "https://www.mendable.ai/"
|
"keywords": "Firecrawl,Markdown,Data,Mendable,Langchain",
|
||||||
|
"robots": "follow, index",
|
||||||
|
"ogTitle": "Firecrawl",
|
||||||
|
"ogDescription": "Turn any website into LLM-ready data.",
|
||||||
|
"ogUrl": "https://www.firecrawl.dev/",
|
||||||
|
"ogImage": "https://www.firecrawl.dev/og.png?123",
|
||||||
|
"ogLocaleAlternate": [],
|
||||||
|
"ogSiteName": "Firecrawl",
|
||||||
|
"sourceURL": "https://firecrawl.dev",
|
||||||
|
"statusCode": 200
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Search (Beta)
|
### Map (Alpha)
|
||||||
|
|
||||||
Used to search the web, get the most relevant results, scrape each page and return the markdown.
|
Used to map a URL and get urls of the website. This returns most links present on the website.
|
||||||
|
|
||||||
```bash
|
```bash cURL
|
||||||
curl -X POST https://api.firecrawl.dev/v0/search \
|
curl -X POST https://api.firecrawl.dev/v1/map \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-H 'Authorization: Bearer YOUR_API_KEY' \
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
-d '{
|
-d '{
|
||||||
"query": "firecrawl",
|
"url": "https://firecrawl.dev"
|
||||||
"pageOptions": {
|
|
||||||
"fetchPageContent": true // false for a fast serp api
|
|
||||||
}
|
|
||||||
}'
|
}'
|
||||||
```
|
```
|
||||||
|
|
||||||
|
Response:
|
||||||
|
|
||||||
```json
|
```json
|
||||||
{
|
{
|
||||||
"success": true,
|
"status": "success",
|
||||||
"data": [
|
"links": [
|
||||||
{
|
"https://firecrawl.dev",
|
||||||
"url": "https://mendable.ai",
|
"https://www.firecrawl.dev/pricing",
|
||||||
"markdown": "# Markdown Content",
|
"https://www.firecrawl.dev/blog",
|
||||||
"provider": "web-scraper",
|
"https://www.firecrawl.dev/playground",
|
||||||
"metadata": {
|
"https://www.firecrawl.dev/smart-crawl",
|
||||||
"title": "Mendable | AI for CX and Sales",
|
|
||||||
"description": "AI for CX and Sales",
|
|
||||||
"language": null,
|
|
||||||
"sourceURL": "https://www.mendable.ai/"
|
|
||||||
}
|
|
||||||
}
|
|
||||||
]
|
]
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### Intelligent Extraction (Beta)
|
#### Map with search
|
||||||
|
|
||||||
|
Map with `search` param allows you to search for specific urls inside a website.
|
||||||
|
|
||||||
|
```bash cURL
|
||||||
|
curl -X POST https://api.firecrawl.dev/v1/map \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
|
-d '{
|
||||||
|
"url": "https://firecrawl.dev",
|
||||||
|
"search": "docs"
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
Response will be an ordered list from the most relevant to the least relevant.
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"status": "success",
|
||||||
|
"links": [
|
||||||
|
"https://docs.firecrawl.dev",
|
||||||
|
"https://docs.firecrawl.dev/sdks/python",
|
||||||
|
"https://docs.firecrawl.dev/learn/rag-llama3",
|
||||||
|
]
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### LLM Extraction (Beta)
|
||||||
|
|
||||||
Used to extract structured data from scraped pages.
|
Used to extract structured data from scraped pages.
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -X POST https://api.firecrawl.dev/v0/scrape \
|
curl -X POST https://api.firecrawl.dev/v1/scrape \
|
||||||
-H 'Content-Type: application/json' \
|
-H 'Content-Type: application/json' \
|
||||||
-H 'Authorization: Bearer YOUR_API_KEY' \
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
-d '{
|
-d '{
|
||||||
"url": "https://www.mendable.ai/",
|
"url": "https://www.mendable.ai/",
|
||||||
"extractorOptions": {
|
"formats": ["extract"],
|
||||||
"mode": "llm-extraction",
|
"extract": {
|
||||||
"extractionPrompt": "Based on the information on the page, extract the information from the schema. ",
|
"schema": {
|
||||||
"extractionSchema": {
|
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
"company_mission": {
|
"company_mission": {
|
||||||
|
|
@ -212,7 +304,100 @@ curl -X POST https://api.firecrawl.dev/v0/scrape \
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### Extracting without a schema (New)
|
||||||
|
|
||||||
|
You can now extract without a schema by just passing a `prompt` to the endpoint. The llm chooses the structure of the data.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST https://api.firecrawl.dev/v1/scrape \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
|
-d '{
|
||||||
|
"url": "https://docs.firecrawl.dev/",
|
||||||
|
"formats": ["extract"],
|
||||||
|
"extract": {
|
||||||
|
"prompt": "Extract the company mission from the page."
|
||||||
|
}
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Interacting with the page with Actions (Cloud-only)
|
||||||
|
|
||||||
|
Firecrawl allows you to perform various actions on a web page before scraping its content. This is particularly useful for interacting with dynamic content, navigating through pages, or accessing content that requires user interaction.
|
||||||
|
|
||||||
|
Here is an example of how to use actions to navigate to google.com, search for Firecrawl, click on the first result, and take a screenshot.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST https://api.firecrawl.dev/v1/scrape \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
|
-d '{
|
||||||
|
"url": "google.com",
|
||||||
|
"formats": ["markdown"],
|
||||||
|
"actions": [
|
||||||
|
{"type": "wait", "milliseconds": 2000},
|
||||||
|
{"type": "click", "selector": "textarea[title=\"Search\"]"},
|
||||||
|
{"type": "wait", "milliseconds": 2000},
|
||||||
|
{"type": "write", "text": "firecrawl"},
|
||||||
|
{"type": "wait", "milliseconds": 2000},
|
||||||
|
{"type": "press", "key": "ENTER"},
|
||||||
|
{"type": "wait", "milliseconds": 3000},
|
||||||
|
{"type": "click", "selector": "h3"},
|
||||||
|
{"type": "wait", "milliseconds": 3000},
|
||||||
|
{"type": "screenshot"}
|
||||||
|
]
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Batch Scraping Multiple URLs (New)
|
||||||
|
|
||||||
|
You can now batch scrape multiple URLs at the same time. It is very similar to how the /crawl endpoint works. It submits a batch scrape job and returns a job ID to check the status of the batch scrape.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST https://api.firecrawl.dev/v1/batch/scrape \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
|
-d '{
|
||||||
|
"urls": ["https://docs.firecrawl.dev", "https://docs.firecrawl.dev/sdks/overview"],
|
||||||
|
"formats" : ["markdown", "html"]
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
### Search (v0) (Beta)
|
||||||
|
|
||||||
|
Used to search the web, get the most relevant results, scrape each page and return the markdown.
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST https://api.firecrawl.dev/v0/search \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-H 'Authorization: Bearer YOUR_API_KEY' \
|
||||||
|
-d '{
|
||||||
|
"query": "firecrawl",
|
||||||
|
"pageOptions": {
|
||||||
|
"fetchPageContent": true // false for a fast serp api
|
||||||
|
}
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
```json
|
||||||
|
{
|
||||||
|
"success": true,
|
||||||
|
"data": [
|
||||||
|
{
|
||||||
|
"url": "https://mendable.ai",
|
||||||
|
"markdown": "# Markdown Content",
|
||||||
|
"provider": "web-scraper",
|
||||||
|
"metadata": {
|
||||||
|
"title": "Mendable | AI for CX and Sales",
|
||||||
|
"description": "AI for CX and Sales",
|
||||||
|
"language": null,
|
||||||
|
"sourceURL": "https://www.mendable.ai/"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
## Using Python SDK
|
## Using Python SDK
|
||||||
|
|
@ -226,31 +411,39 @@ pip install firecrawl-py
|
||||||
### Crawl a website
|
### Crawl a website
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from firecrawl import FirecrawlApp
|
from firecrawl.firecrawl import FirecrawlApp
|
||||||
|
|
||||||
app = FirecrawlApp(api_key="YOUR_API_KEY")
|
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
|
||||||
|
|
||||||
crawl_result = app.crawl_url('mendable.ai', {'crawlerOptions': {'excludes': ['blog/*']}})
|
# Scrape a website:
|
||||||
|
scrape_status = app.scrape_url(
|
||||||
|
'https://firecrawl.dev',
|
||||||
|
params={'formats': ['markdown', 'html']}
|
||||||
|
)
|
||||||
|
print(scrape_status)
|
||||||
|
|
||||||
# Get the markdown
|
# Crawl a website:
|
||||||
for result in crawl_result:
|
crawl_status = app.crawl_url(
|
||||||
print(result['markdown'])
|
'https://firecrawl.dev',
|
||||||
```
|
params={
|
||||||
|
'limit': 100,
|
||||||
### Scraping a URL
|
'scrapeOptions': {'formats': ['markdown', 'html']}
|
||||||
|
},
|
||||||
To scrape a single URL, use the `scrape_url` method. It takes the URL as a parameter and returns the scraped data as a dictionary.
|
poll_interval=30
|
||||||
|
)
|
||||||
```python
|
print(crawl_status)
|
||||||
url = 'https://example.com'
|
|
||||||
scraped_data = app.scrape_url(url)
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### Extracting structured data from a URL
|
### Extracting structured data from a URL
|
||||||
|
|
||||||
With LLM extraction, you can easily extract structured data from any URL. We support pydanti schemas to make it easier for you too. Here is how you to use it:
|
With LLM extraction, you can easily extract structured data from any URL. We support pydantic schemas to make it easier for you too. Here is how you to use it:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
|
|
||||||
|
from firecrawl.firecrawl import FirecrawlApp
|
||||||
|
|
||||||
|
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
|
||||||
|
|
||||||
class ArticleSchema(BaseModel):
|
class ArticleSchema(BaseModel):
|
||||||
title: str
|
title: str
|
||||||
points: int
|
points: int
|
||||||
|
|
@ -261,24 +454,12 @@ class TopArticlesSchema(BaseModel):
|
||||||
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
|
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
|
||||||
|
|
||||||
data = app.scrape_url('https://news.ycombinator.com', {
|
data = app.scrape_url('https://news.ycombinator.com', {
|
||||||
'extractorOptions': {
|
'formats': ['extract'],
|
||||||
'extractionSchema': TopArticlesSchema.model_json_schema(),
|
'extract': {
|
||||||
'mode': 'llm-extraction'
|
'schema': TopArticlesSchema.model_json_schema()
|
||||||
},
|
|
||||||
'pageOptions':{
|
|
||||||
'onlyMainContent': True
|
|
||||||
}
|
}
|
||||||
})
|
})
|
||||||
print(data["llm_extraction"])
|
print(data["extract"])
|
||||||
```
|
|
||||||
|
|
||||||
### Search for a query
|
|
||||||
|
|
||||||
Performs a web search, retrieve the top results, extract data from each page, and returns their markdown.
|
|
||||||
|
|
||||||
```python
|
|
||||||
query = 'What is Mendable?'
|
|
||||||
search_result = app.search(query)
|
|
||||||
```
|
```
|
||||||
|
|
||||||
## Using the Node SDK
|
## Using the Node SDK
|
||||||
|
|
@ -296,64 +477,34 @@ npm install @mendable/firecrawl-js
|
||||||
1. Get an API key from [firecrawl.dev](https://firecrawl.dev)
|
1. Get an API key from [firecrawl.dev](https://firecrawl.dev)
|
||||||
2. Set the API key as an environment variable named `FIRECRAWL_API_KEY` or pass it as a parameter to the `FirecrawlApp` class.
|
2. Set the API key as an environment variable named `FIRECRAWL_API_KEY` or pass it as a parameter to the `FirecrawlApp` class.
|
||||||
|
|
||||||
### Scraping a URL
|
|
||||||
|
|
||||||
To scrape a single URL with error handling, use the `scrapeUrl` method. It takes the URL as a parameter and returns the scraped data as a dictionary.
|
|
||||||
|
|
||||||
```js
|
```js
|
||||||
try {
|
import FirecrawlApp, { CrawlParams, CrawlStatusResponse } from '@mendable/firecrawl-js';
|
||||||
const url = 'https://example.com';
|
|
||||||
const scrapedData = await app.scrapeUrl(url);
|
|
||||||
console.log(scrapedData);
|
|
||||||
|
|
||||||
} catch (error) {
|
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
|
||||||
console.error(
|
|
||||||
'Error occurred while scraping:',
|
// Scrape a website
|
||||||
error.message
|
const scrapeResponse = await app.scrapeUrl('https://firecrawl.dev', {
|
||||||
);
|
formats: ['markdown', 'html'],
|
||||||
|
});
|
||||||
|
|
||||||
|
if (scrapeResponse) {
|
||||||
|
console.log(scrapeResponse)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Crawl a website
|
||||||
|
const crawlResponse = await app.crawlUrl('https://firecrawl.dev', {
|
||||||
|
limit: 100,
|
||||||
|
scrapeOptions: {
|
||||||
|
formats: ['markdown', 'html'],
|
||||||
|
}
|
||||||
|
} satisfies CrawlParams, true, 30) satisfies CrawlStatusResponse;
|
||||||
|
|
||||||
|
if (crawlResponse) {
|
||||||
|
console.log(crawlResponse)
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
### Crawling a Website
|
|
||||||
|
|
||||||
To crawl a website with error handling, use the `crawlUrl` method. It takes the starting URL and optional parameters as arguments. The `params` argument allows you to specify additional options for the crawl job, such as the maximum number of pages to crawl, allowed domains, and the output format.
|
|
||||||
|
|
||||||
```js
|
|
||||||
const crawlUrl = 'https://example.com';
|
|
||||||
const params = {
|
|
||||||
crawlerOptions: {
|
|
||||||
excludes: ['blog/'],
|
|
||||||
includes: [], // leave empty for all pages
|
|
||||||
limit: 1000,
|
|
||||||
},
|
|
||||||
pageOptions: {
|
|
||||||
onlyMainContent: true
|
|
||||||
}
|
|
||||||
};
|
|
||||||
const waitUntilDone = true;
|
|
||||||
const timeout = 5;
|
|
||||||
const crawlResult = await app.crawlUrl(
|
|
||||||
crawlUrl,
|
|
||||||
params,
|
|
||||||
waitUntilDone,
|
|
||||||
timeout
|
|
||||||
);
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
### Checking Crawl Status
|
|
||||||
|
|
||||||
To check the status of a crawl job with error handling, use the `checkCrawlStatus` method. It takes the job ID as a parameter and returns the current status of the crawl job.
|
|
||||||
|
|
||||||
```js
|
|
||||||
const status = await app.checkCrawlStatus(jobId);
|
|
||||||
console.log(status);
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Extracting structured data from a URL
|
### Extracting structured data from a URL
|
||||||
|
|
||||||
With LLM extraction, you can easily extract structured data from any URL. We support zod schema to make it easier for you too. Here is how you to use it:
|
With LLM extraction, you can easily extract structured data from any URL. We support zod schema to make it easier for you too. Here is how you to use it:
|
||||||
|
|
@ -363,7 +514,7 @@ import FirecrawlApp from "@mendable/firecrawl-js";
|
||||||
import { z } from "zod";
|
import { z } from "zod";
|
||||||
|
|
||||||
const app = new FirecrawlApp({
|
const app = new FirecrawlApp({
|
||||||
apiKey: "fc-YOUR_API_KEY",
|
apiKey: "fc-YOUR_API_KEY"
|
||||||
});
|
});
|
||||||
|
|
||||||
// Define schema to extract contents into
|
// Define schema to extract contents into
|
||||||
|
|
@ -388,22 +539,44 @@ const scrapeResult = await app.scrapeUrl("https://news.ycombinator.com", {
|
||||||
console.log(scrapeResult.data["llm_extraction"]);
|
console.log(scrapeResult.data["llm_extraction"]);
|
||||||
```
|
```
|
||||||
|
|
||||||
### Search for a query
|
## Open Source vs Cloud Offering
|
||||||
|
|
||||||
With the `search` method, you can search for a query in a search engine and get the top results along with the page content for each result. The method takes the query as a parameter and returns the search results.
|
Firecrawl is open source available under the AGPL-3.0 license.
|
||||||
|
|
||||||
```js
|
To deliver the best possible product, we offer a hosted version of Firecrawl alongside our open-source offering. The cloud solution allows us to continuously innovate and maintain a high-quality, sustainable service for all users.
|
||||||
const query = 'what is mendable?';
|
|
||||||
const searchResults = await app.search(query, {
|
Firecrawl Cloud is available at [firecrawl.dev](https://firecrawl.dev) and offers a range of features that are not available in the open source version:
|
||||||
pageOptions: {
|
|
||||||
fetchPageContent: true // Fetch the page content for each search result
|
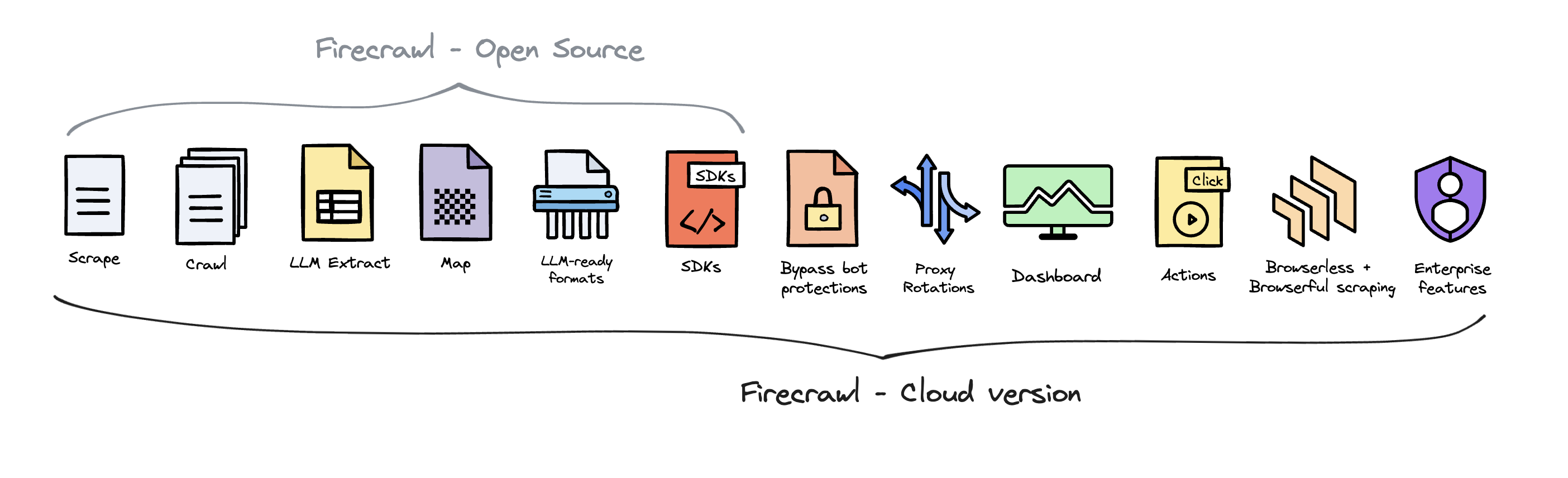
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
## Contributing
|
## Contributing
|
||||||
|
|
||||||
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request.
|
We love contributions! Please read our [contributing guide](CONTRIBUTING.md) before submitting a pull request. If you'd like to self-host, refer to the [self-hosting guide](SELF_HOST.md).
|
||||||
|
|
||||||
*It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions.*
|
_It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions._
|
||||||
|
|
||||||
|
## Contributors
|
||||||
|
|
||||||
|
<a href="https://github.com/mendableai/firecrawl/graphs/contributors">
|
||||||
|
<img alt="contributors" src="https://contrib.rocks/image?repo=mendableai/firecrawl"/>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
## License Disclaimer
|
||||||
|
|
||||||
|
This project is primarily licensed under the GNU Affero General Public License v3.0 (AGPL-3.0), as specified in the LICENSE file in the root directory of this repository. However, certain components of this project are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
|
||||||
|
|
||||||
|
Please note:
|
||||||
|
|
||||||
|
- The AGPL-3.0 license applies to all parts of the project unless otherwise specified.
|
||||||
|
- The SDKs and some UI components are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
|
||||||
|
- When using or contributing to this project, ensure you comply with the appropriate license terms for the specific component you are working with.
|
||||||
|
|
||||||
|
For more details on the licensing of specific components, please refer to the LICENSE files in the respective directories or contact the project maintainers.
|
||||||
|
|
||||||
|
|
||||||
|
<p align="right" style="font-size: 14px; color: #555; margin-top: 20px;">
|
||||||
|
<a href="#readme-top" style="text-decoration: none; color: #007bff; font-weight: bold;">
|
||||||
|
↑ Back to Top ↑
|
||||||
|
</a>
|
||||||
|
</p>
|
||||||
|
|
|
||||||
189
SELF_HOST.md
189
SELF_HOST.md
|
|
@ -1,34 +1,179 @@
|
||||||
# Self-hosting Firecrawl
|
# Self-hosting Firecrawl
|
||||||
*We're currently working on a more in-depth guide on how to self-host, but in the meantime, here is a simplified version.*
|
|
||||||
|
|
||||||
Refer to [CONTRIBUTING.md](https://github.com/mendableai/firecrawl/blob/main/CONTRIBUTING.md) for instructions on how to run it locally.
|
#### Contributor?
|
||||||
|
|
||||||
## Getting Started
|
Welcome to [Firecrawl](https://firecrawl.dev) 🔥! Here are some instructions on how to get the project locally so you can run it on your own and contribute.
|
||||||
|
|
||||||
First, clone this repository and copy the example env file from api folder `.env.example` to `.env`.
|
If you're contributing, note that the process is similar to other open-source repos, i.e., fork Firecrawl, make changes, run tests, PR.
|
||||||
```bash
|
|
||||||
git clone https://github.com/mendableai/firecrawl.git
|
If you have any questions or would like help getting on board, join our Discord community [here](https://discord.gg/gSmWdAkdwd) for more information or submit an issue on Github [here](https://github.com/mendableai/firecrawl/issues/new/choose)!
|
||||||
cd firecrawl
|
|
||||||
cp ./apps/api/.env.example ./.env
|
## Why?
|
||||||
|
|
||||||
|
Self-hosting Firecrawl is particularly beneficial for organizations with stringent security policies that require data to remain within controlled environments. Here are some key reasons to consider self-hosting:
|
||||||
|
|
||||||
|
- **Enhanced Security and Compliance:** By self-hosting, you ensure that all data handling and processing complies with internal and external regulations, keeping sensitive information within your secure infrastructure. Note that Firecrawl is a Mendable product and relies on SOC2 Type2 certification, which means that the platform adheres to high industry standards for managing data security.
|
||||||
|
- **Customizable Services:** Self-hosting allows you to tailor the services, such as the Playwright service, to meet specific needs or handle particular use cases that may not be supported by the standard cloud offering.
|
||||||
|
- **Learning and Community Contribution:** By setting up and maintaining your own instance, you gain a deeper understanding of how Firecrawl works, which can also lead to more meaningful contributions to the project.
|
||||||
|
|
||||||
|
### Considerations
|
||||||
|
|
||||||
|
However, there are some limitations and additional responsibilities to be aware of:
|
||||||
|
|
||||||
|
1. **Limited Access to Fire-engine:** Currently, self-hosted instances of Firecrawl do not have access to Fire-engine, which includes advanced features for handling IP blocks, robot detection mechanisms, and more. This means that while you can manage basic scraping tasks, more complex scenarios might require additional configuration or might not be supported.
|
||||||
|
2. **Manual Configuration Required:** If you need to use scraping methods beyond the basic fetch and Playwright options, you will need to manually configure these in the `.env` file. This requires a deeper understanding of the technologies and might involve more setup time.
|
||||||
|
|
||||||
|
Self-hosting Firecrawl is ideal for those who need full control over their scraping and data processing environments but comes with the trade-off of additional maintenance and configuration efforts.
|
||||||
|
|
||||||
|
## Steps
|
||||||
|
|
||||||
|
1. First, start by installing the dependencies
|
||||||
|
|
||||||
|
- Docker [instructions](https://docs.docker.com/get-docker/)
|
||||||
|
|
||||||
|
|
||||||
|
2. Set environment variables
|
||||||
|
|
||||||
|
Create an `.env` in the root directory you can copy over the template in `apps/api/.env.example`
|
||||||
|
|
||||||
|
To start, we won't set up authentication or any optional subservices (pdf parsing, JS blocking support, AI features)
|
||||||
|
|
||||||
|
`.env:`
|
||||||
```
|
```
|
||||||
|
# ===== Required ENVS ======
|
||||||
For running the simplest version of FireCrawl, edit the `USE_DB_AUTHENTICATION` on `.env` to not use the database authentication.
|
NUM_WORKERS_PER_QUEUE=8
|
||||||
```yml
|
PORT=3002
|
||||||
USE_DB_AUTHENTICATION=false
|
HOST=0.0.0.0
|
||||||
```
|
|
||||||
|
|
||||||
Update the Redis URL in the .env file to align with the Docker configuration:
|
|
||||||
```yml
|
|
||||||
REDIS_URL=redis://redis:6379
|
REDIS_URL=redis://redis:6379
|
||||||
|
REDIS_RATE_LIMIT_URL=redis://redis:6379
|
||||||
|
|
||||||
|
## To turn on DB authentication, you need to set up Supabase.
|
||||||
|
USE_DB_AUTHENTICATION=false
|
||||||
|
|
||||||
|
# ===== Optional ENVS ======
|
||||||
|
|
||||||
|
# Supabase Setup (used to support DB authentication, advanced logging, etc.)
|
||||||
|
SUPABASE_ANON_TOKEN=
|
||||||
|
SUPABASE_URL=
|
||||||
|
SUPABASE_SERVICE_TOKEN=
|
||||||
|
|
||||||
|
# Other Optionals
|
||||||
|
TEST_API_KEY= # use if you've set up authentication and want to test with a real API key
|
||||||
|
SCRAPING_BEE_API_KEY= # use if you'd like to use as a fallback scraper
|
||||||
|
OPENAI_API_KEY= # add for LLM-dependent features (e.g., image alt generation)
|
||||||
|
BULL_AUTH_KEY= @
|
||||||
|
LOGTAIL_KEY= # Use if you're configuring basic logging with logtail
|
||||||
|
PLAYWRIGHT_MICROSERVICE_URL= # set if you'd like to run a playwright fallback
|
||||||
|
LLAMAPARSE_API_KEY= #Set if you have a llamaparse key you'd like to use to parse pdfs
|
||||||
|
SLACK_WEBHOOK_URL= # set if you'd like to send slack server health status messages
|
||||||
|
POSTHOG_API_KEY= # set if you'd like to send posthog events like job logs
|
||||||
|
POSTHOG_HOST= # set if you'd like to send posthog events like job logs
|
||||||
```
|
```
|
||||||
|
|
||||||
Once that's complete, you can simply run the following commands to get started:
|
3. *(Optional) Running with TypeScript Playwright Service*
|
||||||
```bash
|
|
||||||
docker compose up
|
|
||||||
```
|
|
||||||
|
|
||||||
|
* Update the `docker-compose.yml` file to change the Playwright service:
|
||||||
|
|
||||||
|
```plaintext
|
||||||
|
build: apps/playwright-service
|
||||||
|
```
|
||||||
|
TO
|
||||||
|
```plaintext
|
||||||
|
build: apps/playwright-service-ts
|
||||||
|
```
|
||||||
|
|
||||||
|
* Set the `PLAYWRIGHT_MICROSERVICE_URL` in your `.env` file:
|
||||||
|
|
||||||
|
```plaintext
|
||||||
|
PLAYWRIGHT_MICROSERVICE_URL=http://localhost:3000/scrape
|
||||||
|
```
|
||||||
|
|
||||||
|
* Don't forget to set the proxy server in your `.env` file as needed.
|
||||||
|
|
||||||
|
4. Build and run the Docker containers:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
docker compose build
|
||||||
|
docker compose up
|
||||||
|
```
|
||||||
|
|
||||||
This will run a local instance of Firecrawl which can be accessed at `http://localhost:3002`.
|
This will run a local instance of Firecrawl which can be accessed at `http://localhost:3002`.
|
||||||
|
|
||||||
# Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
You should be able to see the Bull Queue Manager UI on `http://localhost:3002/admin/@/queues`.
|
||||||
Read the [examples/k8n/README.md](examples/k8n/README.md) for instructions on how to install Firecrawl on a Kubernetes Cluster.
|
|
||||||
|
5. *(Optional)* Test the API
|
||||||
|
|
||||||
|
If you’d like to test the crawl endpoint, you can run this:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -X POST http://localhost:3002/v1/crawl \
|
||||||
|
-H 'Content-Type: application/json' \
|
||||||
|
-d '{
|
||||||
|
"url": "https://mendable.ai"
|
||||||
|
}'
|
||||||
|
```
|
||||||
|
|
||||||
|
## Troubleshooting
|
||||||
|
|
||||||
|
This section provides solutions to common issues you might encounter while setting up or running your self-hosted instance of Firecrawl.
|
||||||
|
|
||||||
|
### Supabase client is not configured
|
||||||
|
|
||||||
|
**Symptom:**
|
||||||
|
```bash
|
||||||
|
[YYYY-MM-DDTHH:MM:SS.SSSz]ERROR - Attempted to access Supabase client when it's not configured.
|
||||||
|
[YYYY-MM-DDTHH:MM:SS.SSSz]ERROR - Error inserting scrape event: Error: Supabase client is not configured.
|
||||||
|
```
|
||||||
|
|
||||||
|
**Explanation:**
|
||||||
|
This error occurs because the Supabase client setup is not completed. You should be able to scrape and crawl with no problems. Right now it's not possible to configure Supabase in self-hosted instances.
|
||||||
|
|
||||||
|
### You're bypassing authentication
|
||||||
|
|
||||||
|
**Symptom:**
|
||||||
|
```bash
|
||||||
|
[YYYY-MM-DDTHH:MM:SS.SSSz]WARN - You're bypassing authentication
|
||||||
|
```
|
||||||
|
|
||||||
|
**Explanation:**
|
||||||
|
This error occurs because the Supabase client setup is not completed. You should be able to scrape and crawl with no problems. Right now it's not possible to configure Supabase in self-hosted instances.
|
||||||
|
|
||||||
|
### Docker containers fail to start
|
||||||
|
|
||||||
|
**Symptom:**
|
||||||
|
Docker containers exit unexpectedly or fail to start.
|
||||||
|
|
||||||
|
**Solution:**
|
||||||
|
Check the Docker logs for any error messages using the command:
|
||||||
|
```bash
|
||||||
|
docker logs [container_name]
|
||||||
|
```
|
||||||
|
|
||||||
|
- Ensure all required environment variables are set correctly in the .env file.
|
||||||
|
- Verify that all Docker services defined in docker-compose.yml are correctly configured and the necessary images are available.
|
||||||
|
|
||||||
|
### Connection issues with Redis
|
||||||
|
|
||||||
|
**Symptom:**
|
||||||
|
Errors related to connecting to Redis, such as timeouts or "Connection refused".
|
||||||
|
|
||||||
|
**Solution:**
|
||||||
|
- Ensure that the Redis service is up and running in your Docker environment.
|
||||||
|
- Verify that the REDIS_URL and REDIS_RATE_LIMIT_URL in your .env file point to the correct Redis instance, ensure that it points to the same URL in the `docker-compose.yaml` file (`redis://redis:6379`)
|
||||||
|
- Check network settings and firewall rules that may block the connection to the Redis port.
|
||||||
|
|
||||||
|
### API endpoint does not respond
|
||||||
|
|
||||||
|
**Symptom:**
|
||||||
|
API requests to the Firecrawl instance timeout or return no response.
|
||||||
|
|
||||||
|
**Solution:**
|
||||||
|
- Ensure that the Firecrawl service is running by checking the Docker container status.
|
||||||
|
- Verify that the PORT and HOST settings in your .env file are correct and that no other service is using the same port.
|
||||||
|
- Check the network configuration to ensure that the host is accessible from the client making the API request.
|
||||||
|
|
||||||
|
By addressing these common issues, you can ensure a smoother setup and operation of your self-hosted Firecrawl instance.
|
||||||
|
|
||||||
|
## Install Firecrawl on a Kubernetes Cluster (Simple Version)
|
||||||
|
|
||||||
|
Read the [examples/kubernetes/cluster-install/README.md](https://github.com/mendableai/firecrawl/blob/main/examples/kubernetes/cluster-install/README.md) for instructions on how to install Firecrawl on a Kubernetes Cluster.
|
||||||
|
|
|
||||||
|
|
@ -2,7 +2,8 @@
|
||||||
NUM_WORKERS_PER_QUEUE=8
|
NUM_WORKERS_PER_QUEUE=8
|
||||||
PORT=3002
|
PORT=3002
|
||||||
HOST=0.0.0.0
|
HOST=0.0.0.0
|
||||||
REDIS_URL=redis://localhost:6379
|
REDIS_URL=redis://redis:6379 #for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
|
||||||
|
REDIS_RATE_LIMIT_URL=redis://redis:6379 #for self-hosting using docker, use redis://redis:6379. For running locally, use redis://localhost:6379
|
||||||
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
|
PLAYWRIGHT_MICROSERVICE_URL=http://playwright-service:3000/html
|
||||||
|
|
||||||
## To turn on DB authentication, you need to set up supabase.
|
## To turn on DB authentication, you need to set up supabase.
|
||||||
|
|
@ -10,24 +11,38 @@ USE_DB_AUTHENTICATION=true
|
||||||
|
|
||||||
# ===== Optional ENVS ======
|
# ===== Optional ENVS ======
|
||||||
|
|
||||||
|
# SearchApi key. Head to https://searchapi.com/ to get your API key
|
||||||
|
SEARCHAPI_API_KEY=
|
||||||
|
# SearchApi engine, defaults to google. Available options: google, bing, baidu, google_news, etc. Head to https://searchapi.com/ to explore more engines
|
||||||
|
SEARCHAPI_ENGINE=
|
||||||
|
|
||||||
# Supabase Setup (used to support DB authentication, advanced logging, etc.)
|
# Supabase Setup (used to support DB authentication, advanced logging, etc.)
|
||||||
SUPABASE_ANON_TOKEN=
|
SUPABASE_ANON_TOKEN=
|
||||||
SUPABASE_URL=
|
SUPABASE_URL=
|
||||||
SUPABASE_SERVICE_TOKEN=
|
SUPABASE_SERVICE_TOKEN=
|
||||||
|
|
||||||
# Other Optionals
|
# Other Optionals
|
||||||
TEST_API_KEY= # use if you've set up authentication and want to test with a real API key
|
# use if you've set up authentication and want to test with a real API key
|
||||||
RATE_LIMIT_TEST_API_KEY_SCRAPE= # set if you'd like to test the scraping rate limit
|
TEST_API_KEY=
|
||||||
RATE_LIMIT_TEST_API_KEY_CRAWL= # set if you'd like to test the crawling rate limit
|
# set if you'd like to test the scraping rate limit
|
||||||
SCRAPING_BEE_API_KEY= #Set if you'd like to use scraping Be to handle JS blocking
|
RATE_LIMIT_TEST_API_KEY_SCRAPE=
|
||||||
OPENAI_API_KEY= # add for LLM dependednt features (image alt generation, etc.)
|
# set if you'd like to test the crawling rate limit
|
||||||
BULL_AUTH_KEY= @
|
RATE_LIMIT_TEST_API_KEY_CRAWL=
|
||||||
LOGTAIL_KEY= # Use if you're configuring basic logging with logtail
|
# set if you'd like to use scraping Be to handle JS blocking
|
||||||
LLAMAPARSE_API_KEY= #Set if you have a llamaparse key you'd like to use to parse pdfs
|
SCRAPING_BEE_API_KEY=
|
||||||
SERPER_API_KEY= #Set if you have a serper key you'd like to use as a search api
|
# add for LLM dependednt features (image alt generation, etc.)
|
||||||
SLACK_WEBHOOK_URL= # set if you'd like to send slack server health status messages
|
OPENAI_API_KEY=
|
||||||
POSTHOG_API_KEY= # set if you'd like to send posthog events like job logs
|
BULL_AUTH_KEY=@
|
||||||
POSTHOG_HOST= # set if you'd like to send posthog events like job logs
|
# use if you're configuring basic logging with logtail
|
||||||
|
LOGTAIL_KEY=
|
||||||
|
# set if you have a llamaparse key you'd like to use to parse pdfs
|
||||||
|
LLAMAPARSE_API_KEY=
|
||||||
|
# set if you'd like to send slack server health status messages
|
||||||
|
SLACK_WEBHOOK_URL=
|
||||||
|
# set if you'd like to send posthog events like job logs
|
||||||
|
POSTHOG_API_KEY=
|
||||||
|
# set if you'd like to send posthog events like job logs
|
||||||
|
POSTHOG_HOST=
|
||||||
|
|
||||||
STRIPE_PRICE_ID_STANDARD=
|
STRIPE_PRICE_ID_STANDARD=
|
||||||
STRIPE_PRICE_ID_SCALE=
|
STRIPE_PRICE_ID_SCALE=
|
||||||
|
|
@ -42,7 +57,8 @@ STRIPE_PRICE_ID_GROWTH_YEARLY=
|
||||||
HYPERDX_API_KEY=
|
HYPERDX_API_KEY=
|
||||||
HDX_NODE_BETA_MODE=1
|
HDX_NODE_BETA_MODE=1
|
||||||
|
|
||||||
FIRE_ENGINE_BETA_URL= # set if you'd like to use the fire engine closed beta
|
# set if you'd like to use the fire engine closed beta
|
||||||
|
FIRE_ENGINE_BETA_URL=
|
||||||
|
|
||||||
# Proxy Settings for Playwright (Alternative you can can use a proxy service like oxylabs, which rotates IPs for you on every request)
|
# Proxy Settings for Playwright (Alternative you can can use a proxy service like oxylabs, which rotates IPs for you on every request)
|
||||||
PROXY_SERVER=
|
PROXY_SERVER=
|
||||||
|
|
@ -56,3 +72,14 @@ SELF_HOSTED_WEBHOOK_URL=
|
||||||
|
|
||||||
# Resend API Key for transactional emails
|
# Resend API Key for transactional emails
|
||||||
RESEND_API_KEY=
|
RESEND_API_KEY=
|
||||||
|
|
||||||
|
# LOGGING_LEVEL determines the verbosity of logs that the system will output.
|
||||||
|
# Available levels are:
|
||||||
|
# NONE - No logs will be output.
|
||||||
|
# ERROR - For logging error messages that indicate a failure in a specific operation.
|
||||||
|
# WARN - For logging potentially harmful situations that are not necessarily errors.
|
||||||
|
# INFO - For logging informational messages that highlight the progress of the application.
|
||||||
|
# DEBUG - For logging detailed information on the flow through the system, primarily used for debugging.
|
||||||
|
# TRACE - For logging more detailed information than the DEBUG level.
|
||||||
|
# Set LOGGING_LEVEL to one of the above options to control logging output.
|
||||||
|
LOGGING_LEVEL=INFO
|
||||||
|
|
|
||||||
|
|
@ -5,10 +5,11 @@ SUPABASE_ANON_TOKEN=
|
||||||
SUPABASE_URL=
|
SUPABASE_URL=
|
||||||
SUPABASE_SERVICE_TOKEN=
|
SUPABASE_SERVICE_TOKEN=
|
||||||
REDIS_URL=
|
REDIS_URL=
|
||||||
|
REDIS_RATE_LIMIT_URL=
|
||||||
SCRAPING_BEE_API_KEY=
|
SCRAPING_BEE_API_KEY=
|
||||||
OPENAI_API_KEY=
|
OPENAI_API_KEY=
|
||||||
ANTHROPIC_API_KEY=
|
ANTHROPIC_API_KEY=
|
||||||
BULL_AUTH_KEY=
|
BULL_AUTH_KEY=
|
||||||
LOGTAIL_KEY=
|
LOGTAIL_KEY=
|
||||||
PLAYWRIGHT_MICROSERVICE_URL=
|
PLAYWRIGHT_MICROSERVICE_URL=
|
||||||
|
SEARCHAPI_API_KEY=
|
||||||
|
|
|
||||||
5
apps/api/.gitignore
vendored
5
apps/api/.gitignore
vendored
|
|
@ -4,3 +4,8 @@
|
||||||
*.csv
|
*.csv
|
||||||
dump.rdb
|
dump.rdb
|
||||||
/mongo-data
|
/mongo-data
|
||||||
|
|
||||||
|
/.next/
|
||||||
|
|
||||||
|
.rdb
|
||||||
|
.sentryclirc
|
||||||
|
|
|
||||||
|
|
@ -12,25 +12,31 @@ RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-l
|
||||||
FROM base AS build
|
FROM base AS build
|
||||||
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile
|
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --frozen-lockfile
|
||||||
|
|
||||||
|
RUN apt-get update -qq && apt-get install -y ca-certificates && update-ca-certificates
|
||||||
RUN pnpm install
|
RUN pnpm install
|
||||||
RUN pnpm run build
|
RUN --mount=type=secret,id=SENTRY_AUTH_TOKEN \
|
||||||
|
bash -c 'export SENTRY_AUTH_TOKEN="$(cat /run/secrets/SENTRY_AUTH_TOKEN)"; if [ -z $SENTRY_AUTH_TOKEN ]; then pnpm run build:nosentry; else pnpm run build; fi'
|
||||||
|
|
||||||
# Install packages needed for deployment
|
# Install Go
|
||||||
|
FROM golang:1.19 AS go-base
|
||||||
|
COPY sharedLibs/go-html-to-md /app/sharedLibs/go-html-to-md
|
||||||
|
|
||||||
|
# Install Go dependencies and build parser lib
|
||||||
|
RUN cd /app/sharedLibs/go-html-to-md && \
|
||||||
|
go mod tidy && \
|
||||||
|
go build -o html-to-markdown.so -buildmode=c-shared html-to-markdown.go && \
|
||||||
|
chmod +x html-to-markdown.so
|
||||||
|
|
||||||
FROM base
|
FROM base
|
||||||
RUN apt-get update -qq && \
|
|
||||||
apt-get install --no-install-recommends -y chromium chromium-sandbox && \
|
|
||||||
rm -rf /var/lib/apt/lists /var/cache/apt/archives
|
|
||||||
COPY --from=prod-deps /app/node_modules /app/node_modules
|
COPY --from=prod-deps /app/node_modules /app/node_modules
|
||||||
COPY --from=build /app /app
|
COPY --from=build /app /app
|
||||||
|
COPY --from=go-base /app/sharedLibs/go-html-to-md/html-to-markdown.so /app/sharedLibs/go-html-to-md/html-to-markdown.so
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# Start the server by default, this can be overwritten at runtime
|
# Start the server by default, this can be overwritten at runtime
|
||||||
EXPOSE 8080
|
EXPOSE 8080
|
||||||
ENV PUPPETEER_EXECUTABLE_PATH="/usr/bin/chromium"
|
ENV PUPPETEER_EXECUTABLE_PATH="/usr/bin/chromium"
|
||||||
CMD [ "pnpm", "run", "start:production" ]
|
|
||||||
CMD [ "pnpm", "run", "worker:production" ]
|
|
||||||
|
|
||||||
|
# Make sure the entrypoint script has the correct line endings
|
||||||
|
RUN sed -i 's/\r$//' /app/docker-entrypoint.sh
|
||||||
|
|
||||||
|
ENTRYPOINT "/app/docker-entrypoint.sh"
|
||||||
19
apps/api/docker-entrypoint.sh
Executable file
19
apps/api/docker-entrypoint.sh
Executable file
|
|
@ -0,0 +1,19 @@
|
||||||
|
#!/bin/bash -e
|
||||||
|
|
||||||
|
if [ $UID -eq 0 ]; then
|
||||||
|
ulimit -n 65535
|
||||||
|
echo "NEW ULIMIT: $(ulimit -n)"
|
||||||
|
else
|
||||||
|
echo ENTRYPOINT DID NOT RUN AS ROOT
|
||||||
|
fi
|
||||||
|
|
||||||
|
if [ $FLY_PROCESS_GROUP = "app" ]; then
|
||||||
|
echo "RUNNING app"
|
||||||
|
node --max-old-space-size=8192 dist/src/index.js
|
||||||
|
elif [ $FLY_PROCESS_GROUP = "worker" ]; then
|
||||||
|
echo "RUNNING worker"
|
||||||
|
node --max-old-space-size=8192 dist/src/services/queue-worker.js
|
||||||
|
else
|
||||||
|
echo "NO FLY PROCESS GROUP"
|
||||||
|
node --max-old-space-size=8192 dist/src/index.js
|
||||||
|
fi
|
||||||
66
apps/api/fly.staging.toml
Normal file
66
apps/api/fly.staging.toml
Normal file
|
|
@ -0,0 +1,66 @@
|
||||||
|
# fly.toml app configuration file generated for firecrawl-scraper-js on 2024-04-07T21:09:59-03:00
|
||||||
|
#
|
||||||
|
# See https://fly.io/docs/reference/configuration/ for information about how to use this file.
|
||||||
|
#
|
||||||
|
|
||||||
|
app = 'staging-firecrawl-scraper-js'
|
||||||
|
primary_region = 'mia'
|
||||||
|
kill_signal = 'SIGINT'
|
||||||
|
kill_timeout = '30s'
|
||||||
|
|
||||||
|
[build]
|
||||||
|
|
||||||
|
[processes]
|
||||||
|
app = 'node dist/src/index.js'
|
||||||
|
worker = 'node dist/src/services/queue-worker.js'
|
||||||
|
|
||||||
|
[http_service]
|
||||||
|
internal_port = 8080
|
||||||
|
force_https = true
|
||||||
|
auto_stop_machines = true
|
||||||
|
auto_start_machines = true
|
||||||
|
min_machines_running = 2
|
||||||
|
processes = ['app']
|
||||||
|
|
||||||
|
[http_service.concurrency]
|
||||||
|
type = "requests"
|
||||||
|
# hard_limit = 100
|
||||||
|
soft_limit = 100
|
||||||
|
|
||||||
|
[[http_service.checks]]
|
||||||
|
grace_period = "10s"
|
||||||
|
interval = "30s"
|
||||||
|
method = "GET"
|
||||||
|
timeout = "5s"
|
||||||
|
path = "/"
|
||||||
|
|
||||||
|
|
||||||
|
[[services]]
|
||||||
|
protocol = 'tcp'
|
||||||
|
internal_port = 8080
|
||||||
|
processes = ['worker']
|
||||||
|
|
||||||
|
[[services.ports]]
|
||||||
|
port = 80
|
||||||
|
handlers = ['http']
|
||||||
|
force_https = true
|
||||||
|
|
||||||
|
[[services.ports]]
|
||||||
|
port = 443
|
||||||
|
handlers = ['tls', 'http']
|
||||||
|
|
||||||
|
[services.concurrency]
|
||||||
|
type = 'connections'
|
||||||
|
# hard_limit = 25
|
||||||
|
soft_limit = 100
|
||||||
|
|
||||||
|
[[vm]]
|
||||||
|
size = 'performance-2x'
|
||||||
|
processes = ['app','worker']
|
||||||
|
memory = 8192
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
@ -4,15 +4,15 @@
|
||||||
#
|
#
|
||||||
|
|
||||||
app = 'firecrawl-scraper-js'
|
app = 'firecrawl-scraper-js'
|
||||||
primary_region = 'mia'
|
primary_region = 'iad'
|
||||||
kill_signal = 'SIGINT'
|
kill_signal = 'SIGINT'
|
||||||
kill_timeout = '5s'
|
kill_timeout = '30s'
|
||||||
|
|
||||||
[build]
|
[build]
|
||||||
|
|
||||||
[processes]
|
[processes]
|
||||||
app = 'npm run start:production'
|
app = 'node --max-old-space-size=8192 dist/src/index.js'
|
||||||
worker = 'npm run worker:production'
|
worker = 'node --max-old-space-size=8192 dist/src/services/queue-worker.js'
|
||||||
|
|
||||||
[http_service]
|
[http_service]
|
||||||
internal_port = 8080
|
internal_port = 8080
|
||||||
|
|
@ -24,8 +24,8 @@ kill_timeout = '5s'
|
||||||
|
|
||||||
[http_service.concurrency]
|
[http_service.concurrency]
|
||||||
type = "requests"
|
type = "requests"
|
||||||
hard_limit = 100
|
# hard_limit = 200
|
||||||
soft_limit = 50
|
soft_limit = 200
|
||||||
|
|
||||||
[[http_service.checks]]
|
[[http_service.checks]]
|
||||||
grace_period = "20s"
|
grace_period = "20s"
|
||||||
|
|
@ -50,8 +50,8 @@ kill_timeout = '5s'
|
||||||
|
|
||||||
[services.concurrency]
|
[services.concurrency]
|
||||||
type = 'connections'
|
type = 'connections'
|
||||||
hard_limit = 30
|
# hard_limit = 30
|
||||||
soft_limit = 12
|
soft_limit = 200
|
||||||
|
|
||||||
[[vm]]
|
[[vm]]
|
||||||
size = 'performance-4x'
|
size = 'performance-4x'
|
||||||
|
|
|
||||||
924
apps/api/openapi-v0.json
Normal file
924
apps/api/openapi-v0.json
Normal file
|
|
@ -0,0 +1,924 @@
|
||||||
|
{
|
||||||
|
"openapi": "3.0.0",
|
||||||
|
"info": {
|
||||||
|
"title": "Firecrawl API",
|
||||||
|
"version": "0.0.0",
|
||||||
|
"description": "API for interacting with Firecrawl services to perform web scraping and crawling tasks.",
|
||||||
|
"contact": {
|
||||||
|
"name": "Firecrawl Support",
|
||||||
|
"url": "https://firecrawl.dev/support",
|
||||||
|
"email": "support@firecrawl.dev"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"servers": [
|
||||||
|
{
|
||||||
|
"url": "https://api.firecrawl.dev/v0"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"paths": {
|
||||||
|
"/scrape": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Scrape a single URL and optionally extract information using an LLM",
|
||||||
|
"operationId": "scrapeAndExtractFromUrl",
|
||||||
|
"tags": ["Scraping"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The URL to scrape"
|
||||||
|
},
|
||||||
|
"pageOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"includeHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the HTML version of the content on page. Will output a html key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"includeRawHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the raw HTML content of the page. Will output a rawHtml key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"onlyIncludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Only include tags, classes and ids from the page in the final output. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"removeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags, classes and ids to remove from the page. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
|
},
|
||||||
|
"replaceAllPathsWithAbsolutePaths": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Replace all relative paths with absolute paths for images and links",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a screenshot of the top of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"fullPageScreenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a full page screenshot of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"extractorOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Options for extraction of structured information from the page content. Note: LLM-based extraction is not performed by default and only occurs when explicitly configured. The 'markdown' mode simply returns the scraped markdown and is the default mode for scraping.",
|
||||||
|
"default": {},
|
||||||
|
"properties": {
|
||||||
|
"mode": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "llm-extraction", "llm-extraction-from-raw-html", "llm-extraction-from-markdown"],
|
||||||
|
"description": "The extraction mode to use. 'markdown': Returns the scraped markdown content, does not perform LLM extraction. 'llm-extraction': Extracts information from the cleaned and parsed content using LLM. 'llm-extraction-from-raw-html': Extracts information directly from the raw HTML using LLM. 'llm-extraction-from-markdown': Extracts information from the markdown content using LLM."
|
||||||
|
},
|
||||||
|
"extractionPrompt": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "A prompt describing what information to extract from the page, applicable for LLM extraction modes."
|
||||||
|
},
|
||||||
|
"extractionSchema": {
|
||||||
|
"type": "object",
|
||||||
|
"additionalProperties": true,
|
||||||
|
"description": "The schema for the data to be extracted, required only for LLM extraction modes.",
|
||||||
|
"required": [
|
||||||
|
"company_mission",
|
||||||
|
"supports_sso",
|
||||||
|
"is_open_source"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"timeout": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Timeout in milliseconds for the request",
|
||||||
|
"default": 30000
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/ScrapeResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Crawl multiple URLs based on options",
|
||||||
|
"operationId": "crawlUrls",
|
||||||
|
"tags": ["Crawling"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The base URL to start crawling from"
|
||||||
|
},
|
||||||
|
"crawlerOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"includes": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to include"
|
||||||
|
},
|
||||||
|
"excludes": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "URL patterns to exclude"
|
||||||
|
},
|
||||||
|
"generateImgAltText": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Generate alt text for images using LLMs (must have a paid plan)",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"returnOnlyUrls": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "If true, returns only the URLs as a list on the crawl status. Attention: the return response will be a list of URLs inside the data, not a list of documents.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"maxDepth": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum depth to crawl relative to the entered URL. A maxDepth of 0 scrapes only the entered URL. A maxDepth of 1 scrapes the entered URL and all pages one level deep. A maxDepth of 2 scrapes the entered URL and all pages up to two levels deep. Higher values follow the same pattern."
|
||||||
|
},
|
||||||
|
"mode": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["default", "fast"],
|
||||||
|
"description": "The crawling mode to use. Fast mode crawls 4x faster websites without sitemap, but may not be as accurate and shouldn't be used in heavy js-rendered websites.",
|
||||||
|
"default": "default"
|
||||||
|
},
|
||||||
|
"ignoreSitemap": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Ignore the website sitemap when crawling",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of pages to crawl",
|
||||||
|
"default": 10000
|
||||||
|
},
|
||||||
|
"allowBackwardCrawling": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Enables the crawler to navigate from a specific URL to previously linked pages. For instance, from 'example.com/product/123' back to 'example.com/product'",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"allowExternalContentLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Allows the crawler to follow links to external websites.",
|
||||||
|
"default": false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"pageOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"includeHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the HTML version of the content on page. Will output a html key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"includeRawHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the raw HTML content of the page. Will output a rawHtml key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"onlyIncludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Only include tags, classes and ids from the page in the final output. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
|
},
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"removeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Tags, classes and ids to remove from the page. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
|
},
|
||||||
|
"replaceAllPathsWithAbsolutePaths": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Replace all relative paths with absolute paths for images and links",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a screenshot of the top of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"fullPageScreenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a full page screenshot of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 0
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["url"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/CrawlResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/search": {
|
||||||
|
"post": {
|
||||||
|
"summary": "Search for a keyword in Google, returns top page results with markdown content for each page",
|
||||||
|
"operationId": "searchGoogle",
|
||||||
|
"tags": ["Search"],
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"requestBody": {
|
||||||
|
"required": true,
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"query": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri",
|
||||||
|
"description": "The query to search for"
|
||||||
|
},
|
||||||
|
"pageOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"onlyMainContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"fetchPageContent": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Fetch the content of each page. If false, defaults to a basic fast serp API.",
|
||||||
|
"default": true
|
||||||
|
},
|
||||||
|
"includeHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the HTML version of the content on page. Will output a html key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"includeRawHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the raw HTML content of the page. Will output a rawHtml key in the response.",
|
||||||
|
"default": false
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"searchOptions": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"limit": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Maximum number of results. Max is 20 during beta."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"required": ["query"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"$ref": "#/components/schemas/SearchResponse"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl/status/{jobId}": {
|
||||||
|
"get": {
|
||||||
|
"tags": ["Crawl"],
|
||||||
|
"summary": "Get the status of a crawl job",
|
||||||
|
"operationId": "getCrawlStatus",
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"parameters": [
|
||||||
|
{
|
||||||
|
"name": "jobId",
|
||||||
|
"in": "path",
|
||||||
|
"description": "ID of the crawl job",
|
||||||
|
"required": true,
|
||||||
|
"schema": {
|
||||||
|
"type": "string"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"status": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "Status of the job (completed, active, failed, paused)"
|
||||||
|
},
|
||||||
|
"current": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Current page number"
|
||||||
|
},
|
||||||
|
"total": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Total number of pages"
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
||||||
|
},
|
||||||
|
"description": "Data returned from the job (null when it is in progress)"
|
||||||
|
},
|
||||||
|
"partial_data": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
||||||
|
},
|
||||||
|
"description": "Partial documents returned as it is being crawled (streaming). **This feature is currently in alpha - expect breaking changes** When a page is ready, it will append to the partial_data array, so there is no need to wait for the entire website to be crawled. When the crawl is done, partial_data will become empty and the result will be available in `data`. There is a max of 50 items in the array response. The oldest item (top of the array) will be removed when the new item is added to the array."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"/crawl/cancel/{jobId}": {
|
||||||
|
"delete": {
|
||||||
|
"tags": ["Crawl"],
|
||||||
|
"summary": "Cancel a crawl job",
|
||||||
|
"operationId": "cancelCrawlJob",
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"parameters": [
|
||||||
|
{
|
||||||
|
"name": "jobId",
|
||||||
|
"in": "path",
|
||||||
|
"description": "ID of the crawl job",
|
||||||
|
"required": true,
|
||||||
|
"schema": {
|
||||||
|
"type": "string"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"responses": {
|
||||||
|
"200": {
|
||||||
|
"description": "Successful response",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"status": {
|
||||||
|
"type": "string",
|
||||||
|
"description": "Returns cancelled."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"402": {
|
||||||
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"429": {
|
||||||
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"500": {
|
||||||
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"components": {
|
||||||
|
"securitySchemes": {
|
||||||
|
"bearerAuth": {
|
||||||
|
"type": "http",
|
||||||
|
"scheme": "bearer"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"schemas": {
|
||||||
|
"ScrapeResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `includeHtml` is true"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `includeRawHtml` is true"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"pageStatusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"pageError": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"llm_extraction": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Displayed when using LLM Extraction. Extracted data from the page following the schema defined.",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"warning": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Can be displayed when using LLM Extraction. Warning message will let you know any issues with the extraction."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlStatusResponseObj": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"html": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if `includeHtml` is true"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if `includeRawHtml` is true"
|
||||||
|
},
|
||||||
|
"index": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The number of the page that was crawled. This is useful for `partial_data` so you know which page the data is from."
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"pageStatusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"pageError": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"SearchResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"data": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"url": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"markdown": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"content": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"metadata": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"title": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"language": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true
|
||||||
|
},
|
||||||
|
"sourceURL": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"CrawlResponse": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"jobId": {
|
||||||
|
"type": "string"
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"security": [
|
||||||
|
{
|
||||||
|
"bearerAuth": []
|
||||||
|
}
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
@ -18,8 +18,8 @@
|
||||||
"paths": {
|
"paths": {
|
||||||
"/scrape": {
|
"/scrape": {
|
||||||
"post": {
|
"post": {
|
||||||
"summary": "Scrape a single URL and optionally extract information using an LLM",
|
"summary": "Scrape a single URL",
|
||||||
"operationId": "scrapeAndExtractFromUrl",
|
"operationId": "scrape",
|
||||||
"tags": ["Scraping"],
|
"tags": ["Scraping"],
|
||||||
"security": [
|
"security": [
|
||||||
{
|
{
|
||||||
|
|
@ -38,71 +38,47 @@
|
||||||
"format": "uri",
|
"format": "uri",
|
||||||
"description": "The URL to scrape"
|
"description": "The URL to scrape"
|
||||||
},
|
},
|
||||||
"pageOptions": {
|
"formats": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"enum": ["markdown", "html", "rawHtml", "links", "screenshot", "screenshot@fullPage"]
|
||||||
|
},
|
||||||
|
"description": "Specific formats to return.\n\n - markdown: The page in Markdown format.\n - html: The page's HTML, trimmed to include only meaningful content.\n - rawHtml: The page's original HTML.\n - links: The links on the page.\n - screenshot: A screenshot of the top of the page.\n - screenshot@fullPage: A screenshot of the full page. (overridden by screenshot if present)",
|
||||||
|
"default": ["markdown"]
|
||||||
|
},
|
||||||
|
"headers": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
"onlyMainContent": {
|
|
||||||
"type": "boolean",
|
|
||||||
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
|
||||||
"default": false
|
|
||||||
},
|
},
|
||||||
"includeHtml": {
|
"includeTags": {
|
||||||
"type": "boolean",
|
"type": "array",
|
||||||
"description": "Include the raw HTML content of the page. Will output a html key in the response.",
|
"items": {
|
||||||
"default": false
|
"type": "string"
|
||||||
},
|
},
|
||||||
"screenshot": {
|
"description": "Only include tags, classes and ids from the page in the final output. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
"type": "boolean",
|
|
||||||
"description": "Include a screenshot of the top of the page that you are scraping.",
|
|
||||||
"default": false
|
|
||||||
},
|
},
|
||||||
"waitFor": {
|
"excludeTags": {
|
||||||
"type": "integer",
|
|
||||||
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
|
||||||
"default": 0
|
|
||||||
},
|
|
||||||
"removeTags": {
|
|
||||||
"type": "array",
|
"type": "array",
|
||||||
"items": {
|
"items": {
|
||||||
"type": "string"
|
"type": "string"
|
||||||
},
|
},
|
||||||
"description": "Tags, classes and ids to remove from the page. Use comma separated values. Example: 'script, .ad, #footer'"
|
"description": "Tags, classes and ids to remove from the page. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
},
|
},
|
||||||
"headers": {
|
"onlyMainContent": {
|
||||||
"type": "object",
|
"type": "boolean",
|
||||||
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
}
|
"default": true
|
||||||
}
|
|
||||||
},
|
|
||||||
"extractorOptions": {
|
|
||||||
"type": "object",
|
|
||||||
"description": "Options for LLM-based extraction of structured information from the page content",
|
|
||||||
"properties": {
|
|
||||||
"mode": {
|
|
||||||
"type": "string",
|
|
||||||
"enum": ["llm-extraction"],
|
|
||||||
"description": "The extraction mode to use, currently supports 'llm-extraction'"
|
|
||||||
},
|
|
||||||
"extractionPrompt": {
|
|
||||||
"type": "string",
|
|
||||||
"description": "A prompt describing what information to extract from the page"
|
|
||||||
},
|
|
||||||
"extractionSchema": {
|
|
||||||
"type": "object",
|
|
||||||
"additionalProperties": true,
|
|
||||||
"description": "The schema for the data to be extracted",
|
|
||||||
"required": [
|
|
||||||
"company_mission",
|
|
||||||
"supports_sso",
|
|
||||||
"is_open_source"
|
|
||||||
]
|
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
},
|
||||||
"timeout": {
|
"timeout": {
|
||||||
"type": "integer",
|
"type": "integer",
|
||||||
"description": "Timeout in milliseconds for the request",
|
"description": "Timeout in milliseconds for the request",
|
||||||
"default": 30000
|
"default": 30000
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 0
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"required": ["url"]
|
"required": ["url"]
|
||||||
|
|
@ -122,13 +98,52 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"402": {
|
"402": {
|
||||||
"description": "Payment required"
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"429": {
|
"429": {
|
||||||
"description": "Too many requests"
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"500": {
|
"500": {
|
||||||
"description": "Server error"
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -184,7 +199,7 @@
|
||||||
},
|
},
|
||||||
"maxDepth": {
|
"maxDepth": {
|
||||||
"type": "integer",
|
"type": "integer",
|
||||||
"description": "Maximum depth to crawl. Depth 1 is the base URL, depth 2 is the base URL and its direct children, and so on."
|
"description": "Maximum depth to crawl relative to the entered URL. A maxDepth of 0 scrapes only the entered URL. A maxDepth of 1 scrapes the entered URL and all pages one level deep. A maxDepth of 2 scrapes the entered URL and all pages up to two levels deep. Higher values follow the same pattern."
|
||||||
},
|
},
|
||||||
"mode": {
|
"mode": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
|
|
@ -204,7 +219,12 @@
|
||||||
},
|
},
|
||||||
"allowBackwardCrawling": {
|
"allowBackwardCrawling": {
|
||||||
"type": "boolean",
|
"type": "boolean",
|
||||||
"description": "Allow backward crawling (crawl from the base URL to the previous URLs)",
|
"description": "Enables the crawler to navigate from a specific URL to previously linked pages. For instance, from 'example.com/product/123' back to 'example.com/product'",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"allowExternalContentLinks": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Allows the crawler to follow links to external websites.",
|
||||||
"default": false
|
"default": false
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -212,25 +232,32 @@
|
||||||
"pageOptions": {
|
"pageOptions": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
|
"headers": {
|
||||||
|
"type": "object",
|
||||||
|
"description": "Headers to send with the request. Can be used to send cookies, user-agent, etc."
|
||||||
|
},
|
||||||
|
"includeHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the HTML version of the content on page. Will output a html key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"includeRawHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the raw HTML content of the page. Will output a rawHtml key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"onlyIncludeTags": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"description": "Only include tags, classes and ids from the page in the final output. Use comma separated values. Example: 'script, .ad, #footer'"
|
||||||
|
},
|
||||||
"onlyMainContent": {
|
"onlyMainContent": {
|
||||||
"type": "boolean",
|
"type": "boolean",
|
||||||
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
"description": "Only return the main content of the page excluding headers, navs, footers, etc.",
|
||||||
"default": false
|
"default": false
|
||||||
},
|
},
|
||||||
"includeHtml": {
|
|
||||||
"type": "boolean",
|
|
||||||
"description": "Include the raw HTML content of the page. Will output a html key in the response.",
|
|
||||||
"default": false
|
|
||||||
},
|
|
||||||
"screenshot": {
|
|
||||||
"type": "boolean",
|
|
||||||
"description": "Include a screenshot of the top of the page that you are scraping.",
|
|
||||||
"default": false
|
|
||||||
},
|
|
||||||
"headers": {
|
|
||||||
"type": "object",
|
|
||||||
"description": "Headers to send with the request when scraping. Can be used to send cookies, user-agent, etc."
|
|
||||||
},
|
|
||||||
"removeTags": {
|
"removeTags": {
|
||||||
"type": "array",
|
"type": "array",
|
||||||
"items": {
|
"items": {
|
||||||
|
|
@ -242,6 +269,21 @@
|
||||||
"type": "boolean",
|
"type": "boolean",
|
||||||
"description": "Replace all relative paths with absolute paths for images and links",
|
"description": "Replace all relative paths with absolute paths for images and links",
|
||||||
"default": false
|
"default": false
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a screenshot of the top of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"fullPageScreenshot": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include a full page screenshot of the page that you are scraping.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"waitFor": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "Wait x amount of milliseconds for the page to load to fetch content",
|
||||||
|
"default": 0
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -263,13 +305,52 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"402": {
|
"402": {
|
||||||
"description": "Payment required"
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"429": {
|
"429": {
|
||||||
"description": "Too many requests"
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"500": {
|
"500": {
|
||||||
"description": "Server error"
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -311,7 +392,12 @@
|
||||||
},
|
},
|
||||||
"includeHtml": {
|
"includeHtml": {
|
||||||
"type": "boolean",
|
"type": "boolean",
|
||||||
"description": "Include the raw HTML content of the page. Will output a html key in the response.",
|
"description": "Include the HTML version of the content on page. Will output a html key in the response.",
|
||||||
|
"default": false
|
||||||
|
},
|
||||||
|
"includeRawHtml": {
|
||||||
|
"type": "boolean",
|
||||||
|
"description": "Include the raw HTML content of the page. Will output a rawHtml key in the response.",
|
||||||
"default": false
|
"default": false
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -343,13 +429,52 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"402": {
|
"402": {
|
||||||
"description": "Payment required"
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"429": {
|
"429": {
|
||||||
"description": "Too many requests"
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"500": {
|
"500": {
|
||||||
"description": "Server error"
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -391,14 +516,6 @@
|
||||||
"type": "integer",
|
"type": "integer",
|
||||||
"description": "Current page number"
|
"description": "Current page number"
|
||||||
},
|
},
|
||||||
"current_url": {
|
|
||||||
"type": "string",
|
|
||||||
"description": "Current URL being scraped"
|
|
||||||
},
|
|
||||||
"current_step": {
|
|
||||||
"type": "string",
|
|
||||||
"description": "Current step in the process"
|
|
||||||
},
|
|
||||||
"total": {
|
"total": {
|
||||||
"type": "integer",
|
"type": "integer",
|
||||||
"description": "Total number of pages"
|
"description": "Total number of pages"
|
||||||
|
|
@ -415,7 +532,7 @@
|
||||||
"items": {
|
"items": {
|
||||||
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
"$ref": "#/components/schemas/CrawlStatusResponseObj"
|
||||||
},
|
},
|
||||||
"description": "Partial documents returned as it is being crawled (streaming). **This feature is currently in alpha - expect breaking changes** When a page is ready, it will append to the partial_data array, so there is no need to wait for the entire website to be crawled. There is a max of 50 items in the array response. The oldest item (top of the array) will be removed when the new item is added to the array."
|
"description": "Partial documents returned as it is being crawled (streaming). **This feature is currently in alpha - expect breaking changes** When a page is ready, it will append to the partial_data array, so there is no need to wait for the entire website to be crawled. When the crawl is done, partial_data will become empty and the result will be available in `data`. There is a max of 50 items in the array response. The oldest item (top of the array) will be removed when the new item is added to the array."
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -423,13 +540,52 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"402": {
|
"402": {
|
||||||
"description": "Payment required"
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"429": {
|
"429": {
|
||||||
"description": "Too many requests"
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"500": {
|
"500": {
|
||||||
"description": "Server error"
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -473,13 +629,52 @@
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
"402": {
|
"402": {
|
||||||
"description": "Payment required"
|
"description": "Payment required",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Payment required to access this resource."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"429": {
|
"429": {
|
||||||
"description": "Too many requests"
|
"description": "Too many requests",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "Request rate limit exceeded. Please wait and try again later."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
},
|
},
|
||||||
"500": {
|
"500": {
|
||||||
"description": "Server error"
|
"description": "Server error",
|
||||||
|
"content": {
|
||||||
|
"application/json": {
|
||||||
|
"schema": {
|
||||||
|
"type": "object",
|
||||||
|
"properties": {
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"example": "An unexpected error occurred on the server."
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -499,19 +694,42 @@
|
||||||
"success": {
|
"success": {
|
||||||
"type": "boolean"
|
"type": "boolean"
|
||||||
},
|
},
|
||||||
|
"warning": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Warning message to let you know of any issues."
|
||||||
|
},
|
||||||
"data": {
|
"data": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
"markdown": {
|
"markdown": {
|
||||||
"type": "string"
|
"type": "string",
|
||||||
},
|
"nullable": true,
|
||||||
"content": {
|
"description": "Markdown content of the page if the `markdown` format was specified (default)"
|
||||||
"type": "string"
|
|
||||||
},
|
},
|
||||||
"html": {
|
"html": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"nullable": true,
|
"nullable": true,
|
||||||
"description": "Raw HTML content of the page if `includeHtml` is true"
|
"description": "HTML version of the content on page if the `html` format was specified"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if the `rawHtml` format was specified"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Links on the page if the `links` format was specified"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "URL of the screenshot of the page if the `screenshot` or `screenshot@fullSize` format was specified"
|
||||||
},
|
},
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
|
|
@ -529,18 +747,20 @@
|
||||||
"sourceURL": {
|
"sourceURL": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"format": "uri"
|
"format": "uri"
|
||||||
}
|
|
||||||
}
|
|
||||||
},
|
},
|
||||||
"llm_extraction": {
|
"<any other metadata> ": {
|
||||||
"type": "object",
|
"type": "string"
|
||||||
"description": "Displayed when using LLM Extraction. Extracted data from the page following the schema defined.",
|
|
||||||
"nullable": true
|
|
||||||
},
|
},
|
||||||
"warning": {
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"nullable": true,
|
"nullable": true,
|
||||||
"description": "Can be displayed when using LLM Extraction. Warning message will let you know any issues with the extraction."
|
"description": "The error message of the page"
|
||||||
|
}
|
||||||
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -550,19 +770,33 @@
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
"markdown": {
|
"markdown": {
|
||||||
"type": "string"
|
"type": "string",
|
||||||
},
|
"nullable": true,
|
||||||
"content": {
|
"description": "Markdown content of the page if the `markdown` format was specified (default)"
|
||||||
"type": "string"
|
|
||||||
},
|
},
|
||||||
"html": {
|
"html": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"nullable": true,
|
"nullable": true,
|
||||||
"description": "Raw HTML content of the page if `includeHtml` is true"
|
"description": "HTML version of the content on page if the `html` format was specified"
|
||||||
},
|
},
|
||||||
"index": {
|
"rawHtml": {
|
||||||
"type": "integer",
|
"type": "string",
|
||||||
"description": "The number of the page that was crawled. This is useful for `partial_data` so you know which page the data is from."
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if the `rawHtml` format was specified"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Links on the page if the `links` format was specified"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "URL of the screenshot of the page if the `screenshot` or `screenshot@fullSize` format was specified"
|
||||||
},
|
},
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
|
|
@ -580,6 +814,18 @@
|
||||||
"sourceURL": {
|
"sourceURL": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"format": "uri"
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -594,16 +840,34 @@
|
||||||
"data": {
|
"data": {
|
||||||
"type": "array",
|
"type": "array",
|
||||||
"items": {
|
"items": {
|
||||||
"type": "object",
|
|
||||||
"properties": {
|
|
||||||
"url": {
|
|
||||||
"type": "string"
|
|
||||||
},
|
|
||||||
"markdown": {
|
"markdown": {
|
||||||
"type": "string"
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Markdown content of the page if the `markdown` format was specified (default)"
|
||||||
},
|
},
|
||||||
"content": {
|
"html": {
|
||||||
"type": "string"
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "HTML version of the content on page if the `html` format was specified"
|
||||||
|
},
|
||||||
|
"rawHtml": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Raw HTML content of the page if the `rawHtml` format was specified"
|
||||||
|
},
|
||||||
|
"links": {
|
||||||
|
"type": "array",
|
||||||
|
"items": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
|
},
|
||||||
|
"nullable": true,
|
||||||
|
"description": "Links on the page if the `links` format was specified"
|
||||||
|
},
|
||||||
|
"screenshot": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "URL of the screenshot of the page if the `screenshot` or `screenshot@fullSize` format was specified"
|
||||||
},
|
},
|
||||||
"metadata": {
|
"metadata": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
|
|
@ -621,7 +885,18 @@
|
||||||
"sourceURL": {
|
"sourceURL": {
|
||||||
"type": "string",
|
"type": "string",
|
||||||
"format": "uri"
|
"format": "uri"
|
||||||
}
|
},
|
||||||
|
"<any other metadata> ": {
|
||||||
|
"type": "string"
|
||||||
|
},
|
||||||
|
"statusCode": {
|
||||||
|
"type": "integer",
|
||||||
|
"description": "The status code of the page"
|
||||||
|
},
|
||||||
|
"error": {
|
||||||
|
"type": "string",
|
||||||
|
"nullable": true,
|
||||||
|
"description": "The error message of the page"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -632,8 +907,15 @@
|
||||||
"CrawlResponse": {
|
"CrawlResponse": {
|
||||||
"type": "object",
|
"type": "object",
|
||||||
"properties": {
|
"properties": {
|
||||||
"jobId": {
|
"success": {
|
||||||
|
"type": "boolean"
|
||||||
|
},
|
||||||
|
"id": {
|
||||||
"type": "string"
|
"type": "string"
|
||||||
|
},
|
||||||
|
"url": {
|
||||||
|
"type": "string",
|
||||||
|
"format": "uri"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -9,23 +9,28 @@
|
||||||
"format": "prettier --write \"src/**/*.(js|ts)\"",
|
"format": "prettier --write \"src/**/*.(js|ts)\"",
|
||||||
"flyio": "node dist/src/index.js",
|
"flyio": "node dist/src/index.js",
|
||||||
"start:dev": "nodemon --exec ts-node src/index.ts",
|
"start:dev": "nodemon --exec ts-node src/index.ts",
|
||||||
"build": "tsc",
|
"build": "tsc && pnpm sentry:sourcemaps",
|
||||||
|
"build:nosentry": "tsc",
|
||||||
"test": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='src/__tests__/e2e_noAuth/*'",
|
"test": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='src/__tests__/e2e_noAuth/*'",
|
||||||
"test:local-no-auth": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='src/__tests__/e2e_withAuth/*'",
|
"test:local-no-auth": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='src/__tests__/e2e_withAuth/*'",
|
||||||
"test:prod": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='src/__tests__/e2e_noAuth/*'",
|
"test:full": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='(src/__tests__/e2e_noAuth|src/__tests__/e2e_withAuth)'",
|
||||||
|
"test:prod": "npx jest --detectOpenHandles --forceExit --openHandlesTimeout=120000 --watchAll=false --testPathIgnorePatterns='(src/__tests__/e2e_noAuth|src/__tests__/e2e_full_withAuth)'",
|
||||||
"workers": "nodemon --exec ts-node src/services/queue-worker.ts",
|
"workers": "nodemon --exec ts-node src/services/queue-worker.ts",
|
||||||
"worker:production": "node dist/src/services/queue-worker.js",
|
"worker:production": "node dist/src/services/queue-worker.js",
|
||||||
"mongo-docker": "docker run -d -p 2717:27017 -v ./mongo-data:/data/db --name mongodb mongo:latest",
|
"mongo-docker": "docker run -d -p 2717:27017 -v ./mongo-data:/data/db --name mongodb mongo:latest",
|
||||||
"mongo-docker-console": "docker exec -it mongodb mongosh",
|
"mongo-docker-console": "docker exec -it mongodb mongosh",
|
||||||
"run-example": "npx ts-node src/example.ts"
|
"run-example": "npx ts-node src/example.ts",
|
||||||
|
"deploy:fly": "flyctl deploy --build-secret SENTRY_AUTH_TOKEN=$(dotenv -p SENTRY_AUTH_TOKEN) --depot=false",
|
||||||
|
"deploy:fly:staging": "fly deploy -c fly.staging.toml --depot=false",
|
||||||
|
"sentry:sourcemaps": "sentry-cli sourcemaps inject --org caleb-peffer --project firecrawl-scraper-js ./dist && sentry-cli sourcemaps upload --org caleb-peffer --project firecrawl-scraper-js ./dist"
|
||||||
},
|
},
|
||||||
"author": "",
|
"author": "",
|
||||||
"license": "ISC",
|
"license": "ISC",
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
"@flydotio/dockerfile": "^0.4.10",
|
"@flydotio/dockerfile": "^0.4.10",
|
||||||
|
"@jest/globals": "^29.7.0",
|
||||||
"@tsconfig/recommended": "^1.0.3",
|
"@tsconfig/recommended": "^1.0.3",
|
||||||
"@types/body-parser": "^1.19.2",
|
"@types/body-parser": "^1.19.2",
|
||||||
"@types/bull": "^4.10.0",
|
|
||||||
"@types/cors": "^2.8.13",
|
"@types/cors": "^2.8.13",
|
||||||
"@types/express": "^4.17.17",
|
"@types/express": "^4.17.17",
|
||||||
"@types/jest": "^29.5.12",
|
"@types/jest": "^29.5.12",
|
||||||
|
|
@ -43,66 +48,77 @@
|
||||||
"typescript": "^5.4.2"
|
"typescript": "^5.4.2"
|
||||||
},
|
},
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@anthropic-ai/sdk": "^0.20.5",
|
"@anthropic-ai/sdk": "^0.24.3",
|
||||||
"@brillout/import": "^0.2.2",
|
"@brillout/import": "^0.2.2",
|
||||||
"@bull-board/api": "^5.14.2",
|
"@bull-board/api": "^5.20.5",
|
||||||
"@bull-board/express": "^5.8.0",
|
"@bull-board/express": "^5.20.5",
|
||||||
"@devil7softwares/pos": "^1.0.2",
|
"@devil7softwares/pos": "^1.0.2",
|
||||||
"@dqbd/tiktoken": "^1.0.13",
|
"@dqbd/tiktoken": "^1.0.13",
|
||||||
"@hyperdx/node-opentelemetry": "^0.7.0",
|
"@hyperdx/node-opentelemetry": "^0.8.1",
|
||||||
"@logtail/node": "^0.4.12",
|
"@logtail/node": "^0.4.12",
|
||||||
"@nangohq/node": "^0.36.33",
|
"@nangohq/node": "^0.40.8",
|
||||||
"@sentry/node": "^7.48.0",
|
"@sentry/cli": "^2.33.1",
|
||||||
"@supabase/supabase-js": "^2.7.1",
|
"@sentry/node": "^8.26.0",
|
||||||
"ajv": "^8.12.0",
|
"@sentry/profiling-node": "^8.26.0",
|
||||||
|
"@supabase/supabase-js": "^2.44.2",
|
||||||
|
"@types/express-ws": "^3.0.4",
|
||||||
|
"@types/ws": "^8.5.12",
|
||||||
|
"ajv": "^8.16.0",
|
||||||
"async": "^3.2.5",
|
"async": "^3.2.5",
|
||||||
"async-mutex": "^0.4.0",
|
"async-mutex": "^0.5.0",
|
||||||
"axios": "^1.3.4",
|
"axios": "^1.3.4",
|
||||||
|
"axios-retry": "^4.5.0",
|
||||||
"bottleneck": "^2.19.5",
|
"bottleneck": "^2.19.5",
|
||||||
"bull": "^4.11.4",
|
"bullmq": "^5.11.0",
|
||||||
|
"cacheable-lookup": "^6.1.0",
|
||||||
"cheerio": "^1.0.0-rc.12",
|
"cheerio": "^1.0.0-rc.12",
|
||||||
"cohere": "^1.1.1",
|
"cohere": "^1.1.1",
|
||||||
"cors": "^2.8.5",
|
"cors": "^2.8.5",
|
||||||
"cron-parser": "^4.9.0",
|
"cron-parser": "^4.9.0",
|
||||||
"date-fns": "^2.29.3",
|
"date-fns": "^3.6.0",
|
||||||
"dotenv": "^16.3.1",
|
"dotenv": "^16.3.1",
|
||||||
"express-rate-limit": "^6.7.0",
|
"dotenv-cli": "^7.4.2",
|
||||||
|
"express-rate-limit": "^7.3.1",
|
||||||
|
"express-ws": "^5.0.2",
|
||||||
"form-data": "^4.0.0",
|
"form-data": "^4.0.0",
|
||||||
"glob": "^10.3.12",
|
"glob": "^10.4.2",
|
||||||
"gpt3-tokenizer": "^1.1.5",
|
"gpt3-tokenizer": "^1.1.5",
|
||||||
"ioredis": "^5.3.2",
|
"ioredis": "^5.4.1",
|
||||||
"joplin-turndown-plugin-gfm": "^1.0.12",
|
"joplin-turndown-plugin-gfm": "^1.0.12",
|
||||||
"json-schema-to-zod": "^2.1.0",
|
"json-schema-to-zod": "^2.3.0",
|
||||||
"keyword-extractor": "^0.0.25",
|
"keyword-extractor": "^0.0.28",
|
||||||
"langchain": "^0.1.25",
|
"koffi": "^2.9.0",
|
||||||
|
"langchain": "^0.2.8",
|
||||||
"languagedetect": "^2.0.0",
|
"languagedetect": "^2.0.0",
|
||||||
"logsnag": "^0.1.6",
|
"logsnag": "^1.0.0",
|
||||||
"luxon": "^3.4.3",
|
"luxon": "^3.4.3",
|
||||||
"md5": "^2.3.0",
|
"md5": "^2.3.0",
|
||||||
"moment": "^2.29.4",
|
"moment": "^2.29.4",
|
||||||
"mongoose": "^8.0.3",
|
"mongoose": "^8.4.4",
|
||||||
"natural": "^6.3.0",
|
"natural": "^7.0.7",
|
||||||
"openai": "^4.28.4",
|
"openai": "^4.57.0",
|
||||||
"pdf-parse": "^1.1.1",
|
"pdf-parse": "^1.1.1",
|
||||||
"pos": "^0.4.2",
|
"pos": "^0.4.2",
|
||||||
"posthog-node": "^4.0.1",
|
"posthog-node": "^4.0.1",
|
||||||
"promptable": "^0.0.9",
|
"promptable": "^0.0.10",
|
||||||
"puppeteer": "^22.6.3",
|
"puppeteer": "^22.12.1",
|
||||||
"rate-limiter-flexible": "^2.4.2",
|
"rate-limiter-flexible": "2.4.2",
|
||||||
"redis": "^4.6.7",
|
"redlock": "5.0.0-beta.2",
|
||||||
"resend": "^3.2.0",
|
"resend": "^3.4.0",
|
||||||
"robots-parser": "^3.0.1",
|
"robots-parser": "^3.0.1",
|
||||||
"scrapingbee": "^1.7.4",
|
"scrapingbee": "^1.7.4",
|
||||||
"stripe": "^15.11.0",
|
"stripe": "^16.1.0",
|
||||||
|
"systeminformation": "^5.22.11",
|
||||||
"turndown": "^7.1.3",
|
"turndown": "^7.1.3",
|
||||||
"turndown-plugin-gfm": "^1.0.2",
|
"turndown-plugin-gfm": "^1.0.2",
|
||||||
"typesense": "^1.5.4",
|
"typesense": "^1.5.4",
|
||||||
"unstructured-client": "^0.9.4",
|
"unstructured-client": "^0.11.3",
|
||||||
"uuid": "^9.0.1",
|
"uuid": "^10.0.0",
|
||||||
"wordpos": "^2.1.0",
|
"wordpos": "^2.1.0",
|
||||||
|
"ws": "^8.18.0",
|
||||||
"xml2js": "^0.6.2",
|
"xml2js": "^0.6.2",
|
||||||
"zod": "^3.23.4",
|
"zod": "^3.23.8",
|
||||||
"zod-to-json-schema": "^3.23.0"
|
"zod-to-json-schema": "^3.23.1"
|
||||||
},
|
},
|
||||||
"nodemonConfig": {
|
"nodemonConfig": {
|
||||||
"ignore": [
|
"ignore": [
|
||||||
|
|
|
||||||
12064
apps/api/pnpm-lock.yaml
12064
apps/api/pnpm-lock.yaml
File diff suppressed because it is too large
Load Diff
|
|
@ -1,12 +1,16 @@
|
||||||
### Crawl Website
|
### Crawl Website
|
||||||
POST http://localhost:3002/v0/scrape HTTP/1.1
|
POST http://localhost:3002/v0/scrape HTTP/1.1
|
||||||
Authorization: Bearer
|
Authorization: Bearer fc-
|
||||||
content-type: application/json
|
content-type: application/json
|
||||||
|
|
||||||
{
|
{
|
||||||
"url":"https://docs.mendable.ai"
|
"url":"corterix.com"
|
||||||
}
|
}
|
||||||
|
|
||||||
|
### Check Job Status
|
||||||
|
GET http://localhost:3002/v1/crawl/1dd0f924-a36f-4b96-94ea-32ed954dac67 HTTP/1.1
|
||||||
|
Authorization: Bearer fc-
|
||||||
|
|
||||||
|
|
||||||
### Check Job Status
|
### Check Job Status
|
||||||
GET http://localhost:3002/v0/jobs/active HTTP/1.1
|
GET http://localhost:3002/v0/jobs/active HTTP/1.1
|
||||||
|
|
@ -14,16 +18,24 @@ GET http://localhost:3002/v0/jobs/active HTTP/1.1
|
||||||
|
|
||||||
### Scrape Website
|
### Scrape Website
|
||||||
POST http://localhost:3002/v0/crawl HTTP/1.1
|
POST http://localhost:3002/v0/crawl HTTP/1.1
|
||||||
Authorization: Bearer
|
Authorization: Bearer fc-
|
||||||
content-type: application/json
|
content-type: application/json
|
||||||
|
|
||||||
{
|
{
|
||||||
"url":"https://www.mendable.ai",
|
"url": "firecrawl.dev"
|
||||||
"crawlerOptions": {
|
|
||||||
"returnOnlyUrls": true
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
|
||||||
|
## "reoveTags": [],
|
||||||
|
# "mode": "crawl",
|
||||||
|
# "crawlerOptions": {
|
||||||
|
# "allowBackwardCrawling": false
|
||||||
|
# },
|
||||||
|
# "pageOptions": {
|
||||||
|
# "onlyMainContent": false,
|
||||||
|
# "includeHtml": false,
|
||||||
|
# "parsePDF": true
|
||||||
|
# }
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
|
||||||
7
apps/api/sharedLibs/go-html-to-md/README.md
Normal file
7
apps/api/sharedLibs/go-html-to-md/README.md
Normal file
|
|
@ -0,0 +1,7 @@
|
||||||
|
To build the go-html-to-md library, run the following command:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
cd apps/api/src/lib/go-html-to-md
|
||||||
|
go build -o html-to-markdown.so -buildmode=c-shared html-to-markdown.go
|
||||||
|
chmod +x html-to-markdown.so
|
||||||
|
```
|
||||||
16
apps/api/sharedLibs/go-html-to-md/go.mod
Normal file
16
apps/api/sharedLibs/go-html-to-md/go.mod
Normal file
|
|
@ -0,0 +1,16 @@
|
||||||
|
module html-to-markdown.go
|
||||||
|
|
||||||
|
go 1.19
|
||||||
|
|
||||||
|
require github.com/tomkosm/html-to-markdown v0.0.0-20241031120941-3a729f6b7751
|
||||||
|
|
||||||
|
require (
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2 // indirect
|
||||||
|
github.com/andybalholm/cascadia v1.3.2 // indirect
|
||||||
|
github.com/kr/pretty v0.3.0 // indirect
|
||||||
|
golang.org/x/net v0.25.0 // indirect
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c // indirect
|
||||||
|
gopkg.in/yaml.v2 v2.4.0 // indirect
|
||||||
|
)
|
||||||
|
|
||||||
|
replace github.com/JohannesKaufmann/html-to-markdown => github.com/tomkosm/html-to-markdown v0.0.0-20241031120941-3a729f6b7751
|
||||||
64
apps/api/sharedLibs/go-html-to-md/go.sum
Normal file
64
apps/api/sharedLibs/go-html-to-md/go.sum
Normal file
|
|
@ -0,0 +1,64 @@
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2 h1:4/wZksC3KgkQw7SQgkKotmKljk0M6V8TUvA8Wb4yPeE=
|
||||||
|
github.com/PuerkitoBio/goquery v1.9.2/go.mod h1:GHPCaP0ODyyxqcNoFGYlAprUFH81NuRPd0GX3Zu2Mvk=
|
||||||
|
github.com/andybalholm/cascadia v1.3.2 h1:3Xi6Dw5lHF15JtdcmAHD3i1+T8plmv7BQ/nsViSLyss=
|
||||||
|
github.com/andybalholm/cascadia v1.3.2/go.mod h1:7gtRlve5FxPPgIgX36uWBX58OdBsSS6lUvCFb+h7KvU=
|
||||||
|
github.com/creack/pty v1.1.9/go.mod h1:oKZEueFk5CKHvIhNR5MUki03XCEU+Q6VDXinZuGJ33E=
|
||||||
|
github.com/kr/pretty v0.1.0/go.mod h1:dAy3ld7l9f0ibDNOQOHHMYYIIbhfbHSm3C4ZsoJORNo=
|
||||||
|
github.com/kr/pretty v0.2.1/go.mod h1:ipq/a2n7PKx3OHsz4KJII5eveXtPO4qwEXGdVfWzfnI=
|
||||||
|
github.com/kr/pretty v0.3.0 h1:WgNl7dwNpEZ6jJ9k1snq4pZsg7DOEN8hP9Xw0Tsjwk0=
|
||||||
|
github.com/kr/pretty v0.3.0/go.mod h1:640gp4NfQd8pI5XOwp5fnNeVWj67G7CFk/SaSQn7NBk=
|
||||||
|
github.com/kr/pty v1.1.1/go.mod h1:pFQYn66WHrOpPYNljwOMqo10TkYh1fy3cYio2l3bCsQ=
|
||||||
|
github.com/kr/text v0.1.0/go.mod h1:4Jbv+DJW3UT/LiOwJeYQe1efqtUx/iVham/4vfdArNI=
|
||||||
|
github.com/kr/text v0.2.0 h1:5Nx0Ya0ZqY2ygV366QzturHI13Jq95ApcVaJBhpS+AY=
|
||||||
|
github.com/kr/text v0.2.0/go.mod h1:eLer722TekiGuMkidMxC/pM04lWEeraHUUmBw8l2grE=
|
||||||
|
github.com/pmezard/go-difflib v1.0.0 h1:4DBwDE0NGyQoBHbLQYPwSUPoCMWR5BEzIk/f1lZbAQM=
|
||||||
|
github.com/rogpeppe/go-internal v1.6.1 h1:/FiVV8dS/e+YqF2JvO3yXRFbBLTIuSDkuC7aBOAvL+k=
|
||||||
|
github.com/rogpeppe/go-internal v1.6.1/go.mod h1:xXDCJY+GAPziupqXw64V24skbSoqbTEfhy4qGm1nDQc=
|
||||||
|
github.com/sebdah/goldie/v2 v2.5.3 h1:9ES/mNN+HNUbNWpVAlrzuZ7jE+Nrczbj8uFRjM7624Y=
|
||||||
|
github.com/sergi/go-diff v1.3.1 h1:xkr+Oxo4BOQKmkn/B9eMK0g5Kg/983T9DqqPHwYqD+8=
|
||||||
|
github.com/tomkosm/html-to-markdown v0.0.0-20241031120941-3a729f6b7751 h1:l6JdzR2ry727okVeBxnH8nh3SAd7l/0gJTWbK/3UBRY=
|
||||||
|
github.com/tomkosm/html-to-markdown v0.0.0-20241031120941-3a729f6b7751/go.mod h1:I2mfsDlV0RelCsTjeYh9mdXdwD2M70rA7LT/y2girik=
|
||||||
|
github.com/yuin/goldmark v1.4.13/go.mod h1:6yULJ656Px+3vBD8DxQVa3kxgyrAnzto9xy5taEt/CY=
|
||||||
|
github.com/yuin/goldmark v1.7.1 h1:3bajkSilaCbjdKVsKdZjZCLBNPL9pYzrCakKaf4U49U=
|
||||||
|
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
|
||||||
|
golang.org/x/crypto v0.0.0-20210921155107-089bfa567519/go.mod h1:GvvjBRRGRdwPK5ydBHafDWAxML/pGHZbMvKqRZ5+Abc=
|
||||||
|
golang.org/x/mod v0.6.0-dev.0.20220419223038-86c51ed26bb4/go.mod h1:jJ57K6gSWd91VN4djpZkiMVwK6gcyfeH4XE8wZrZaV4=
|
||||||
|
golang.org/x/mod v0.8.0/go.mod h1:iBbtSCu2XBx23ZKBPSOrRkjjQPZFPuis4dIYUhu/chs=
|
||||||
|
golang.org/x/net v0.0.0-20190620200207-3b0461eec859/go.mod h1:z5CRVTTTmAJ677TzLLGU+0bjPO0LkuOLi4/5GtJWs/s=
|
||||||
|
golang.org/x/net v0.0.0-20210226172049-e18ecbb05110/go.mod h1:m0MpNAwzfU5UDzcl9v0D8zg8gWTRqZa9RBIspLL5mdg=
|
||||||
|
golang.org/x/net v0.0.0-20220722155237-a158d28d115b/go.mod h1:XRhObCWvk6IyKnWLug+ECip1KBveYUHfp+8e9klMJ9c=
|
||||||
|
golang.org/x/net v0.6.0/go.mod h1:2Tu9+aMcznHK/AK1HMvgo6xiTLG5rD5rZLDS+rp2Bjs=
|
||||||
|
golang.org/x/net v0.9.0/go.mod h1:d48xBJpPfHeWQsugry2m+kC02ZBRGRgulfHnEXEuWns=
|
||||||
|
golang.org/x/net v0.25.0 h1:d/OCCoBEUq33pjydKrGQhw7IlUPI2Oylr+8qLx49kac=
|
||||||
|
golang.org/x/net v0.25.0/go.mod h1:JkAGAh7GEvH74S6FOH42FLoXpXbE/aqXSrIQjXgsiwM=
|
||||||
|
golang.org/x/sync v0.0.0-20190423024810-112230192c58/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sync v0.0.0-20220722155255-886fb9371eb4/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sync v0.1.0/go.mod h1:RxMgew5VJxzue5/jJTE5uejpjVlOe/izrB70Jof72aM=
|
||||||
|
golang.org/x/sys v0.0.0-20190215142949-d0b11bdaac8a/go.mod h1:STP8DvDyc/dI5b8T5hshtkjS+E42TnysNCUPdjciGhY=
|
||||||
|
golang.org/x/sys v0.0.0-20201119102817-f84b799fce68/go.mod h1:h1NjWce9XRLGQEsW7wpKNCjG9DtNlClVuFLEZdDNbEs=
|
||||||
|
golang.org/x/sys v0.0.0-20210615035016-665e8c7367d1/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.0.0-20220520151302-bc2c85ada10a/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.0.0-20220722155257-8c9f86f7a55f/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.5.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/sys v0.7.0/go.mod h1:oPkhp1MJrh7nUepCBck5+mAzfO9JrbApNNgaTdGDITg=
|
||||||
|
golang.org/x/term v0.0.0-20201126162022-7de9c90e9dd1/go.mod h1:bj7SfCRtBDWHUb9snDiAeCFNEtKQo2Wmx5Cou7ajbmo=
|
||||||
|
golang.org/x/term v0.0.0-20210927222741-03fcf44c2211/go.mod h1:jbD1KX2456YbFQfuXm/mYQcufACuNUgVhRMnK/tPxf8=
|
||||||
|
golang.org/x/term v0.5.0/go.mod h1:jMB1sMXY+tzblOD4FWmEbocvup2/aLOaQEp7JmGp78k=
|
||||||
|
golang.org/x/term v0.7.0/go.mod h1:P32HKFT3hSsZrRxla30E9HqToFYAQPCMs/zFMBUFqPY=
|
||||||
|
golang.org/x/text v0.3.0/go.mod h1:NqM8EUOU14njkJ3fqMW+pc6Ldnwhi/IjpwHt7yyuwOQ=
|
||||||
|
golang.org/x/text v0.3.3/go.mod h1:5Zoc/QRtKVWzQhOtBMvqHzDpF6irO9z98xDceosuGiQ=
|
||||||
|
golang.org/x/text v0.3.7/go.mod h1:u+2+/6zg+i71rQMx5EYifcz6MCKuco9NR6JIITiCfzQ=
|
||||||
|
golang.org/x/text v0.7.0/go.mod h1:mrYo+phRRbMaCq/xk9113O4dZlRixOauAjOtrjsXDZ8=
|
||||||
|
golang.org/x/text v0.9.0/go.mod h1:e1OnstbJyHTd6l/uOt8jFFHp6TRDWZR/bV3emEE/zU8=
|
||||||
|
golang.org/x/tools v0.0.0-20180917221912-90fa682c2a6e/go.mod h1:n7NCudcB/nEzxVGmLbDWY5pfWTLqBcC2KZ6jyYvM4mQ=
|
||||||
|
golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtnZ6UAqBI28+e2cm9otk0dWdXHAEo=
|
||||||
|
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
|
||||||
|
golang.org/x/tools v0.6.0/go.mod h1:Xwgl3UAJ/d3gWutnCtw505GrjyAbvKui8lOU390QaIU=
|
||||||
|
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
|
||||||
|
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c h1:Hei/4ADfdWqJk1ZMxUNpqntNwaWcugrBjAiHlqqRiVk=
|
||||||
|
gopkg.in/check.v1 v1.0.0-20201130134442-10cb98267c6c/go.mod h1:JHkPIbrfpd72SG/EVd6muEfDQjcINNoR0C8j2r3qZ4Q=
|
||||||
|
gopkg.in/errgo.v2 v2.1.0/go.mod h1:hNsd1EY+bozCKY1Ytp96fpM3vjJbqLJn88ws8XvfDNI=
|
||||||
|
gopkg.in/yaml.v2 v2.4.0 h1:D8xgwECY7CYvx+Y2n4sBz93Jn9JRvxdiyyo8CTfuKaY=
|
||||||
|
gopkg.in/yaml.v2 v2.4.0/go.mod h1:RDklbk79AGWmwhnvt/jBztapEOGDOx6ZbXqjP6csGnQ=
|
||||||
25
apps/api/sharedLibs/go-html-to-md/html-to-markdown.go
Normal file
25
apps/api/sharedLibs/go-html-to-md/html-to-markdown.go
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"C"
|
||||||
|
"log"
|
||||||
|
|
||||||
|
md "github.com/tomkosm/html-to-markdown"
|
||||||
|
"github.com/tomkosm/html-to-markdown/plugin"
|
||||||
|
)
|
||||||
|
|
||||||
|
//export ConvertHTMLToMarkdown
|
||||||
|
func ConvertHTMLToMarkdown(html *C.char) *C.char {
|
||||||
|
converter := md.NewConverter("", true, nil)
|
||||||
|
converter.Use(plugin.GitHubFlavored())
|
||||||
|
|
||||||
|
markdown, err := converter.ConvertString(C.GoString(html))
|
||||||
|
if err != nil {
|
||||||
|
log.Fatal(err)
|
||||||
|
}
|
||||||
|
return C.CString(markdown)
|
||||||
|
}
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
// This function is required for the main package
|
||||||
|
}
|
||||||
1515
apps/api/src/__tests__/e2e_full_withAuth/index.test.ts
Normal file
1515
apps/api/src/__tests__/e2e_full_withAuth/index.test.ts
Normal file
File diff suppressed because it is too large
Load Diff
1005
apps/api/src/__tests__/e2e_v1_withAuth/index.test.ts
Normal file
1005
apps/api/src/__tests__/e2e_v1_withAuth/index.test.ts
Normal file
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
47
apps/api/src/controllers/__tests__/crawl.test.ts
Normal file
47
apps/api/src/controllers/__tests__/crawl.test.ts
Normal file
|
|
@ -0,0 +1,47 @@
|
||||||
|
import { crawlController } from '../v0/crawl'
|
||||||
|
import { Request, Response } from 'express';
|
||||||
|
import { authenticateUser } from '../auth'; // Ensure this import is correct
|
||||||
|
import { createIdempotencyKey } from '../../services/idempotency/create';
|
||||||
|
import { validateIdempotencyKey } from '../../services/idempotency/validate';
|
||||||
|
import { v4 as uuidv4 } from 'uuid';
|
||||||
|
|
||||||
|
jest.mock('../auth', () => ({
|
||||||
|
authenticateUser: jest.fn().mockResolvedValue({
|
||||||
|
success: true,
|
||||||
|
team_id: 'team123',
|
||||||
|
error: null,
|
||||||
|
status: 200
|
||||||
|
}),
|
||||||
|
reduce: jest.fn()
|
||||||
|
}));
|
||||||
|
jest.mock('../../services/idempotency/validate');
|
||||||
|
|
||||||
|
describe('crawlController', () => {
|
||||||
|
it('should prevent duplicate requests using the same idempotency key', async () => {
|
||||||
|
const req = {
|
||||||
|
headers: {
|
||||||
|
'x-idempotency-key': await uuidv4(),
|
||||||
|
'Authorization': `Bearer ${process.env.TEST_API_KEY}`
|
||||||
|
},
|
||||||
|
body: {
|
||||||
|
url: 'https://mendable.ai'
|
||||||
|
}
|
||||||
|
} as unknown as Request;
|
||||||
|
const res = {
|
||||||
|
status: jest.fn().mockReturnThis(),
|
||||||
|
json: jest.fn()
|
||||||
|
} as unknown as Response;
|
||||||
|
|
||||||
|
// Mock the idempotency key validation to return false for the second call
|
||||||
|
(validateIdempotencyKey as jest.Mock).mockResolvedValueOnce(true).mockResolvedValueOnce(false);
|
||||||
|
|
||||||
|
// First request should succeed
|
||||||
|
await crawlController(req, res);
|
||||||
|
expect(res.status).not.toHaveBeenCalledWith(409);
|
||||||
|
|
||||||
|
// Second request with the same key should fail
|
||||||
|
await crawlController(req, res);
|
||||||
|
expect(res.status).toHaveBeenCalledWith(409);
|
||||||
|
expect(res.json).toHaveBeenCalledWith({ error: 'Idempotency key already used' });
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
@ -1,26 +1,166 @@
|
||||||
import { parseApi } from "../../src/lib/parseApi";
|
import { parseApi } from "../lib/parseApi";
|
||||||
import { getRateLimiter, } from "../../src/services/rate-limiter";
|
import { getRateLimiter } from "../services/rate-limiter";
|
||||||
import { AuthResponse, NotificationType, RateLimiterMode } from "../../src/types";
|
import {
|
||||||
import { supabase_service } from "../../src/services/supabase";
|
AuthResponse,
|
||||||
import { withAuth } from "../../src/lib/withAuth";
|
NotificationType,
|
||||||
|
PlanType,
|
||||||
|
RateLimiterMode,
|
||||||
|
} from "../types";
|
||||||
|
import { supabase_service } from "../services/supabase";
|
||||||
|
import { withAuth } from "../lib/withAuth";
|
||||||
import { RateLimiterRedis } from "rate-limiter-flexible";
|
import { RateLimiterRedis } from "rate-limiter-flexible";
|
||||||
import { setTraceAttributes } from '@hyperdx/node-opentelemetry';
|
import { setTraceAttributes } from "@hyperdx/node-opentelemetry";
|
||||||
import { sendNotification } from "../services/notification/email_notification";
|
import { sendNotification } from "../services/notification/email_notification";
|
||||||
|
import { Logger } from "../lib/logger";
|
||||||
|
import { redlock } from "../services/redlock";
|
||||||
|
import { deleteKey, getValue } from "../services/redis";
|
||||||
|
import { setValue } from "../services/redis";
|
||||||
|
import { validate } from "uuid";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { AuthCreditUsageChunk } from "./v1/types";
|
||||||
|
// const { data, error } = await supabase_service
|
||||||
|
// .from('api_keys')
|
||||||
|
// .select(`
|
||||||
|
// key,
|
||||||
|
// team_id,
|
||||||
|
// teams (
|
||||||
|
// subscriptions (
|
||||||
|
// price_id
|
||||||
|
// )
|
||||||
|
// )
|
||||||
|
// `)
|
||||||
|
// .eq('key', normalizedApi)
|
||||||
|
// .limit(1)
|
||||||
|
// .single();
|
||||||
|
function normalizedApiIsUuid(potentialUuid: string): boolean {
|
||||||
|
// Check if the string is a valid UUID
|
||||||
|
return validate(potentialUuid);
|
||||||
|
}
|
||||||
|
|
||||||
export async function authenticateUser(req, res, mode?: RateLimiterMode): Promise<AuthResponse> {
|
export async function setCachedACUC(
|
||||||
|
api_key: string,
|
||||||
|
acuc:
|
||||||
|
| AuthCreditUsageChunk
|
||||||
|
| ((acuc: AuthCreditUsageChunk) => AuthCreditUsageChunk)
|
||||||
|
) {
|
||||||
|
const cacheKeyACUC = `acuc_${api_key}`;
|
||||||
|
const redLockKey = `lock_${cacheKeyACUC}`;
|
||||||
|
|
||||||
|
try {
|
||||||
|
await redlock.using([redLockKey], 10000, {}, async (signal) => {
|
||||||
|
if (typeof acuc === "function") {
|
||||||
|
acuc = acuc(JSON.parse(await getValue(cacheKeyACUC)));
|
||||||
|
|
||||||
|
if (acuc === null) {
|
||||||
|
if (signal.aborted) {
|
||||||
|
throw signal.error;
|
||||||
|
}
|
||||||
|
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (signal.aborted) {
|
||||||
|
throw signal.error;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Cache for 10 minutes. This means that changing subscription tier could have
|
||||||
|
// a maximum of 10 minutes of a delay. - mogery
|
||||||
|
await setValue(cacheKeyACUC, JSON.stringify(acuc), 600, true);
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error updating cached ACUC ${cacheKeyACUC}: ${error}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getACUC(
|
||||||
|
api_key: string,
|
||||||
|
cacheOnly = false,
|
||||||
|
useCache = true
|
||||||
|
): Promise<AuthCreditUsageChunk | null> {
|
||||||
|
const cacheKeyACUC = `acuc_${api_key}`;
|
||||||
|
|
||||||
|
if (useCache) {
|
||||||
|
const cachedACUC = await getValue(cacheKeyACUC);
|
||||||
|
if (cachedACUC !== null) {
|
||||||
|
return JSON.parse(cachedACUC);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!cacheOnly) {
|
||||||
|
let data;
|
||||||
|
let error;
|
||||||
|
let retries = 0;
|
||||||
|
const maxRetries = 5;
|
||||||
|
|
||||||
|
while (retries < maxRetries) {
|
||||||
|
({ data, error } = await supabase_service.rpc(
|
||||||
|
"auth_credit_usage_chunk_test_21_credit_pack",
|
||||||
|
{ input_key: api_key }
|
||||||
|
));
|
||||||
|
|
||||||
|
if (!error) {
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
|
||||||
|
Logger.warn(
|
||||||
|
`Failed to retrieve authentication and credit usage data after ${retries}, trying again...`
|
||||||
|
);
|
||||||
|
retries++;
|
||||||
|
if (retries === maxRetries) {
|
||||||
|
throw new Error(
|
||||||
|
"Failed to retrieve authentication and credit usage data after 3 attempts: " +
|
||||||
|
JSON.stringify(error)
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Wait for a short time before retrying
|
||||||
|
await new Promise((resolve) => setTimeout(resolve, 200));
|
||||||
|
}
|
||||||
|
|
||||||
|
const chunk: AuthCreditUsageChunk | null =
|
||||||
|
data.length === 0 ? null : data[0].team_id === null ? null : data[0];
|
||||||
|
|
||||||
|
// NOTE: Should we cache null chunks? - mogery
|
||||||
|
if (chunk !== null && useCache) {
|
||||||
|
setCachedACUC(api_key, chunk);
|
||||||
|
}
|
||||||
|
|
||||||
|
// console.log(chunk);
|
||||||
|
|
||||||
|
return chunk;
|
||||||
|
} else {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function clearACUC(
|
||||||
|
api_key: string,
|
||||||
|
): Promise<void> {
|
||||||
|
const cacheKeyACUC = `acuc_${api_key}`;
|
||||||
|
await deleteKey(cacheKeyACUC);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
mode?: RateLimiterMode
|
||||||
|
): Promise<AuthResponse> {
|
||||||
return withAuth(supaAuthenticateUser)(req, res, mode);
|
return withAuth(supaAuthenticateUser)(req, res, mode);
|
||||||
}
|
}
|
||||||
|
|
||||||
function setTrace(team_id: string, api_key: string) {
|
function setTrace(team_id: string, api_key: string) {
|
||||||
try {
|
try {
|
||||||
setTraceAttributes({
|
setTraceAttributes({
|
||||||
team_id,
|
team_id,
|
||||||
api_key
|
api_key,
|
||||||
});
|
});
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error('Error setting trace attributes:', error);
|
Sentry.captureException(error);
|
||||||
|
Logger.error(`Error setting trace attributes: ${error.message}`);
|
||||||
}
|
}
|
||||||
|
|
||||||
}
|
}
|
||||||
|
|
||||||
export async function supaAuthenticateUser(
|
export async function supaAuthenticateUser(
|
||||||
req,
|
req,
|
||||||
res,
|
res,
|
||||||
|
|
@ -30,9 +170,14 @@ export async function supaAuthenticateUser(
|
||||||
team_id?: string;
|
team_id?: string;
|
||||||
error?: string;
|
error?: string;
|
||||||
status?: number;
|
status?: number;
|
||||||
plan?: string;
|
plan?: PlanType;
|
||||||
|
chunk?: AuthCreditUsageChunk;
|
||||||
}> {
|
}> {
|
||||||
const authHeader = req.headers.authorization;
|
const authHeader =
|
||||||
|
req.headers.authorization ??
|
||||||
|
(req.headers["sec-websocket-protocol"]
|
||||||
|
? `Bearer ${req.headers["sec-websocket-protocol"]}`
|
||||||
|
: null);
|
||||||
if (!authHeader) {
|
if (!authHeader) {
|
||||||
return { success: false, error: "Unauthorized", status: 401 };
|
return { success: false, error: "Unauthorized", status: 401 };
|
||||||
}
|
}
|
||||||
|
|
@ -50,69 +195,79 @@ export async function supaAuthenticateUser(
|
||||||
const iptoken = incomingIP + token;
|
const iptoken = incomingIP + token;
|
||||||
|
|
||||||
let rateLimiter: RateLimiterRedis;
|
let rateLimiter: RateLimiterRedis;
|
||||||
let subscriptionData: { team_id: string, plan: string } | null = null;
|
let subscriptionData: { team_id: string; plan: string } | null = null;
|
||||||
let normalizedApi: string;
|
let normalizedApi: string;
|
||||||
|
|
||||||
let team_id: string;
|
let teamId: string | null = null;
|
||||||
|
let priceId: string | null = null;
|
||||||
|
let chunk: AuthCreditUsageChunk;
|
||||||
|
|
||||||
if (token == "this_is_just_a_preview_token") {
|
if (token == "this_is_just_a_preview_token") {
|
||||||
|
if (mode == RateLimiterMode.CrawlStatus) {
|
||||||
|
rateLimiter = getRateLimiter(RateLimiterMode.CrawlStatus, token);
|
||||||
|
} else {
|
||||||
rateLimiter = getRateLimiter(RateLimiterMode.Preview, token);
|
rateLimiter = getRateLimiter(RateLimiterMode.Preview, token);
|
||||||
team_id = "preview";
|
}
|
||||||
|
teamId = "preview";
|
||||||
} else {
|
} else {
|
||||||
normalizedApi = parseApi(token);
|
normalizedApi = parseApi(token);
|
||||||
|
if (!normalizedApiIsUuid(normalizedApi)) {
|
||||||
const { data, error } = await supabase_service.rpc(
|
|
||||||
'get_key_and_price_id_2', { api_key: normalizedApi }
|
|
||||||
);
|
|
||||||
// get_key_and_price_id_2 rpc definition:
|
|
||||||
// create or replace function get_key_and_price_id_2(api_key uuid)
|
|
||||||
// returns table(key uuid, team_id uuid, price_id text) as $$
|
|
||||||
// begin
|
|
||||||
// if api_key is null then
|
|
||||||
// return query
|
|
||||||
// select null::uuid as key, null::uuid as team_id, null::text as price_id;
|
|
||||||
// end if;
|
|
||||||
|
|
||||||
// return query
|
|
||||||
// select ak.key, ak.team_id, s.price_id
|
|
||||||
// from api_keys ak
|
|
||||||
// left join subscriptions s on ak.team_id = s.team_id
|
|
||||||
// where ak.key = api_key;
|
|
||||||
// end;
|
|
||||||
// $$ language plpgsql;
|
|
||||||
|
|
||||||
if (error) {
|
|
||||||
console.error('Error fetching key and price_id:', error);
|
|
||||||
} else {
|
|
||||||
// console.log('Key and Price ID:', data);
|
|
||||||
}
|
|
||||||
|
|
||||||
if (error || !data || data.length === 0) {
|
|
||||||
return {
|
return {
|
||||||
success: false,
|
success: false,
|
||||||
error: "Unauthorized: Invalid token",
|
error: "Unauthorized: Invalid token",
|
||||||
status: 401,
|
status: 401,
|
||||||
};
|
};
|
||||||
}
|
}
|
||||||
const internal_team_id = data[0].team_id;
|
|
||||||
team_id = internal_team_id;
|
|
||||||
|
|
||||||
const plan = getPlanByPriceId(data[0].price_id);
|
chunk = await getACUC(normalizedApi);
|
||||||
// HyperDX Logging
|
|
||||||
setTrace(team_id, normalizedApi);
|
if (chunk === null) {
|
||||||
subscriptionData = {
|
return {
|
||||||
team_id: team_id,
|
success: false,
|
||||||
plan: plan
|
error: "Unauthorized: Invalid token",
|
||||||
|
status: 401,
|
||||||
|
};
|
||||||
}
|
}
|
||||||
|
|
||||||
|
teamId = chunk.team_id;
|
||||||
|
priceId = chunk.price_id;
|
||||||
|
|
||||||
|
const plan = getPlanByPriceId(priceId);
|
||||||
|
// HyperDX Logging
|
||||||
|
setTrace(teamId, normalizedApi);
|
||||||
|
subscriptionData = {
|
||||||
|
team_id: teamId,
|
||||||
|
plan,
|
||||||
|
};
|
||||||
switch (mode) {
|
switch (mode) {
|
||||||
case RateLimiterMode.Crawl:
|
case RateLimiterMode.Crawl:
|
||||||
rateLimiter = getRateLimiter(RateLimiterMode.Crawl, token, subscriptionData.plan);
|
rateLimiter = getRateLimiter(
|
||||||
|
RateLimiterMode.Crawl,
|
||||||
|
token,
|
||||||
|
subscriptionData.plan
|
||||||
|
);
|
||||||
break;
|
break;
|
||||||
case RateLimiterMode.Scrape:
|
case RateLimiterMode.Scrape:
|
||||||
rateLimiter = getRateLimiter(RateLimiterMode.Scrape, token, subscriptionData.plan);
|
rateLimiter = getRateLimiter(
|
||||||
|
RateLimiterMode.Scrape,
|
||||||
|
token,
|
||||||
|
subscriptionData.plan,
|
||||||
|
teamId
|
||||||
|
);
|
||||||
break;
|
break;
|
||||||
case RateLimiterMode.Search:
|
case RateLimiterMode.Search:
|
||||||
rateLimiter = getRateLimiter(RateLimiterMode.Search, token, subscriptionData.plan);
|
rateLimiter = getRateLimiter(
|
||||||
|
RateLimiterMode.Search,
|
||||||
|
token,
|
||||||
|
subscriptionData.plan
|
||||||
|
);
|
||||||
|
break;
|
||||||
|
case RateLimiterMode.Map:
|
||||||
|
rateLimiter = getRateLimiter(
|
||||||
|
RateLimiterMode.Map,
|
||||||
|
token,
|
||||||
|
subscriptionData.plan
|
||||||
|
);
|
||||||
break;
|
break;
|
||||||
case RateLimiterMode.CrawlStatus:
|
case RateLimiterMode.CrawlStatus:
|
||||||
rateLimiter = getRateLimiter(RateLimiterMode.CrawlStatus, token);
|
rateLimiter = getRateLimiter(RateLimiterMode.CrawlStatus, token);
|
||||||
|
|
@ -130,12 +285,13 @@ export async function supaAuthenticateUser(
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
const team_endpoint_token = token === "this_is_just_a_preview_token" ? iptoken : team_id;
|
const team_endpoint_token =
|
||||||
|
token === "this_is_just_a_preview_token" ? iptoken : teamId;
|
||||||
|
|
||||||
try {
|
try {
|
||||||
await rateLimiter.consume(team_endpoint_token);
|
await rateLimiter.consume(team_endpoint_token);
|
||||||
} catch (rateLimiterRes) {
|
} catch (rateLimiterRes) {
|
||||||
console.error(rateLimiterRes);
|
Logger.error(`Rate limit exceeded: ${rateLimiterRes}`);
|
||||||
const secs = Math.round(rateLimiterRes.msBeforeNext / 1000) || 1;
|
const secs = Math.round(rateLimiterRes.msBeforeNext / 1000) || 1;
|
||||||
const retryDate = new Date(Date.now() + rateLimiterRes.msBeforeNext);
|
const retryDate = new Date(Date.now() + rateLimiterRes.msBeforeNext);
|
||||||
|
|
||||||
|
|
@ -143,17 +299,24 @@ export async function supaAuthenticateUser(
|
||||||
const startDate = new Date();
|
const startDate = new Date();
|
||||||
const endDate = new Date();
|
const endDate = new Date();
|
||||||
endDate.setDate(endDate.getDate() + 7);
|
endDate.setDate(endDate.getDate() + 7);
|
||||||
|
|
||||||
// await sendNotification(team_id, NotificationType.RATE_LIMIT_REACHED, startDate.toISOString(), endDate.toISOString());
|
// await sendNotification(team_id, NotificationType.RATE_LIMIT_REACHED, startDate.toISOString(), endDate.toISOString());
|
||||||
|
|
||||||
return {
|
return {
|
||||||
success: false,
|
success: false,
|
||||||
error: `Rate limit exceeded. Consumed points: ${rateLimiterRes.consumedPoints}, Remaining points: ${rateLimiterRes.remainingPoints}. Upgrade your plan at https://firecrawl.dev/pricing for increased rate limits or please retry after ${secs}s, resets at ${retryDate}`,
|
error: `Rate limit exceeded. Consumed (req/min): ${rateLimiterRes.consumedPoints}, Remaining (req/min): ${rateLimiterRes.remainingPoints}. Upgrade your plan at https://firecrawl.dev/pricing for increased rate limits or please retry after ${secs}s, resets at ${retryDate}`,
|
||||||
status: 429,
|
status: 429,
|
||||||
};
|
};
|
||||||
}
|
}
|
||||||
|
|
||||||
if (
|
if (
|
||||||
token === "this_is_just_a_preview_token" &&
|
token === "this_is_just_a_preview_token" &&
|
||||||
(mode === RateLimiterMode.Scrape || mode === RateLimiterMode.Preview || mode === RateLimiterMode.Search)
|
(mode === RateLimiterMode.Scrape ||
|
||||||
|
mode === RateLimiterMode.Preview ||
|
||||||
|
mode === RateLimiterMode.Map ||
|
||||||
|
mode === RateLimiterMode.Crawl ||
|
||||||
|
mode === RateLimiterMode.CrawlStatus ||
|
||||||
|
mode === RateLimiterMode.Search)
|
||||||
) {
|
) {
|
||||||
return { success: true, team_id: "preview" };
|
return { success: true, team_id: "preview" };
|
||||||
// check the origin of the request and make sure its from firecrawl.dev
|
// check the origin of the request and make sure its from firecrawl.dev
|
||||||
|
|
@ -168,44 +331,36 @@ export async function supaAuthenticateUser(
|
||||||
// return { success: false, error: "Unauthorized: Invalid token", status: 401 };
|
// return { success: false, error: "Unauthorized: Invalid token", status: 401 };
|
||||||
}
|
}
|
||||||
|
|
||||||
// make sure api key is valid, based on the api_keys table in supabase
|
|
||||||
if (!subscriptionData) {
|
|
||||||
normalizedApi = parseApi(token);
|
|
||||||
|
|
||||||
const { data, error } = await supabase_service
|
|
||||||
.from("api_keys")
|
|
||||||
.select("*")
|
|
||||||
.eq("key", normalizedApi);
|
|
||||||
|
|
||||||
if (error || !data || data.length === 0) {
|
|
||||||
return {
|
return {
|
||||||
success: false,
|
success: true,
|
||||||
error: "Unauthorized: Invalid token",
|
team_id: subscriptionData.team_id,
|
||||||
status: 401,
|
plan: (subscriptionData.plan ?? "") as PlanType,
|
||||||
|
chunk,
|
||||||
};
|
};
|
||||||
}
|
|
||||||
|
|
||||||
subscriptionData = data[0];
|
|
||||||
}
|
|
||||||
|
|
||||||
return { success: true, team_id: subscriptionData.team_id, plan: subscriptionData.plan ?? ""};
|
|
||||||
}
|
}
|
||||||
|
function getPlanByPriceId(price_id: string): PlanType {
|
||||||
function getPlanByPriceId(price_id: string) {
|
|
||||||
switch (price_id) {
|
switch (price_id) {
|
||||||
case process.env.STRIPE_PRICE_ID_STARTER:
|
case process.env.STRIPE_PRICE_ID_STARTER:
|
||||||
return 'starter';
|
return "starter";
|
||||||
case process.env.STRIPE_PRICE_ID_STANDARD:
|
case process.env.STRIPE_PRICE_ID_STANDARD:
|
||||||
return 'standard';
|
return "standard";
|
||||||
case process.env.STRIPE_PRICE_ID_SCALE:
|
case process.env.STRIPE_PRICE_ID_SCALE:
|
||||||
return 'scale';
|
return "scale";
|
||||||
case process.env.STRIPE_PRICE_ID_HOBBY || process.env.STRIPE_PRICE_ID_HOBBY_YEARLY:
|
case process.env.STRIPE_PRICE_ID_HOBBY:
|
||||||
return 'hobby';
|
case process.env.STRIPE_PRICE_ID_HOBBY_YEARLY:
|
||||||
case process.env.STRIPE_PRICE_ID_STANDARD_NEW || process.env.STRIPE_PRICE_ID_STANDARD_NEW_YEARLY:
|
return "hobby";
|
||||||
return 'standard-new';
|
case process.env.STRIPE_PRICE_ID_STANDARD_NEW:
|
||||||
case process.env.STRIPE_PRICE_ID_GROWTH || process.env.STRIPE_PRICE_ID_GROWTH_YEARLY:
|
case process.env.STRIPE_PRICE_ID_STANDARD_NEW_YEARLY:
|
||||||
return 'growth';
|
return "standardnew";
|
||||||
|
case process.env.STRIPE_PRICE_ID_GROWTH:
|
||||||
|
case process.env.STRIPE_PRICE_ID_GROWTH_YEARLY:
|
||||||
|
case process.env.STRIPE_PRICE_ID_SCALE_2M:
|
||||||
|
return "growth";
|
||||||
|
case process.env.STRIPE_PRICE_ID_GROWTH_DOUBLE_MONTHLY:
|
||||||
|
return "growthdouble";
|
||||||
|
case process.env.STRIPE_PRICE_ID_ETIER2C:
|
||||||
|
return "etier2c";
|
||||||
default:
|
default:
|
||||||
return 'free';
|
return "free";
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
@ -1,62 +0,0 @@
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { authenticateUser } from "./auth";
|
|
||||||
import { RateLimiterMode } from "../../src/types";
|
|
||||||
import { addWebScraperJob } from "../../src/services/queue-jobs";
|
|
||||||
import { getWebScraperQueue } from "../../src/services/queue-service";
|
|
||||||
import { supabase_service } from "../../src/services/supabase";
|
|
||||||
import { billTeam } from "../../src/services/billing/credit_billing";
|
|
||||||
|
|
||||||
export async function crawlCancelController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
const { success, team_id, error, status } = await authenticateUser(
|
|
||||||
req,
|
|
||||||
res,
|
|
||||||
RateLimiterMode.CrawlStatus
|
|
||||||
);
|
|
||||||
if (!success) {
|
|
||||||
return res.status(status).json({ error });
|
|
||||||
}
|
|
||||||
const job = await getWebScraperQueue().getJob(req.params.jobId);
|
|
||||||
if (!job) {
|
|
||||||
return res.status(404).json({ error: "Job not found" });
|
|
||||||
}
|
|
||||||
|
|
||||||
// check if the job belongs to the team
|
|
||||||
const { data, error: supaError } = await supabase_service
|
|
||||||
.from("bulljobs_teams")
|
|
||||||
.select("*")
|
|
||||||
.eq("job_id", req.params.jobId)
|
|
||||||
.eq("team_id", team_id);
|
|
||||||
if (supaError) {
|
|
||||||
return res.status(500).json({ error: supaError.message });
|
|
||||||
}
|
|
||||||
|
|
||||||
if (data.length === 0) {
|
|
||||||
return res.status(403).json({ error: "Unauthorized" });
|
|
||||||
}
|
|
||||||
const jobState = await job.getState();
|
|
||||||
const { partialDocs } = await job.progress();
|
|
||||||
|
|
||||||
if (partialDocs && partialDocs.length > 0 && jobState === "active") {
|
|
||||||
console.log("Billing team for partial docs...");
|
|
||||||
// Note: the credits that we will bill them here might be lower than the actual
|
|
||||||
// due to promises that are not yet resolved
|
|
||||||
await billTeam(team_id, partialDocs.length);
|
|
||||||
}
|
|
||||||
|
|
||||||
try {
|
|
||||||
await job.moveToFailed(Error("Job cancelled by user"), true);
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
}
|
|
||||||
|
|
||||||
const newJobState = await job.getState();
|
|
||||||
|
|
||||||
res.json({
|
|
||||||
status: newJobState === "failed" ? "cancelled" : "Cancelling...",
|
|
||||||
});
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1,37 +0,0 @@
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { authenticateUser } from "./auth";
|
|
||||||
import { RateLimiterMode } from "../../src/types";
|
|
||||||
import { addWebScraperJob } from "../../src/services/queue-jobs";
|
|
||||||
import { getWebScraperQueue } from "../../src/services/queue-service";
|
|
||||||
|
|
||||||
export async function crawlStatusController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
const { success, team_id, error, status } = await authenticateUser(
|
|
||||||
req,
|
|
||||||
res,
|
|
||||||
RateLimiterMode.CrawlStatus
|
|
||||||
);
|
|
||||||
if (!success) {
|
|
||||||
return res.status(status).json({ error });
|
|
||||||
}
|
|
||||||
const job = await getWebScraperQueue().getJob(req.params.jobId);
|
|
||||||
if (!job) {
|
|
||||||
return res.status(404).json({ error: "Job not found" });
|
|
||||||
}
|
|
||||||
|
|
||||||
const { current, current_url, total, current_step, partialDocs } = await job.progress();
|
|
||||||
res.json({
|
|
||||||
status: await job.getState(),
|
|
||||||
// progress: job.progress(),
|
|
||||||
current: current,
|
|
||||||
current_url: current_url,
|
|
||||||
current_step: current_step,
|
|
||||||
total: total,
|
|
||||||
data: job.returnvalue,
|
|
||||||
partial_data: partialDocs ?? [],
|
|
||||||
});
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1,111 +0,0 @@
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { WebScraperDataProvider } from "../../src/scraper/WebScraper";
|
|
||||||
import { billTeam } from "../../src/services/billing/credit_billing";
|
|
||||||
import { checkTeamCredits } from "../../src/services/billing/credit_billing";
|
|
||||||
import { authenticateUser } from "./auth";
|
|
||||||
import { RateLimiterMode } from "../../src/types";
|
|
||||||
import { addWebScraperJob } from "../../src/services/queue-jobs";
|
|
||||||
import { isUrlBlocked } from "../../src/scraper/WebScraper/utils/blocklist";
|
|
||||||
import { logCrawl } from "../../src/services/logging/crawl_log";
|
|
||||||
import { validateIdempotencyKey } from "../../src/services/idempotency/validate";
|
|
||||||
import { createIdempotencyKey } from "../../src/services/idempotency/create";
|
|
||||||
|
|
||||||
export async function crawlController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
const { success, team_id, error, status } = await authenticateUser(
|
|
||||||
req,
|
|
||||||
res,
|
|
||||||
RateLimiterMode.Crawl
|
|
||||||
);
|
|
||||||
if (!success) {
|
|
||||||
return res.status(status).json({ error });
|
|
||||||
}
|
|
||||||
|
|
||||||
if (req.headers["x-idempotency-key"]) {
|
|
||||||
const isIdempotencyValid = await validateIdempotencyKey(req);
|
|
||||||
if (!isIdempotencyValid) {
|
|
||||||
return res.status(409).json({ error: "Idempotency key already used" });
|
|
||||||
}
|
|
||||||
try {
|
|
||||||
createIdempotencyKey(req);
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
const { success: creditsCheckSuccess, message: creditsCheckMessage } =
|
|
||||||
await checkTeamCredits(team_id, 1);
|
|
||||||
if (!creditsCheckSuccess) {
|
|
||||||
return res.status(402).json({ error: "Insufficient credits" });
|
|
||||||
}
|
|
||||||
|
|
||||||
const url = req.body.url;
|
|
||||||
if (!url) {
|
|
||||||
return res.status(400).json({ error: "Url is required" });
|
|
||||||
}
|
|
||||||
|
|
||||||
if (isUrlBlocked(url)) {
|
|
||||||
return res
|
|
||||||
.status(403)
|
|
||||||
.json({
|
|
||||||
error:
|
|
||||||
"Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.",
|
|
||||||
});
|
|
||||||
}
|
|
||||||
|
|
||||||
const mode = req.body.mode ?? "crawl";
|
|
||||||
const crawlerOptions = req.body.crawlerOptions ?? {
|
|
||||||
allowBackwardCrawling: false
|
|
||||||
};
|
|
||||||
const pageOptions = req.body.pageOptions ?? {
|
|
||||||
onlyMainContent: false,
|
|
||||||
includeHtml: false,
|
|
||||||
removeTags: []
|
|
||||||
};
|
|
||||||
|
|
||||||
if (mode === "single_urls" && !url.includes(",")) {
|
|
||||||
try {
|
|
||||||
const a = new WebScraperDataProvider();
|
|
||||||
await a.setOptions({
|
|
||||||
mode: "single_urls",
|
|
||||||
urls: [url],
|
|
||||||
crawlerOptions: { ...crawlerOptions, returnOnlyUrls: true },
|
|
||||||
pageOptions: pageOptions,
|
|
||||||
});
|
|
||||||
|
|
||||||
const docs = await a.getDocuments(false, (progress) => {
|
|
||||||
job.progress({
|
|
||||||
current: progress.current,
|
|
||||||
total: progress.total,
|
|
||||||
current_step: "SCRAPING",
|
|
||||||
current_url: progress.currentDocumentUrl,
|
|
||||||
});
|
|
||||||
});
|
|
||||||
return res.json({
|
|
||||||
success: true,
|
|
||||||
documents: docs,
|
|
||||||
});
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
const job = await addWebScraperJob({
|
|
||||||
url: url,
|
|
||||||
mode: mode ?? "crawl", // fix for single urls not working
|
|
||||||
crawlerOptions: crawlerOptions,
|
|
||||||
team_id: team_id,
|
|
||||||
pageOptions: pageOptions,
|
|
||||||
origin: req.body.origin ?? "api",
|
|
||||||
});
|
|
||||||
|
|
||||||
await logCrawl(job.id.toString(), team_id);
|
|
||||||
|
|
||||||
res.json({ jobId: job.id });
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1,45 +0,0 @@
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { authenticateUser } from "./auth";
|
|
||||||
import { RateLimiterMode } from "../../src/types";
|
|
||||||
import { addWebScraperJob } from "../../src/services/queue-jobs";
|
|
||||||
import { isUrlBlocked } from "../../src/scraper/WebScraper/utils/blocklist";
|
|
||||||
|
|
||||||
export async function crawlPreviewController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
const { success, team_id, error, status } = await authenticateUser(
|
|
||||||
req,
|
|
||||||
res,
|
|
||||||
RateLimiterMode.Preview
|
|
||||||
);
|
|
||||||
if (!success) {
|
|
||||||
return res.status(status).json({ error });
|
|
||||||
}
|
|
||||||
// authenticate on supabase
|
|
||||||
const url = req.body.url;
|
|
||||||
if (!url) {
|
|
||||||
return res.status(400).json({ error: "Url is required" });
|
|
||||||
}
|
|
||||||
|
|
||||||
if (isUrlBlocked(url)) {
|
|
||||||
return res.status(403).json({ error: "Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it." });
|
|
||||||
}
|
|
||||||
|
|
||||||
const mode = req.body.mode ?? "crawl";
|
|
||||||
const crawlerOptions = req.body.crawlerOptions ?? {};
|
|
||||||
const pageOptions = req.body.pageOptions ?? { onlyMainContent: false, includeHtml: false, removeTags: [] };
|
|
||||||
|
|
||||||
const job = await addWebScraperJob({
|
|
||||||
url: url,
|
|
||||||
mode: mode ?? "crawl", // fix for single urls not working
|
|
||||||
crawlerOptions: { ...crawlerOptions, limit: 5, maxCrawledLinks: 5 },
|
|
||||||
team_id: "preview",
|
|
||||||
pageOptions: pageOptions,
|
|
||||||
origin: "website-preview",
|
|
||||||
});
|
|
||||||
|
|
||||||
res.json({ jobId: job.id });
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1,162 +0,0 @@
|
||||||
import { ExtractorOptions, PageOptions } from './../lib/entities';
|
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { WebScraperDataProvider } from "../scraper/WebScraper";
|
|
||||||
import { billTeam, checkTeamCredits } from "../services/billing/credit_billing";
|
|
||||||
import { authenticateUser } from "./auth";
|
|
||||||
import { RateLimiterMode } from "../types";
|
|
||||||
import { logJob } from "../services/logging/log_job";
|
|
||||||
import { Document } from "../lib/entities";
|
|
||||||
import { isUrlBlocked } from "../scraper/WebScraper/utils/blocklist"; // Import the isUrlBlocked function
|
|
||||||
import { numTokensFromString } from '../lib/LLM-extraction/helpers';
|
|
||||||
|
|
||||||
export async function scrapeHelper(
|
|
||||||
req: Request,
|
|
||||||
team_id: string,
|
|
||||||
crawlerOptions: any,
|
|
||||||
pageOptions: PageOptions,
|
|
||||||
extractorOptions: ExtractorOptions,
|
|
||||||
timeout: number,
|
|
||||||
plan?: string
|
|
||||||
): Promise<{
|
|
||||||
success: boolean;
|
|
||||||
error?: string;
|
|
||||||
data?: Document;
|
|
||||||
returnCode: number;
|
|
||||||
}> {
|
|
||||||
const url = req.body.url;
|
|
||||||
if (!url) {
|
|
||||||
return { success: false, error: "Url is required", returnCode: 400 };
|
|
||||||
}
|
|
||||||
|
|
||||||
if (isUrlBlocked(url)) {
|
|
||||||
return { success: false, error: "Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.", returnCode: 403 };
|
|
||||||
}
|
|
||||||
|
|
||||||
const a = new WebScraperDataProvider();
|
|
||||||
await a.setOptions({
|
|
||||||
mode: "single_urls",
|
|
||||||
urls: [url],
|
|
||||||
crawlerOptions: {
|
|
||||||
...crawlerOptions,
|
|
||||||
},
|
|
||||||
pageOptions: pageOptions,
|
|
||||||
extractorOptions: extractorOptions,
|
|
||||||
});
|
|
||||||
|
|
||||||
const timeoutPromise = new Promise<{ success: boolean; error?: string; returnCode: number }>((_, reject) =>
|
|
||||||
setTimeout(() => reject({ success: false, error: "Request timed out. Increase the timeout by passing `timeout` param to the request.", returnCode: 408 }), timeout)
|
|
||||||
);
|
|
||||||
|
|
||||||
const docsPromise = a.getDocuments(false);
|
|
||||||
|
|
||||||
let docs;
|
|
||||||
try {
|
|
||||||
docs = await Promise.race([docsPromise, timeoutPromise]);
|
|
||||||
} catch (error) {
|
|
||||||
return error;
|
|
||||||
}
|
|
||||||
|
|
||||||
// make sure doc.content is not empty
|
|
||||||
const filteredDocs = docs.filter(
|
|
||||||
(doc: { content?: string }) => doc.content && doc.content.trim().length > 0
|
|
||||||
);
|
|
||||||
if (filteredDocs.length === 0) {
|
|
||||||
return { success: true, error: "No page found", returnCode: 200 };
|
|
||||||
}
|
|
||||||
|
|
||||||
let creditsToBeBilled = filteredDocs.length;
|
|
||||||
const creditsPerLLMExtract = 50;
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
if (extractorOptions.mode === "llm-extraction") {
|
|
||||||
creditsToBeBilled = creditsToBeBilled + (creditsPerLLMExtract * filteredDocs.length);
|
|
||||||
}
|
|
||||||
|
|
||||||
const billingResult = await billTeam(
|
|
||||||
team_id,
|
|
||||||
creditsToBeBilled
|
|
||||||
);
|
|
||||||
if (!billingResult.success) {
|
|
||||||
return {
|
|
||||||
success: false,
|
|
||||||
error:
|
|
||||||
"Failed to bill team. Insufficient credits or subscription not found.",
|
|
||||||
returnCode: 402,
|
|
||||||
};
|
|
||||||
}
|
|
||||||
|
|
||||||
return {
|
|
||||||
success: true,
|
|
||||||
data: filteredDocs[0],
|
|
||||||
returnCode: 200,
|
|
||||||
};
|
|
||||||
}
|
|
||||||
|
|
||||||
export async function scrapeController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
// make sure to authenticate user first, Bearer <token>
|
|
||||||
const { success, team_id, error, status, plan } = await authenticateUser(
|
|
||||||
req,
|
|
||||||
res,
|
|
||||||
RateLimiterMode.Scrape
|
|
||||||
);
|
|
||||||
if (!success) {
|
|
||||||
return res.status(status).json({ error });
|
|
||||||
}
|
|
||||||
const crawlerOptions = req.body.crawlerOptions ?? {};
|
|
||||||
const pageOptions = req.body.pageOptions ?? { onlyMainContent: false, includeHtml: false, waitFor: 0, screenshot: false };
|
|
||||||
const extractorOptions = req.body.extractorOptions ?? {
|
|
||||||
mode: "markdown"
|
|
||||||
}
|
|
||||||
if (extractorOptions.mode === "llm-extraction") {
|
|
||||||
pageOptions.onlyMainContent = true;
|
|
||||||
}
|
|
||||||
const origin = req.body.origin ?? "api";
|
|
||||||
const timeout = req.body.timeout ?? 30000; // Default timeout of 30 seconds
|
|
||||||
|
|
||||||
try {
|
|
||||||
const { success: creditsCheckSuccess, message: creditsCheckMessage } =
|
|
||||||
await checkTeamCredits(team_id, 1);
|
|
||||||
if (!creditsCheckSuccess) {
|
|
||||||
return res.status(402).json({ error: "Insufficient credits" });
|
|
||||||
}
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: "Internal server error" });
|
|
||||||
}
|
|
||||||
const startTime = new Date().getTime();
|
|
||||||
const result = await scrapeHelper(
|
|
||||||
req,
|
|
||||||
team_id,
|
|
||||||
crawlerOptions,
|
|
||||||
pageOptions,
|
|
||||||
extractorOptions,
|
|
||||||
timeout,
|
|
||||||
plan
|
|
||||||
);
|
|
||||||
const endTime = new Date().getTime();
|
|
||||||
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
|
||||||
const numTokens = (result.data && result.data.markdown) ? numTokensFromString(result.data.markdown, "gpt-3.5-turbo") : 0;
|
|
||||||
|
|
||||||
logJob({
|
|
||||||
success: result.success,
|
|
||||||
message: result.error,
|
|
||||||
num_docs: 1,
|
|
||||||
docs: [result.data],
|
|
||||||
time_taken: timeTakenInSeconds,
|
|
||||||
team_id: team_id,
|
|
||||||
mode: "scrape",
|
|
||||||
url: req.body.url,
|
|
||||||
crawlerOptions: crawlerOptions,
|
|
||||||
pageOptions: pageOptions,
|
|
||||||
origin: origin,
|
|
||||||
extractor_options: extractorOptions,
|
|
||||||
num_tokens: numTokens,
|
|
||||||
});
|
|
||||||
return res.status(result.returnCode).json(result);
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
@ -1,26 +0,0 @@
|
||||||
import { Request, Response } from "express";
|
|
||||||
import { getWebScraperQueue } from "../../src/services/queue-service";
|
|
||||||
|
|
||||||
export async function crawlJobStatusPreviewController(req: Request, res: Response) {
|
|
||||||
try {
|
|
||||||
const job = await getWebScraperQueue().getJob(req.params.jobId);
|
|
||||||
if (!job) {
|
|
||||||
return res.status(404).json({ error: "Job not found" });
|
|
||||||
}
|
|
||||||
|
|
||||||
const { current, current_url, total, current_step, partialDocs } = await job.progress();
|
|
||||||
res.json({
|
|
||||||
status: await job.getState(),
|
|
||||||
// progress: job.progress(),
|
|
||||||
current: current,
|
|
||||||
current_url: current_url,
|
|
||||||
current_step: current_step,
|
|
||||||
total: total,
|
|
||||||
data: job.returnvalue,
|
|
||||||
partial_data: partialDocs ?? [],
|
|
||||||
});
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
}
|
|
||||||
22
apps/api/src/controllers/v0/admin/acuc-cache-clear.ts
Normal file
22
apps/api/src/controllers/v0/admin/acuc-cache-clear.ts
Normal file
|
|
@ -0,0 +1,22 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { supabase_service } from "../../../services/supabase";
|
||||||
|
import { clearACUC } from "../../auth";
|
||||||
|
import { Logger } from "../../../lib/logger";
|
||||||
|
|
||||||
|
export async function acucCacheClearController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const team_id: string = req.body.team_id;
|
||||||
|
|
||||||
|
const keys = await supabase_service
|
||||||
|
.from("api_keys")
|
||||||
|
.select("*")
|
||||||
|
.eq("team_id", team_id);
|
||||||
|
|
||||||
|
await Promise.all(keys.data.map((x) => clearACUC(x.key)));
|
||||||
|
|
||||||
|
res.json({ ok: true });
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error clearing ACUC cache via API route: ${error}`);
|
||||||
|
res.status(500).json({ error: "Internal server error" });
|
||||||
|
}
|
||||||
|
}
|
||||||
199
apps/api/src/controllers/v0/admin/queue.ts
Normal file
199
apps/api/src/controllers/v0/admin/queue.ts
Normal file
|
|
@ -0,0 +1,199 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
|
||||||
|
import { Job } from "bullmq";
|
||||||
|
import { Logger } from "../../../lib/logger";
|
||||||
|
import { getScrapeQueue } from "../../../services/queue-service";
|
||||||
|
import { checkAlerts } from "../../../services/alerts";
|
||||||
|
import { sendSlackWebhook } from "../../../services/alerts/slack";
|
||||||
|
|
||||||
|
export async function cleanBefore24hCompleteJobsController(
|
||||||
|
req: Request,
|
||||||
|
res: Response
|
||||||
|
) {
|
||||||
|
Logger.info("🐂 Cleaning jobs older than 24h");
|
||||||
|
try {
|
||||||
|
const scrapeQueue = getScrapeQueue();
|
||||||
|
const batchSize = 10;
|
||||||
|
const numberOfBatches = 9; // Adjust based on your needs
|
||||||
|
const completedJobsPromises: Promise<Job[]>[] = [];
|
||||||
|
for (let i = 0; i < numberOfBatches; i++) {
|
||||||
|
completedJobsPromises.push(
|
||||||
|
scrapeQueue.getJobs(
|
||||||
|
["completed"],
|
||||||
|
i * batchSize,
|
||||||
|
i * batchSize + batchSize,
|
||||||
|
true
|
||||||
|
)
|
||||||
|
);
|
||||||
|
}
|
||||||
|
const completedJobs: Job[] = (
|
||||||
|
await Promise.all(completedJobsPromises)
|
||||||
|
).flat();
|
||||||
|
const before24hJobs =
|
||||||
|
completedJobs.filter(
|
||||||
|
(job) => job.finishedOn < Date.now() - 24 * 60 * 60 * 1000
|
||||||
|
) || [];
|
||||||
|
|
||||||
|
let count = 0;
|
||||||
|
|
||||||
|
if (!before24hJobs) {
|
||||||
|
return res.status(200).send(`No jobs to remove.`);
|
||||||
|
}
|
||||||
|
|
||||||
|
for (const job of before24hJobs) {
|
||||||
|
try {
|
||||||
|
await job.remove();
|
||||||
|
count++;
|
||||||
|
} catch (jobError) {
|
||||||
|
Logger.error(`🐂 Failed to remove job with ID ${job.id}: ${jobError}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return res.status(200).send(`Removed ${count} completed jobs.`);
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`🐂 Failed to clean last 24h complete jobs: ${error}`);
|
||||||
|
return res.status(500).send("Failed to clean jobs");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function checkQueuesController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
await checkAlerts();
|
||||||
|
return res.status(200).send("Alerts initialized");
|
||||||
|
} catch (error) {
|
||||||
|
Logger.debug(`Failed to initialize alerts: ${error}`);
|
||||||
|
return res.status(500).send("Failed to initialize alerts");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Use this as a "health check" that way we dont destroy the server
|
||||||
|
export async function queuesController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const scrapeQueue = getScrapeQueue();
|
||||||
|
|
||||||
|
const [webScraperActive] = await Promise.all([
|
||||||
|
scrapeQueue.getActiveCount(),
|
||||||
|
]);
|
||||||
|
|
||||||
|
const noActiveJobs = webScraperActive === 0;
|
||||||
|
// 200 if no active jobs, 503 if there are active jobs
|
||||||
|
return res.status(noActiveJobs ? 200 : 500).json({
|
||||||
|
webScraperActive,
|
||||||
|
noActiveJobs,
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function autoscalerController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const maxNumberOfMachines = 80;
|
||||||
|
const minNumberOfMachines = 20;
|
||||||
|
|
||||||
|
const scrapeQueue = getScrapeQueue();
|
||||||
|
|
||||||
|
const [webScraperActive, webScraperWaiting, webScraperPriority] =
|
||||||
|
await Promise.all([
|
||||||
|
scrapeQueue.getActiveCount(),
|
||||||
|
scrapeQueue.getWaitingCount(),
|
||||||
|
scrapeQueue.getPrioritizedCount(),
|
||||||
|
]);
|
||||||
|
|
||||||
|
let waitingAndPriorityCount = webScraperWaiting + webScraperPriority;
|
||||||
|
|
||||||
|
// get number of machines active
|
||||||
|
const request = await fetch(
|
||||||
|
"https://api.machines.dev/v1/apps/firecrawl-scraper-js/machines",
|
||||||
|
{
|
||||||
|
headers: {
|
||||||
|
Authorization: `Bearer ${process.env.FLY_API_TOKEN}`,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
);
|
||||||
|
const machines = await request.json();
|
||||||
|
|
||||||
|
// Only worker machines
|
||||||
|
const activeMachines = machines.filter(
|
||||||
|
(machine) =>
|
||||||
|
(machine.state === "started" ||
|
||||||
|
machine.state === "starting" ||
|
||||||
|
machine.state === "replacing") &&
|
||||||
|
machine.config.env["FLY_PROCESS_GROUP"] === "worker"
|
||||||
|
).length;
|
||||||
|
|
||||||
|
let targetMachineCount = activeMachines;
|
||||||
|
|
||||||
|
const baseScaleUp = 10;
|
||||||
|
// Slow scale down
|
||||||
|
const baseScaleDown = 2;
|
||||||
|
|
||||||
|
// Scale up logic
|
||||||
|
if (webScraperActive > 9000 || waitingAndPriorityCount > 2000) {
|
||||||
|
targetMachineCount = Math.min(
|
||||||
|
maxNumberOfMachines,
|
||||||
|
activeMachines + baseScaleUp * 3
|
||||||
|
);
|
||||||
|
} else if (webScraperActive > 5000 || waitingAndPriorityCount > 1000) {
|
||||||
|
targetMachineCount = Math.min(
|
||||||
|
maxNumberOfMachines,
|
||||||
|
activeMachines + baseScaleUp * 2
|
||||||
|
);
|
||||||
|
} else if (webScraperActive > 1000 || waitingAndPriorityCount > 500) {
|
||||||
|
targetMachineCount = Math.min(
|
||||||
|
maxNumberOfMachines,
|
||||||
|
activeMachines + baseScaleUp
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Scale down logic
|
||||||
|
if (webScraperActive < 100 && waitingAndPriorityCount < 50) {
|
||||||
|
targetMachineCount = Math.max(
|
||||||
|
minNumberOfMachines,
|
||||||
|
activeMachines - baseScaleDown * 3
|
||||||
|
);
|
||||||
|
} else if (webScraperActive < 500 && waitingAndPriorityCount < 200) {
|
||||||
|
targetMachineCount = Math.max(
|
||||||
|
minNumberOfMachines,
|
||||||
|
activeMachines - baseScaleDown * 2
|
||||||
|
);
|
||||||
|
} else if (webScraperActive < 1000 && waitingAndPriorityCount < 500) {
|
||||||
|
targetMachineCount = Math.max(
|
||||||
|
minNumberOfMachines,
|
||||||
|
activeMachines - baseScaleDown
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
if (targetMachineCount !== activeMachines) {
|
||||||
|
Logger.info(
|
||||||
|
`🐂 Scaling from ${activeMachines} to ${targetMachineCount} - ${webScraperActive} active, ${webScraperWaiting} waiting`
|
||||||
|
);
|
||||||
|
|
||||||
|
if (targetMachineCount > activeMachines) {
|
||||||
|
sendSlackWebhook(
|
||||||
|
`🐂 Scaling from ${activeMachines} to ${targetMachineCount} - ${webScraperActive} active, ${webScraperWaiting} waiting - Current DateTime: ${new Date().toISOString()}`,
|
||||||
|
false,
|
||||||
|
process.env.SLACK_AUTOSCALER ?? ""
|
||||||
|
);
|
||||||
|
} else {
|
||||||
|
sendSlackWebhook(
|
||||||
|
`🐂 Scaling from ${activeMachines} to ${targetMachineCount} - ${webScraperActive} active, ${webScraperWaiting} waiting - Current DateTime: ${new Date().toISOString()}`,
|
||||||
|
false,
|
||||||
|
process.env.SLACK_AUTOSCALER ?? ""
|
||||||
|
);
|
||||||
|
}
|
||||||
|
return res.status(200).json({
|
||||||
|
mode: "scale-descale",
|
||||||
|
count: targetMachineCount,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
return res.status(200).json({
|
||||||
|
mode: "normal",
|
||||||
|
count: activeMachines,
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).send("Failed to initialize autoscaler");
|
||||||
|
}
|
||||||
|
}
|
||||||
85
apps/api/src/controllers/v0/admin/redis-health.ts
Normal file
85
apps/api/src/controllers/v0/admin/redis-health.ts
Normal file
|
|
@ -0,0 +1,85 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import Redis from "ioredis";
|
||||||
|
import { Logger } from "../../../lib/logger";
|
||||||
|
import { redisRateLimitClient } from "../../../services/rate-limiter";
|
||||||
|
|
||||||
|
export async function redisHealthController(req: Request, res: Response) {
|
||||||
|
const retryOperation = async (operation, retries = 3) => {
|
||||||
|
for (let attempt = 1; attempt <= retries; attempt++) {
|
||||||
|
try {
|
||||||
|
return await operation();
|
||||||
|
} catch (error) {
|
||||||
|
if (attempt === retries) throw error;
|
||||||
|
Logger.warn(`Attempt ${attempt} failed: ${error.message}. Retrying...`);
|
||||||
|
await new Promise((resolve) => setTimeout(resolve, 2000)); // Wait 2 seconds before retrying
|
||||||
|
}
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
||||||
|
try {
|
||||||
|
const queueRedis = new Redis(process.env.REDIS_URL);
|
||||||
|
|
||||||
|
const testKey = "test";
|
||||||
|
const testValue = "test";
|
||||||
|
|
||||||
|
// Test queueRedis
|
||||||
|
let queueRedisHealth;
|
||||||
|
try {
|
||||||
|
await retryOperation(() => queueRedis.set(testKey, testValue));
|
||||||
|
queueRedisHealth = await retryOperation(() => queueRedis.get(testKey));
|
||||||
|
await retryOperation(() => queueRedis.del(testKey));
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`queueRedis health check failed: ${error}`);
|
||||||
|
queueRedisHealth = null;
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test redisRateLimitClient
|
||||||
|
let redisRateLimitHealth;
|
||||||
|
try {
|
||||||
|
await retryOperation(() => redisRateLimitClient.set(testKey, testValue));
|
||||||
|
redisRateLimitHealth = await retryOperation(() =>
|
||||||
|
redisRateLimitClient.get(testKey)
|
||||||
|
);
|
||||||
|
await retryOperation(() => redisRateLimitClient.del(testKey));
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`redisRateLimitClient health check failed: ${error}`);
|
||||||
|
redisRateLimitHealth = null;
|
||||||
|
}
|
||||||
|
|
||||||
|
const healthStatus = {
|
||||||
|
queueRedis: queueRedisHealth === testValue ? "healthy" : "unhealthy",
|
||||||
|
redisRateLimitClient:
|
||||||
|
redisRateLimitHealth === testValue ? "healthy" : "unhealthy",
|
||||||
|
};
|
||||||
|
|
||||||
|
if (
|
||||||
|
healthStatus.queueRedis === "healthy" &&
|
||||||
|
healthStatus.redisRateLimitClient === "healthy"
|
||||||
|
) {
|
||||||
|
Logger.info("Both Redis instances are healthy");
|
||||||
|
return res.status(200).json({ status: "healthy", details: healthStatus });
|
||||||
|
} else {
|
||||||
|
Logger.info(
|
||||||
|
`Redis instances health check: ${JSON.stringify(healthStatus)}`
|
||||||
|
);
|
||||||
|
// await sendSlackWebhook(
|
||||||
|
// `[REDIS DOWN] Redis instances health check: ${JSON.stringify(
|
||||||
|
// healthStatus
|
||||||
|
// )}`,
|
||||||
|
// true
|
||||||
|
// );
|
||||||
|
return res
|
||||||
|
.status(500)
|
||||||
|
.json({ status: "unhealthy", details: healthStatus });
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Redis health check failed: ${error}`);
|
||||||
|
// await sendSlackWebhook(
|
||||||
|
// `[REDIS DOWN] Redis instances health check: ${error.message}`,
|
||||||
|
// true
|
||||||
|
// );
|
||||||
|
return res
|
||||||
|
.status(500)
|
||||||
|
.json({ status: "unhealthy", message: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
60
apps/api/src/controllers/v0/crawl-cancel.ts
Normal file
60
apps/api/src/controllers/v0/crawl-cancel.ts
Normal file
|
|
@ -0,0 +1,60 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { RateLimiterMode } from "../../../src/types";
|
||||||
|
import { supabase_service } from "../../../src/services/supabase";
|
||||||
|
import { Logger } from "../../../src/lib/logger";
|
||||||
|
import { getCrawl, saveCrawl } from "../../../src/lib/crawl-redis";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
export async function crawlCancelController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
|
||||||
|
const { success, team_id, error, status } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
RateLimiterMode.CrawlStatus
|
||||||
|
);
|
||||||
|
if (!success) {
|
||||||
|
return res.status(status).json({ error });
|
||||||
|
}
|
||||||
|
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return res.status(404).json({ error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
// check if the job belongs to the team
|
||||||
|
if (useDbAuthentication) {
|
||||||
|
const { data, error: supaError } = await supabase_service
|
||||||
|
.from("bulljobs_teams")
|
||||||
|
.select("*")
|
||||||
|
.eq("job_id", req.params.jobId)
|
||||||
|
.eq("team_id", team_id);
|
||||||
|
if (supaError) {
|
||||||
|
return res.status(500).json({ error: supaError.message });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (data.length === 0) {
|
||||||
|
return res.status(403).json({ error: "Unauthorized" });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
sc.cancelled = true;
|
||||||
|
await saveCrawl(req.params.jobId, sc);
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
}
|
||||||
|
|
||||||
|
res.json({
|
||||||
|
status: "cancelled"
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
101
apps/api/src/controllers/v0/crawl-status.ts
Normal file
101
apps/api/src/controllers/v0/crawl-status.ts
Normal file
|
|
@ -0,0 +1,101 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { RateLimiterMode } from "../../../src/types";
|
||||||
|
import { getScrapeQueue } from "../../../src/services/queue-service";
|
||||||
|
import { Logger } from "../../../src/lib/logger";
|
||||||
|
import { getCrawl, getCrawlJobs } from "../../../src/lib/crawl-redis";
|
||||||
|
import { supabaseGetJobsByCrawlId } from "../../../src/lib/supabase-jobs";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
export async function getJobs(crawlId: string, ids: string[]) {
|
||||||
|
const jobs = (await Promise.all(ids.map(x => getScrapeQueue().getJob(x)))).filter(x => x);
|
||||||
|
|
||||||
|
if (process.env.USE_DB_AUTHENTICATION === "true") {
|
||||||
|
const supabaseData = await supabaseGetJobsByCrawlId(crawlId);
|
||||||
|
|
||||||
|
supabaseData.forEach(x => {
|
||||||
|
const job = jobs.find(y => y.id === x.job_id);
|
||||||
|
if (job) {
|
||||||
|
job.returnvalue = x.docs;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
jobs.forEach(job => {
|
||||||
|
job.returnvalue = Array.isArray(job.returnvalue) ? job.returnvalue[0] : job.returnvalue;
|
||||||
|
});
|
||||||
|
|
||||||
|
return jobs;
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function crawlStatusController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const { success, team_id, error, status } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
RateLimiterMode.CrawlStatus
|
||||||
|
);
|
||||||
|
if (!success) {
|
||||||
|
return res.status(status).json({ error });
|
||||||
|
}
|
||||||
|
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return res.status(404).json({ error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sc.team_id !== team_id) {
|
||||||
|
return res.status(403).json({ error: "Forbidden" });
|
||||||
|
}
|
||||||
|
let jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
let jobs = await getJobs(req.params.jobId, jobIDs);
|
||||||
|
let jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
||||||
|
|
||||||
|
// Combine jobs and jobStatuses into a single array of objects
|
||||||
|
let jobsWithStatuses = jobs.map((job, index) => ({
|
||||||
|
job,
|
||||||
|
status: jobStatuses[index]
|
||||||
|
}));
|
||||||
|
|
||||||
|
// Filter out failed jobs
|
||||||
|
jobsWithStatuses = jobsWithStatuses.filter(x => x.status !== "failed" && x.status !== "unknown");
|
||||||
|
|
||||||
|
// Sort jobs by timestamp
|
||||||
|
jobsWithStatuses.sort((a, b) => a.job.timestamp - b.job.timestamp);
|
||||||
|
|
||||||
|
// Extract sorted jobs and statuses
|
||||||
|
jobs = jobsWithStatuses.map(x => x.job);
|
||||||
|
jobStatuses = jobsWithStatuses.map(x => x.status);
|
||||||
|
|
||||||
|
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : "active";
|
||||||
|
|
||||||
|
const data = jobs.filter(x => x.failedReason !== "Concurreny limit hit").map(x => Array.isArray(x.returnvalue) ? x.returnvalue[0] : x.returnvalue);
|
||||||
|
|
||||||
|
if (
|
||||||
|
jobs.length > 0 &&
|
||||||
|
jobs[0].data &&
|
||||||
|
jobs[0].data.pageOptions &&
|
||||||
|
!jobs[0].data.pageOptions.includeRawHtml
|
||||||
|
) {
|
||||||
|
data.forEach(item => {
|
||||||
|
if (item) {
|
||||||
|
delete item.rawHtml;
|
||||||
|
}
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
res.json({
|
||||||
|
status: jobStatus,
|
||||||
|
current: jobStatuses.filter(x => x === "completed" || x === "failed").length,
|
||||||
|
total: jobs.length,
|
||||||
|
data: jobStatus === "completed" ? data : null,
|
||||||
|
partial_data: jobStatus === "completed" ? [] : data.filter(x => x !== null),
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
232
apps/api/src/controllers/v0/crawl.ts
Normal file
232
apps/api/src/controllers/v0/crawl.ts
Normal file
|
|
@ -0,0 +1,232 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { checkTeamCredits } from "../../../src/services/billing/credit_billing";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { RateLimiterMode } from "../../../src/types";
|
||||||
|
import { addScrapeJob } from "../../../src/services/queue-jobs";
|
||||||
|
import { isUrlBlocked } from "../../../src/scraper/WebScraper/utils/blocklist";
|
||||||
|
import { logCrawl } from "../../../src/services/logging/crawl_log";
|
||||||
|
import { validateIdempotencyKey } from "../../../src/services/idempotency/validate";
|
||||||
|
import { createIdempotencyKey } from "../../../src/services/idempotency/create";
|
||||||
|
import { defaultCrawlPageOptions, defaultCrawlerOptions, defaultOrigin } from "../../../src/lib/default-values";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { Logger } from "../../../src/lib/logger";
|
||||||
|
import { addCrawlJob, addCrawlJobs, crawlToCrawler, lockURL, lockURLs, saveCrawl, StoredCrawl } from "../../../src/lib/crawl-redis";
|
||||||
|
import { getScrapeQueue } from "../../../src/services/queue-service";
|
||||||
|
import { checkAndUpdateURL } from "../../../src/lib/validateUrl";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
|
||||||
|
export async function crawlController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const { success, team_id, error, status, plan, chunk } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
RateLimiterMode.Crawl
|
||||||
|
);
|
||||||
|
if (!success) {
|
||||||
|
return res.status(status).json({ error });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (req.headers["x-idempotency-key"]) {
|
||||||
|
const isIdempotencyValid = await validateIdempotencyKey(req);
|
||||||
|
if (!isIdempotencyValid) {
|
||||||
|
return res.status(409).json({ error: "Idempotency key already used" });
|
||||||
|
}
|
||||||
|
try {
|
||||||
|
createIdempotencyKey(req);
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
const crawlerOptions = {
|
||||||
|
...defaultCrawlerOptions,
|
||||||
|
...req.body.crawlerOptions,
|
||||||
|
};
|
||||||
|
const pageOptions = { ...defaultCrawlPageOptions, ...req.body.pageOptions };
|
||||||
|
|
||||||
|
if (Array.isArray(crawlerOptions.includes)) {
|
||||||
|
for (const x of crawlerOptions.includes) {
|
||||||
|
try {
|
||||||
|
new RegExp(x);
|
||||||
|
} catch (e) {
|
||||||
|
return res.status(400).json({ error: e.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (Array.isArray(crawlerOptions.excludes)) {
|
||||||
|
for (const x of crawlerOptions.excludes) {
|
||||||
|
try {
|
||||||
|
new RegExp(x);
|
||||||
|
} catch (e) {
|
||||||
|
return res.status(400).json({ error: e.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
const limitCheck = req.body?.crawlerOptions?.limit ?? 1;
|
||||||
|
const { success: creditsCheckSuccess, message: creditsCheckMessage, remainingCredits } =
|
||||||
|
await checkTeamCredits(chunk, team_id, limitCheck);
|
||||||
|
|
||||||
|
if (!creditsCheckSuccess) {
|
||||||
|
return res.status(402).json({ error: "Insufficient credits. You may be requesting with a higher limit than the amount of credits you have left. If not, upgrade your plan at https://firecrawl.dev/pricing or contact us at hello@firecrawl.com" });
|
||||||
|
}
|
||||||
|
|
||||||
|
// TODO: need to do this to v1
|
||||||
|
crawlerOptions.limit = Math.min(remainingCredits, crawlerOptions.limit);
|
||||||
|
|
||||||
|
let url = req.body.url;
|
||||||
|
if (!url) {
|
||||||
|
return res.status(400).json({ error: "Url is required" });
|
||||||
|
}
|
||||||
|
if (typeof url !== "string") {
|
||||||
|
return res.status(400).json({ error: "URL must be a string" });
|
||||||
|
}
|
||||||
|
try {
|
||||||
|
url = checkAndUpdateURL(url).url;
|
||||||
|
} catch (e) {
|
||||||
|
return res
|
||||||
|
.status(e instanceof Error && e.message === "Invalid URL" ? 400 : 500)
|
||||||
|
.json({ error: e.message ?? e });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (isUrlBlocked(url)) {
|
||||||
|
return res.status(403).json({
|
||||||
|
error:
|
||||||
|
"Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
// if (mode === "single_urls" && !url.includes(",")) { // NOTE: do we need this?
|
||||||
|
// try {
|
||||||
|
// const a = new WebScraperDataProvider();
|
||||||
|
// await a.setOptions({
|
||||||
|
// jobId: uuidv4(),
|
||||||
|
// mode: "single_urls",
|
||||||
|
// urls: [url],
|
||||||
|
// crawlerOptions: { ...crawlerOptions, returnOnlyUrls: true },
|
||||||
|
// pageOptions: pageOptions,
|
||||||
|
// });
|
||||||
|
|
||||||
|
// const docs = await a.getDocuments(false, (progress) => {
|
||||||
|
// job.updateProgress({
|
||||||
|
// current: progress.current,
|
||||||
|
// total: progress.total,
|
||||||
|
// current_step: "SCRAPING",
|
||||||
|
// current_url: progress.currentDocumentUrl,
|
||||||
|
// });
|
||||||
|
// });
|
||||||
|
// return res.json({
|
||||||
|
// success: true,
|
||||||
|
// documents: docs,
|
||||||
|
// });
|
||||||
|
// } catch (error) {
|
||||||
|
// Logger.error(error);
|
||||||
|
// return res.status(500).json({ error: error.message });
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
|
||||||
|
await logCrawl(id, team_id);
|
||||||
|
|
||||||
|
const sc: StoredCrawl = {
|
||||||
|
originUrl: url,
|
||||||
|
crawlerOptions,
|
||||||
|
pageOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
createdAt: Date.now(),
|
||||||
|
};
|
||||||
|
|
||||||
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
|
try {
|
||||||
|
sc.robots = await crawler.getRobotsTxt();
|
||||||
|
} catch (_) {}
|
||||||
|
|
||||||
|
await saveCrawl(id, sc);
|
||||||
|
|
||||||
|
const sitemap = sc.crawlerOptions?.ignoreSitemap
|
||||||
|
? null
|
||||||
|
: await crawler.tryGetSitemap();
|
||||||
|
|
||||||
|
|
||||||
|
if (sitemap !== null && sitemap.length > 0) {
|
||||||
|
let jobPriority = 20;
|
||||||
|
// If it is over 1000, we need to get the job priority,
|
||||||
|
// otherwise we can use the default priority of 20
|
||||||
|
if(sitemap.length > 1000){
|
||||||
|
// set base to 21
|
||||||
|
jobPriority = await getJobPriority({plan, team_id, basePriority: 21})
|
||||||
|
}
|
||||||
|
const jobs = sitemap.map((x) => {
|
||||||
|
const url = x.url;
|
||||||
|
const uuid = uuidv4();
|
||||||
|
return {
|
||||||
|
name: uuid,
|
||||||
|
data: {
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: req.body.origin ?? defaultOrigin,
|
||||||
|
crawl_id: id,
|
||||||
|
sitemapped: true,
|
||||||
|
},
|
||||||
|
opts: {
|
||||||
|
jobId: uuid,
|
||||||
|
priority: jobPriority,
|
||||||
|
},
|
||||||
|
};
|
||||||
|
});
|
||||||
|
|
||||||
|
await lockURLs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.data.url)
|
||||||
|
);
|
||||||
|
await addCrawlJobs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.opts.jobId)
|
||||||
|
);
|
||||||
|
for (const job of jobs) {
|
||||||
|
// add with sentry instrumentation
|
||||||
|
await addScrapeJob(job.data as any, {}, job.opts.jobId);
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
await lockURL(id, sc, url);
|
||||||
|
|
||||||
|
// Not needed, first one should be 15.
|
||||||
|
// const jobPriority = await getJobPriority({plan, team_id, basePriority: 10})
|
||||||
|
|
||||||
|
const jobId = uuidv4();
|
||||||
|
await addScrapeJob(
|
||||||
|
{
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: req.body.origin ?? defaultOrigin,
|
||||||
|
crawl_id: id,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
priority: 15, // prioritize request 0 of crawl jobs same as scrape jobs
|
||||||
|
},
|
||||||
|
jobId,
|
||||||
|
);
|
||||||
|
await addCrawlJob(id, jobId);
|
||||||
|
}
|
||||||
|
|
||||||
|
res.json({ jobId: id });
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
142
apps/api/src/controllers/v0/crawlPreview.ts
Normal file
142
apps/api/src/controllers/v0/crawlPreview.ts
Normal file
|
|
@ -0,0 +1,142 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { RateLimiterMode } from "../../../src/types";
|
||||||
|
import { isUrlBlocked } from "../../../src/scraper/WebScraper/utils/blocklist";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { Logger } from "../../../src/lib/logger";
|
||||||
|
import { addCrawlJob, crawlToCrawler, lockURL, saveCrawl, StoredCrawl } from "../../../src/lib/crawl-redis";
|
||||||
|
import { addScrapeJob } from "../../../src/services/queue-jobs";
|
||||||
|
import { checkAndUpdateURL } from "../../../src/lib/validateUrl";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
export async function crawlPreviewController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const { success, error, status, team_id:a, plan } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
RateLimiterMode.Preview
|
||||||
|
);
|
||||||
|
|
||||||
|
const team_id = "preview";
|
||||||
|
|
||||||
|
if (!success) {
|
||||||
|
return res.status(status).json({ error });
|
||||||
|
}
|
||||||
|
|
||||||
|
let url = req.body.url;
|
||||||
|
if (!url) {
|
||||||
|
return res.status(400).json({ error: "Url is required" });
|
||||||
|
}
|
||||||
|
try {
|
||||||
|
url = checkAndUpdateURL(url).url;
|
||||||
|
} catch (e) {
|
||||||
|
return res
|
||||||
|
.status(e instanceof Error && e.message === "Invalid URL" ? 400 : 500)
|
||||||
|
.json({ error: e.message ?? e });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (isUrlBlocked(url)) {
|
||||||
|
return res
|
||||||
|
.status(403)
|
||||||
|
.json({
|
||||||
|
error:
|
||||||
|
"Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
const crawlerOptions = req.body.crawlerOptions ?? {};
|
||||||
|
const pageOptions = req.body.pageOptions ?? { onlyMainContent: false, includeHtml: false, removeTags: [] };
|
||||||
|
|
||||||
|
// if (mode === "single_urls" && !url.includes(",")) { // NOTE: do we need this?
|
||||||
|
// try {
|
||||||
|
// const a = new WebScraperDataProvider();
|
||||||
|
// await a.setOptions({
|
||||||
|
// jobId: uuidv4(),
|
||||||
|
// mode: "single_urls",
|
||||||
|
// urls: [url],
|
||||||
|
// crawlerOptions: { ...crawlerOptions, returnOnlyUrls: true },
|
||||||
|
// pageOptions: pageOptions,
|
||||||
|
// });
|
||||||
|
|
||||||
|
// const docs = await a.getDocuments(false, (progress) => {
|
||||||
|
// job.updateProgress({
|
||||||
|
// current: progress.current,
|
||||||
|
// total: progress.total,
|
||||||
|
// current_step: "SCRAPING",
|
||||||
|
// current_url: progress.currentDocumentUrl,
|
||||||
|
// });
|
||||||
|
// });
|
||||||
|
// return res.json({
|
||||||
|
// success: true,
|
||||||
|
// documents: docs,
|
||||||
|
// });
|
||||||
|
// } catch (error) {
|
||||||
|
// Logger.error(error);
|
||||||
|
// return res.status(500).json({ error: error.message });
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
|
||||||
|
let robots;
|
||||||
|
|
||||||
|
try {
|
||||||
|
robots = await this.getRobotsTxt();
|
||||||
|
} catch (_) {}
|
||||||
|
|
||||||
|
const sc: StoredCrawl = {
|
||||||
|
originUrl: url,
|
||||||
|
crawlerOptions,
|
||||||
|
pageOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
robots,
|
||||||
|
createdAt: Date.now(),
|
||||||
|
};
|
||||||
|
|
||||||
|
await saveCrawl(id, sc);
|
||||||
|
|
||||||
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
|
const sitemap = sc.crawlerOptions?.ignoreSitemap ? null : await crawler.tryGetSitemap();
|
||||||
|
|
||||||
|
if (sitemap !== null) {
|
||||||
|
for (const url of sitemap.map(x => x.url)) {
|
||||||
|
await lockURL(id, sc, url);
|
||||||
|
const jobId = uuidv4();
|
||||||
|
await addScrapeJob({
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: "website-preview",
|
||||||
|
crawl_id: id,
|
||||||
|
sitemapped: true,
|
||||||
|
}, {}, jobId);
|
||||||
|
await addCrawlJob(id, jobId);
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
await lockURL(id, sc, url);
|
||||||
|
const jobId = uuidv4();
|
||||||
|
await addScrapeJob({
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
team_id,
|
||||||
|
plan,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: "website-preview",
|
||||||
|
crawl_id: id,
|
||||||
|
}, {}, jobId);
|
||||||
|
await addCrawlJob(id, jobId);
|
||||||
|
}
|
||||||
|
|
||||||
|
res.json({ jobId: id });
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -1,8 +1,8 @@
|
||||||
|
|
||||||
import { AuthResponse, RateLimiterMode } from "../types";
|
import { AuthResponse, RateLimiterMode } from "../../types";
|
||||||
|
|
||||||
import { Request, Response } from "express";
|
import { Request, Response } from "express";
|
||||||
import { authenticateUser } from "./auth";
|
import { authenticateUser } from "../auth";
|
||||||
|
|
||||||
|
|
||||||
export const keyAuthController = async (req: Request, res: Response) => {
|
export const keyAuthController = async (req: Request, res: Response) => {
|
||||||
6
apps/api/src/controllers/v0/liveness.ts
Normal file
6
apps/api/src/controllers/v0/liveness.ts
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
|
||||||
|
export async function livenessController(req: Request, res: Response) {
|
||||||
|
//TODO: add checks if the application is live and healthy like checking the redis connection
|
||||||
|
res.status(200).json({ status: "ok" });
|
||||||
|
}
|
||||||
6
apps/api/src/controllers/v0/readiness.ts
Normal file
6
apps/api/src/controllers/v0/readiness.ts
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
|
||||||
|
export async function readinessController(req: Request, res: Response) {
|
||||||
|
// TODO: add checks when the application is ready to serve traffic
|
||||||
|
res.status(200).json({ status: "ok" });
|
||||||
|
}
|
||||||
296
apps/api/src/controllers/v0/scrape.ts
Normal file
296
apps/api/src/controllers/v0/scrape.ts
Normal file
|
|
@ -0,0 +1,296 @@
|
||||||
|
import { ExtractorOptions, PageOptions } from "./../../lib/entities";
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import {
|
||||||
|
billTeam,
|
||||||
|
checkTeamCredits,
|
||||||
|
} from "../../services/billing/credit_billing";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { PlanType, RateLimiterMode } from "../../types";
|
||||||
|
import { logJob } from "../../services/logging/log_job";
|
||||||
|
import { Document } from "../../lib/entities";
|
||||||
|
import { isUrlBlocked } from "../../scraper/WebScraper/utils/blocklist"; // Import the isUrlBlocked function
|
||||||
|
import { numTokensFromString } from "../../lib/LLM-extraction/helpers";
|
||||||
|
import {
|
||||||
|
defaultPageOptions,
|
||||||
|
defaultExtractorOptions,
|
||||||
|
defaultTimeout,
|
||||||
|
defaultOrigin,
|
||||||
|
} from "../../lib/default-values";
|
||||||
|
import { addScrapeJob, waitForJob } from "../../services/queue-jobs";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
|
||||||
|
export async function scrapeHelper(
|
||||||
|
jobId: string,
|
||||||
|
req: Request,
|
||||||
|
team_id: string,
|
||||||
|
crawlerOptions: any,
|
||||||
|
pageOptions: PageOptions,
|
||||||
|
extractorOptions: ExtractorOptions,
|
||||||
|
timeout: number,
|
||||||
|
plan?: PlanType
|
||||||
|
): Promise<{
|
||||||
|
success: boolean;
|
||||||
|
error?: string;
|
||||||
|
data?: Document;
|
||||||
|
returnCode: number;
|
||||||
|
}> {
|
||||||
|
const url = req.body.url;
|
||||||
|
if (typeof url !== "string") {
|
||||||
|
return { success: false, error: "Url is required", returnCode: 400 };
|
||||||
|
}
|
||||||
|
|
||||||
|
if (isUrlBlocked(url)) {
|
||||||
|
return {
|
||||||
|
success: false,
|
||||||
|
error:
|
||||||
|
"Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.",
|
||||||
|
returnCode: 403,
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
const jobPriority = await getJobPriority({ plan, team_id, basePriority: 10 });
|
||||||
|
|
||||||
|
await addScrapeJob(
|
||||||
|
{
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions,
|
||||||
|
team_id,
|
||||||
|
pageOptions,
|
||||||
|
plan,
|
||||||
|
extractorOptions,
|
||||||
|
origin: req.body.origin ?? defaultOrigin,
|
||||||
|
is_scrape: true,
|
||||||
|
},
|
||||||
|
{},
|
||||||
|
jobId,
|
||||||
|
jobPriority
|
||||||
|
);
|
||||||
|
|
||||||
|
let doc;
|
||||||
|
|
||||||
|
const err = await Sentry.startSpan(
|
||||||
|
{
|
||||||
|
name: "Wait for job to finish",
|
||||||
|
op: "bullmq.wait",
|
||||||
|
attributes: { job: jobId },
|
||||||
|
},
|
||||||
|
async (span) => {
|
||||||
|
try {
|
||||||
|
doc = (await waitForJob(jobId, timeout))[0];
|
||||||
|
} catch (e) {
|
||||||
|
if (e instanceof Error && e.message.startsWith("Job wait")) {
|
||||||
|
span.setAttribute("timedOut", true);
|
||||||
|
return {
|
||||||
|
success: false,
|
||||||
|
error: "Request timed out",
|
||||||
|
returnCode: 408,
|
||||||
|
};
|
||||||
|
} else if (
|
||||||
|
typeof e === "string" &&
|
||||||
|
(e.includes("Error generating completions: ") ||
|
||||||
|
e.includes("Invalid schema for function") ||
|
||||||
|
e.includes(
|
||||||
|
"LLM extraction did not match the extraction schema you provided."
|
||||||
|
))
|
||||||
|
) {
|
||||||
|
return {
|
||||||
|
success: false,
|
||||||
|
error: e,
|
||||||
|
returnCode: 500,
|
||||||
|
};
|
||||||
|
} else {
|
||||||
|
throw e;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
span.setAttribute("result", JSON.stringify(doc));
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
);
|
||||||
|
|
||||||
|
if (err !== null) {
|
||||||
|
return err;
|
||||||
|
}
|
||||||
|
|
||||||
|
await getScrapeQueue().remove(jobId);
|
||||||
|
|
||||||
|
if (!doc) {
|
||||||
|
console.error("!!! PANIC DOC IS", doc);
|
||||||
|
return {
|
||||||
|
success: true,
|
||||||
|
error: "No page found",
|
||||||
|
returnCode: 200,
|
||||||
|
data: doc,
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
delete doc.index;
|
||||||
|
delete doc.provider;
|
||||||
|
|
||||||
|
// Remove rawHtml if pageOptions.rawHtml is false and extractorOptions.mode is llm-extraction-from-raw-html
|
||||||
|
if (
|
||||||
|
!pageOptions.includeRawHtml &&
|
||||||
|
extractorOptions.mode == "llm-extraction-from-raw-html"
|
||||||
|
) {
|
||||||
|
if (doc.rawHtml) {
|
||||||
|
delete doc.rawHtml;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!pageOptions.includeHtml) {
|
||||||
|
if (doc.html) {
|
||||||
|
delete doc.html;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return {
|
||||||
|
success: true,
|
||||||
|
data: doc,
|
||||||
|
returnCode: 200,
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function scrapeController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
let earlyReturn = false;
|
||||||
|
// make sure to authenticate user first, Bearer <token>
|
||||||
|
const { success, team_id, error, status, plan, chunk } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
res,
|
||||||
|
RateLimiterMode.Scrape
|
||||||
|
);
|
||||||
|
if (!success) {
|
||||||
|
return res.status(status).json({ error });
|
||||||
|
}
|
||||||
|
|
||||||
|
const crawlerOptions = req.body.crawlerOptions ?? {};
|
||||||
|
const pageOptions = { ...defaultPageOptions, ...req.body.pageOptions };
|
||||||
|
const extractorOptions = {
|
||||||
|
...defaultExtractorOptions,
|
||||||
|
...req.body.extractorOptions,
|
||||||
|
};
|
||||||
|
const origin = req.body.origin ?? defaultOrigin;
|
||||||
|
let timeout = req.body.timeout ?? defaultTimeout;
|
||||||
|
|
||||||
|
if (extractorOptions.mode.includes("llm-extraction")) {
|
||||||
|
if (
|
||||||
|
typeof extractorOptions.extractionSchema !== "object" ||
|
||||||
|
extractorOptions.extractionSchema === null
|
||||||
|
) {
|
||||||
|
return res.status(400).json({
|
||||||
|
error:
|
||||||
|
"extractorOptions.extractionSchema must be an object if llm-extraction mode is specified",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
pageOptions.onlyMainContent = true;
|
||||||
|
timeout = req.body.timeout ?? 90000;
|
||||||
|
}
|
||||||
|
|
||||||
|
// checkCredits
|
||||||
|
try {
|
||||||
|
const { success: creditsCheckSuccess, message: creditsCheckMessage } =
|
||||||
|
await checkTeamCredits(chunk, team_id, 1);
|
||||||
|
if (!creditsCheckSuccess) {
|
||||||
|
earlyReturn = true;
|
||||||
|
return res.status(402).json({ error: "Insufficient credits. For more credits, you can upgrade your plan at https://firecrawl.dev/pricing" });
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
earlyReturn = true;
|
||||||
|
return res.status(500).json({
|
||||||
|
error:
|
||||||
|
"Error checking team credits. Please contact hello@firecrawl.com for help.",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
const jobId = uuidv4();
|
||||||
|
|
||||||
|
const startTime = new Date().getTime();
|
||||||
|
const result = await scrapeHelper(
|
||||||
|
jobId,
|
||||||
|
req,
|
||||||
|
team_id,
|
||||||
|
crawlerOptions,
|
||||||
|
pageOptions,
|
||||||
|
extractorOptions,
|
||||||
|
timeout,
|
||||||
|
plan
|
||||||
|
);
|
||||||
|
const endTime = new Date().getTime();
|
||||||
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
|
const numTokens =
|
||||||
|
result.data && result.data.markdown
|
||||||
|
? numTokensFromString(result.data.markdown, "gpt-3.5-turbo")
|
||||||
|
: 0;
|
||||||
|
|
||||||
|
if (result.success) {
|
||||||
|
let creditsToBeBilled = 1;
|
||||||
|
const creditsPerLLMExtract = 4;
|
||||||
|
|
||||||
|
if (extractorOptions.mode.includes("llm-extraction")) {
|
||||||
|
// creditsToBeBilled = creditsToBeBilled + (creditsPerLLMExtract * filteredDocs.length);
|
||||||
|
creditsToBeBilled += creditsPerLLMExtract;
|
||||||
|
}
|
||||||
|
|
||||||
|
let startTimeBilling = new Date().getTime();
|
||||||
|
|
||||||
|
if (earlyReturn) {
|
||||||
|
// Don't bill if we're early returning
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
if (creditsToBeBilled > 0) {
|
||||||
|
// billing for doc done on queue end, bill only for llm extraction
|
||||||
|
billTeam(team_id, chunk?.sub_id, creditsToBeBilled).catch(error => {
|
||||||
|
Logger.error(`Failed to bill team ${team_id} for ${creditsToBeBilled} credits: ${error}`);
|
||||||
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
let doc = result.data;
|
||||||
|
if (!pageOptions || !pageOptions.includeRawHtml) {
|
||||||
|
if (doc && doc.rawHtml) {
|
||||||
|
delete doc.rawHtml;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if(pageOptions && pageOptions.includeExtract) {
|
||||||
|
if(!pageOptions.includeMarkdown && doc && doc.markdown) {
|
||||||
|
delete doc.markdown;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
logJob({
|
||||||
|
job_id: jobId,
|
||||||
|
success: result.success,
|
||||||
|
message: result.error,
|
||||||
|
num_docs: 1,
|
||||||
|
docs: [doc],
|
||||||
|
time_taken: timeTakenInSeconds,
|
||||||
|
team_id: team_id,
|
||||||
|
mode: "scrape",
|
||||||
|
url: req.body.url,
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: origin,
|
||||||
|
extractor_options: extractorOptions,
|
||||||
|
num_tokens: numTokens,
|
||||||
|
});
|
||||||
|
|
||||||
|
return res.status(result.returnCode).json(result);
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({
|
||||||
|
error:
|
||||||
|
typeof error === "string"
|
||||||
|
? error
|
||||||
|
: error?.message ?? "Internal Server Error",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
@ -1,19 +1,28 @@
|
||||||
import { Request, Response } from "express";
|
import { Request, Response } from "express";
|
||||||
import { WebScraperDataProvider } from "../scraper/WebScraper";
|
import { WebScraperDataProvider } from "../../scraper/WebScraper";
|
||||||
import { billTeam, checkTeamCredits } from "../services/billing/credit_billing";
|
import { billTeam, checkTeamCredits } from "../../services/billing/credit_billing";
|
||||||
import { authenticateUser } from "./auth";
|
import { authenticateUser } from "../auth";
|
||||||
import { RateLimiterMode } from "../types";
|
import { PlanType, RateLimiterMode } from "../../types";
|
||||||
import { logJob } from "../services/logging/log_job";
|
import { logJob } from "../../services/logging/log_job";
|
||||||
import { PageOptions, SearchOptions } from "../lib/entities";
|
import { PageOptions, SearchOptions } from "../../lib/entities";
|
||||||
import { search } from "../search";
|
import { search } from "../../search";
|
||||||
import { isUrlBlocked } from "../scraper/WebScraper/utils/blocklist";
|
import { isUrlBlocked } from "../../scraper/WebScraper/utils/blocklist";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { addScrapeJob, waitForJob } from "../../services/queue-jobs";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
|
||||||
export async function searchHelper(
|
export async function searchHelper(
|
||||||
|
jobId: string,
|
||||||
req: Request,
|
req: Request,
|
||||||
team_id: string,
|
team_id: string,
|
||||||
|
subscription_id: string,
|
||||||
crawlerOptions: any,
|
crawlerOptions: any,
|
||||||
pageOptions: PageOptions,
|
pageOptions: PageOptions,
|
||||||
searchOptions: SearchOptions,
|
searchOptions: SearchOptions,
|
||||||
|
plan: PlanType
|
||||||
): Promise<{
|
): Promise<{
|
||||||
success: boolean;
|
success: boolean;
|
||||||
error?: string;
|
error?: string;
|
||||||
|
|
@ -28,7 +37,12 @@ export async function searchHelper(
|
||||||
|
|
||||||
const tbs = searchOptions.tbs ?? null;
|
const tbs = searchOptions.tbs ?? null;
|
||||||
const filter = searchOptions.filter ?? null;
|
const filter = searchOptions.filter ?? null;
|
||||||
const num_results = searchOptions.limit ?? 7;
|
let num_results = Math.min(searchOptions.limit ?? 7, 10);
|
||||||
|
|
||||||
|
if (team_id === "d97c4ceb-290b-4957-8432-2b2a02727d95") {
|
||||||
|
num_results = 1;
|
||||||
|
}
|
||||||
|
|
||||||
const num_results_buffer = Math.floor(num_results * 1.5);
|
const num_results_buffer = Math.floor(num_results * 1.5);
|
||||||
|
|
||||||
let res = await search({
|
let res = await search({
|
||||||
|
|
@ -46,18 +60,10 @@ export async function searchHelper(
|
||||||
|
|
||||||
|
|
||||||
if (justSearch) {
|
if (justSearch) {
|
||||||
const billingResult = await billTeam(
|
billTeam(team_id, subscription_id, res.length).catch(error => {
|
||||||
team_id,
|
Logger.error(`Failed to bill team ${team_id} for ${res.length} credits: ${error}`);
|
||||||
res.length
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
);
|
});
|
||||||
if (!billingResult.success) {
|
|
||||||
return {
|
|
||||||
success: false,
|
|
||||||
error:
|
|
||||||
"Failed to bill team. Insufficient credits or subscription not found.",
|
|
||||||
returnCode: 402,
|
|
||||||
};
|
|
||||||
}
|
|
||||||
return { success: true, data: res, returnCode: 200 };
|
return { success: true, data: res, returnCode: 200 };
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -70,51 +76,50 @@ export async function searchHelper(
|
||||||
return { success: true, error: "No search results found", returnCode: 200 };
|
return { success: true, error: "No search results found", returnCode: 200 };
|
||||||
}
|
}
|
||||||
|
|
||||||
|
const jobPriority = await getJobPriority({plan, team_id, basePriority: 20});
|
||||||
|
|
||||||
// filter out social media links
|
// filter out social media links
|
||||||
|
|
||||||
|
const jobDatas = res.map(x => {
|
||||||
const a = new WebScraperDataProvider();
|
const url = x.url;
|
||||||
await a.setOptions({
|
const uuid = uuidv4();
|
||||||
|
return {
|
||||||
|
name: uuid,
|
||||||
|
data: {
|
||||||
|
url,
|
||||||
mode: "single_urls",
|
mode: "single_urls",
|
||||||
urls: res.map((r) => r.url).slice(0, searchOptions.limit ?? 7),
|
crawlerOptions: crawlerOptions,
|
||||||
crawlerOptions: {
|
team_id: team_id,
|
||||||
...crawlerOptions,
|
pageOptions: pageOptions,
|
||||||
},
|
},
|
||||||
pageOptions: {
|
opts: {
|
||||||
...pageOptions,
|
jobId: uuid,
|
||||||
onlyMainContent: pageOptions?.onlyMainContent ?? true,
|
priority: jobPriority,
|
||||||
fetchPageContent: pageOptions?.fetchPageContent ?? true,
|
}
|
||||||
includeHtml: pageOptions?.includeHtml ?? false,
|
};
|
||||||
removeTags: pageOptions?.removeTags ?? [],
|
})
|
||||||
fallback: false,
|
|
||||||
},
|
// TODO: addScrapeJobs
|
||||||
});
|
for (const job of jobDatas) {
|
||||||
|
await addScrapeJob(job.data as any, {}, job.opts.jobId, job.opts.priority)
|
||||||
|
}
|
||||||
|
|
||||||
|
const docs = (await Promise.all(jobDatas.map(x => waitForJob(x.opts.jobId, 60000)))).map(x => x[0]);
|
||||||
|
|
||||||
const docs = await a.getDocuments(false);
|
|
||||||
if (docs.length === 0) {
|
if (docs.length === 0) {
|
||||||
return { success: true, error: "No search results found", returnCode: 200 };
|
return { success: true, error: "No search results found", returnCode: 200 };
|
||||||
}
|
}
|
||||||
|
|
||||||
|
const sq = getScrapeQueue();
|
||||||
|
await Promise.all(jobDatas.map(x => sq.remove(x.opts.jobId)));
|
||||||
|
|
||||||
// make sure doc.content is not empty
|
// make sure doc.content is not empty
|
||||||
const filteredDocs = docs.filter(
|
const filteredDocs = docs.filter(
|
||||||
(doc: { content?: string }) => doc.content && doc.content.trim().length > 0
|
(doc: { content?: string }) => doc && doc.content && doc.content.trim().length > 0
|
||||||
);
|
);
|
||||||
|
|
||||||
if (filteredDocs.length === 0) {
|
if (filteredDocs.length === 0) {
|
||||||
return { success: true, error: "No page found", returnCode: 200 };
|
return { success: true, error: "No page found", returnCode: 200, data: docs };
|
||||||
}
|
|
||||||
|
|
||||||
const billingResult = await billTeam(
|
|
||||||
team_id,
|
|
||||||
filteredDocs.length
|
|
||||||
);
|
|
||||||
if (!billingResult.success) {
|
|
||||||
return {
|
|
||||||
success: false,
|
|
||||||
error:
|
|
||||||
"Failed to bill team. Insufficient credits or subscription not found.",
|
|
||||||
returnCode: 402,
|
|
||||||
};
|
|
||||||
}
|
}
|
||||||
|
|
||||||
return {
|
return {
|
||||||
|
|
@ -127,7 +132,7 @@ export async function searchHelper(
|
||||||
export async function searchController(req: Request, res: Response) {
|
export async function searchController(req: Request, res: Response) {
|
||||||
try {
|
try {
|
||||||
// make sure to authenticate user first, Bearer <token>
|
// make sure to authenticate user first, Bearer <token>
|
||||||
const { success, team_id, error, status } = await authenticateUser(
|
const { success, team_id, error, status, plan, chunk } = await authenticateUser(
|
||||||
req,
|
req,
|
||||||
res,
|
res,
|
||||||
RateLimiterMode.Search
|
RateLimiterMode.Search
|
||||||
|
|
@ -137,37 +142,44 @@ export async function searchController(req: Request, res: Response) {
|
||||||
}
|
}
|
||||||
const crawlerOptions = req.body.crawlerOptions ?? {};
|
const crawlerOptions = req.body.crawlerOptions ?? {};
|
||||||
const pageOptions = req.body.pageOptions ?? {
|
const pageOptions = req.body.pageOptions ?? {
|
||||||
includeHtml: false,
|
includeHtml: req.body.pageOptions?.includeHtml ?? false,
|
||||||
onlyMainContent: true,
|
onlyMainContent: req.body.pageOptions?.onlyMainContent ?? false,
|
||||||
fetchPageContent: true,
|
fetchPageContent: req.body.pageOptions?.fetchPageContent ?? true,
|
||||||
removeTags: [],
|
removeTags: req.body.pageOptions?.removeTags ?? [],
|
||||||
fallback: false,
|
fallback: req.body.pageOptions?.fallback ?? false,
|
||||||
};
|
};
|
||||||
const origin = req.body.origin ?? "api";
|
const origin = req.body.origin ?? "api";
|
||||||
|
|
||||||
const searchOptions = req.body.searchOptions ?? { limit: 7 };
|
const searchOptions = req.body.searchOptions ?? { limit: 5 };
|
||||||
|
|
||||||
|
const jobId = uuidv4();
|
||||||
|
|
||||||
try {
|
try {
|
||||||
const { success: creditsCheckSuccess, message: creditsCheckMessage } =
|
const { success: creditsCheckSuccess, message: creditsCheckMessage } =
|
||||||
await checkTeamCredits(team_id, 1);
|
await checkTeamCredits(chunk, team_id, 1);
|
||||||
if (!creditsCheckSuccess) {
|
if (!creditsCheckSuccess) {
|
||||||
return res.status(402).json({ error: "Insufficient credits" });
|
return res.status(402).json({ error: "Insufficient credits" });
|
||||||
}
|
}
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(error);
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
return res.status(500).json({ error: "Internal server error" });
|
return res.status(500).json({ error: "Internal server error" });
|
||||||
}
|
}
|
||||||
const startTime = new Date().getTime();
|
const startTime = new Date().getTime();
|
||||||
const result = await searchHelper(
|
const result = await searchHelper(
|
||||||
|
jobId,
|
||||||
req,
|
req,
|
||||||
team_id,
|
team_id,
|
||||||
|
chunk?.sub_id,
|
||||||
crawlerOptions,
|
crawlerOptions,
|
||||||
pageOptions,
|
pageOptions,
|
||||||
searchOptions,
|
searchOptions,
|
||||||
|
plan
|
||||||
);
|
);
|
||||||
const endTime = new Date().getTime();
|
const endTime = new Date().getTime();
|
||||||
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
logJob({
|
logJob({
|
||||||
|
job_id: jobId,
|
||||||
success: result.success,
|
success: result.success,
|
||||||
message: result.error,
|
message: result.error,
|
||||||
num_docs: result.data ? result.data.length : 0,
|
num_docs: result.data ? result.data.length : 0,
|
||||||
|
|
@ -182,7 +194,12 @@ export async function searchController(req: Request, res: Response) {
|
||||||
});
|
});
|
||||||
return res.status(result.returnCode).json(result);
|
return res.status(result.returnCode).json(result);
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(error);
|
if (error instanceof Error && error.message.startsWith("Job wait")) {
|
||||||
|
return res.status(408).json({ error: "Request timed out" });
|
||||||
|
}
|
||||||
|
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
return res.status(500).json({ error: error.message });
|
return res.status(500).json({ error: error.message });
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
43
apps/api/src/controllers/v0/status.ts
Normal file
43
apps/api/src/controllers/v0/status.ts
Normal file
|
|
@ -0,0 +1,43 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { Logger } from "../../../src/lib/logger";
|
||||||
|
import { getCrawl, getCrawlJobs } from "../../../src/lib/crawl-redis";
|
||||||
|
import { getJobs } from "./crawl-status";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
export async function crawlJobStatusPreviewController(req: Request, res: Response) {
|
||||||
|
try {
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return res.status(404).json({ error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
const jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
|
||||||
|
// let data = job.returnvalue;
|
||||||
|
// if (process.env.USE_DB_AUTHENTICATION === "true") {
|
||||||
|
// const supabaseData = await supabaseGetJobById(req.params.jobId);
|
||||||
|
|
||||||
|
// if (supabaseData) {
|
||||||
|
// data = supabaseData.docs;
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
|
||||||
|
const jobs = (await getJobs(req.params.jobId, jobIDs)).sort((a, b) => a.timestamp - b.timestamp);
|
||||||
|
const jobStatuses = await Promise.all(jobs.map(x => x.getState()));
|
||||||
|
const jobStatus = sc.cancelled ? "failed" : jobStatuses.every(x => x === "completed") ? "completed" : jobStatuses.some(x => x === "failed") ? "failed" : "active";
|
||||||
|
|
||||||
|
const data = jobs.map(x => Array.isArray(x.returnvalue) ? x.returnvalue[0] : x.returnvalue);
|
||||||
|
|
||||||
|
res.json({
|
||||||
|
status: jobStatus,
|
||||||
|
current: jobStatuses.filter(x => x === "completed" || x === "failed").length,
|
||||||
|
total: jobs.length,
|
||||||
|
data: jobStatus === "completed" ? data : null,
|
||||||
|
partial_data: jobStatus === "completed" ? [] : data.filter(x => x !== null),
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
47
apps/api/src/controllers/v1/__tests__/crawl.test.ts.WIP
Normal file
47
apps/api/src/controllers/v1/__tests__/crawl.test.ts.WIP
Normal file
|
|
@ -0,0 +1,47 @@
|
||||||
|
import { crawlController } from '../crawl'
|
||||||
|
import { Request, Response } from 'express';
|
||||||
|
import { authenticateUser } from '../auth'; // Ensure this import is correct
|
||||||
|
import { createIdempotencyKey } from '../../services/idempotency/create';
|
||||||
|
import { validateIdempotencyKey } from '../../services/idempotency/validate';
|
||||||
|
import { v4 as uuidv4 } from 'uuid';
|
||||||
|
|
||||||
|
jest.mock('../auth', () => ({
|
||||||
|
authenticateUser: jest.fn().mockResolvedValue({
|
||||||
|
success: true,
|
||||||
|
team_id: 'team123',
|
||||||
|
error: null,
|
||||||
|
status: 200
|
||||||
|
}),
|
||||||
|
reduce: jest.fn()
|
||||||
|
}));
|
||||||
|
jest.mock('../../services/idempotency/validate');
|
||||||
|
|
||||||
|
describe('crawlController', () => {
|
||||||
|
it('should prevent duplicate requests using the same idempotency key', async () => {
|
||||||
|
const req = {
|
||||||
|
headers: {
|
||||||
|
'x-idempotency-key': await uuidv4(),
|
||||||
|
'Authorization': `Bearer ${process.env.TEST_API_KEY}`
|
||||||
|
},
|
||||||
|
body: {
|
||||||
|
url: 'https://mendable.ai'
|
||||||
|
}
|
||||||
|
} as unknown as Request;
|
||||||
|
const res = {
|
||||||
|
status: jest.fn().mockReturnThis(),
|
||||||
|
json: jest.fn()
|
||||||
|
} as unknown as Response;
|
||||||
|
|
||||||
|
// Mock the idempotency key validation to return false for the second call
|
||||||
|
(validateIdempotencyKey as jest.Mock).mockResolvedValueOnce(true).mockResolvedValueOnce(false);
|
||||||
|
|
||||||
|
// First request should succeed
|
||||||
|
await crawlController(req, res);
|
||||||
|
expect(res.status).not.toHaveBeenCalledWith(409);
|
||||||
|
|
||||||
|
// Second request with the same key should fail
|
||||||
|
await crawlController(req, res);
|
||||||
|
expect(res.status).toHaveBeenCalledWith(409);
|
||||||
|
expect(res.json).toHaveBeenCalledWith({ error: 'Idempotency key already used' });
|
||||||
|
});
|
||||||
|
});
|
||||||
64
apps/api/src/controllers/v1/__tests__/urlValidation.test.ts
Normal file
64
apps/api/src/controllers/v1/__tests__/urlValidation.test.ts
Normal file
|
|
@ -0,0 +1,64 @@
|
||||||
|
import { url } from "../types";
|
||||||
|
|
||||||
|
describe("URL Schema Validation", () => {
|
||||||
|
beforeEach(() => {
|
||||||
|
jest.resetAllMocks();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should prepend http:// to URLs without a protocol", () => {
|
||||||
|
const result = url.parse("example.com");
|
||||||
|
expect(result).toBe("http://example.com");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should allow valid URLs with http or https", () => {
|
||||||
|
expect(() => url.parse("http://example.com")).not.toThrow();
|
||||||
|
expect(() => url.parse("https://example.com")).not.toThrow();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should allow valid URLs with http or https", () => {
|
||||||
|
expect(() => url.parse("example.com")).not.toThrow();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject URLs with unsupported protocols", () => {
|
||||||
|
expect(() => url.parse("ftp://example.com")).toThrow("Invalid URL");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject URLs without a valid top-level domain", () => {
|
||||||
|
expect(() => url.parse("http://example")).toThrow("URL must have a valid top-level domain or be a valid path");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject blocked URLs", () => {
|
||||||
|
expect(() => url.parse("https://facebook.com")).toThrow("Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with subdomains correctly", () => {
|
||||||
|
expect(() => url.parse("http://sub.example.com")).not.toThrow();
|
||||||
|
expect(() => url.parse("https://blog.example.com")).not.toThrow();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with paths correctly", () => {
|
||||||
|
expect(() => url.parse("http://example.com/path")).not.toThrow();
|
||||||
|
expect(() => url.parse("https://example.com/another/path")).not.toThrow();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with subdomains that are blocked", () => {
|
||||||
|
expect(() => url.parse("https://sub.facebook.com")).toThrow("Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with paths that are blocked", () => {
|
||||||
|
expect(() => url.parse("http://facebook.com/path")).toThrow("Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.");
|
||||||
|
expect(() => url.parse("https://facebook.com/another/path")).toThrow("Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it.");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject malformed URLs starting with 'http://http'", () => {
|
||||||
|
expect(() => url.parse("http://http://example.com")).toThrow("Invalid URL. Invalid protocol.");
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject malformed URLs containing multiple 'http://'", () => {
|
||||||
|
expect(() => url.parse("http://example.com/http://example.com")).not.toThrow();
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should reject malformed URLs containing multiple 'http://'", () => {
|
||||||
|
expect(() => url.parse("http://ex ample.com/")).toThrow("Invalid URL");
|
||||||
|
});
|
||||||
|
})
|
||||||
102
apps/api/src/controllers/v1/batch-scrape.ts
Normal file
102
apps/api/src/controllers/v1/batch-scrape.ts
Normal file
|
|
@ -0,0 +1,102 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import {
|
||||||
|
BatchScrapeRequest,
|
||||||
|
batchScrapeRequestSchema,
|
||||||
|
CrawlResponse,
|
||||||
|
legacyExtractorOptions,
|
||||||
|
legacyScrapeOptions,
|
||||||
|
RequestWithAuth,
|
||||||
|
} from "./types";
|
||||||
|
import {
|
||||||
|
addCrawlJobs,
|
||||||
|
lockURLs,
|
||||||
|
saveCrawl,
|
||||||
|
StoredCrawl,
|
||||||
|
} from "../../lib/crawl-redis";
|
||||||
|
import { logCrawl } from "../../services/logging/crawl_log";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
import { addScrapeJobs } from "../../services/queue-jobs";
|
||||||
|
|
||||||
|
export async function batchScrapeController(
|
||||||
|
req: RequestWithAuth<{}, CrawlResponse, BatchScrapeRequest>,
|
||||||
|
res: Response<CrawlResponse>
|
||||||
|
) {
|
||||||
|
req.body = batchScrapeRequestSchema.parse(req.body);
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
|
||||||
|
await logCrawl(id, req.auth.team_id);
|
||||||
|
|
||||||
|
let { remainingCredits } = req.account;
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
if(!useDbAuthentication){
|
||||||
|
remainingCredits = Infinity;
|
||||||
|
}
|
||||||
|
|
||||||
|
const pageOptions = legacyScrapeOptions(req.body);
|
||||||
|
const extractorOptions = req.body.extract ? legacyExtractorOptions(req.body.extract) : undefined;
|
||||||
|
|
||||||
|
|
||||||
|
const sc: StoredCrawl = {
|
||||||
|
crawlerOptions: null,
|
||||||
|
pageOptions,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
createdAt: Date.now(),
|
||||||
|
plan: req.auth.plan,
|
||||||
|
};
|
||||||
|
|
||||||
|
await saveCrawl(id, sc);
|
||||||
|
|
||||||
|
let jobPriority = 20;
|
||||||
|
|
||||||
|
// If it is over 1000, we need to get the job priority,
|
||||||
|
// otherwise we can use the default priority of 20
|
||||||
|
if(req.body.urls.length > 1000){
|
||||||
|
// set base to 21
|
||||||
|
jobPriority = await getJobPriority({plan: req.auth.plan, team_id: req.auth.team_id, basePriority: 21})
|
||||||
|
}
|
||||||
|
|
||||||
|
const jobs = req.body.urls.map((x) => {
|
||||||
|
return {
|
||||||
|
data: {
|
||||||
|
url: x,
|
||||||
|
mode: "single_urls" as const,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
plan: req.auth.plan,
|
||||||
|
crawlerOptions: null,
|
||||||
|
pageOptions,
|
||||||
|
extractorOptions,
|
||||||
|
origin: "api",
|
||||||
|
crawl_id: id,
|
||||||
|
sitemapped: true,
|
||||||
|
v1: true,
|
||||||
|
},
|
||||||
|
opts: {
|
||||||
|
jobId: uuidv4(),
|
||||||
|
priority: 20,
|
||||||
|
},
|
||||||
|
};
|
||||||
|
});
|
||||||
|
|
||||||
|
await lockURLs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.data.url)
|
||||||
|
);
|
||||||
|
await addCrawlJobs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.opts.jobId)
|
||||||
|
);
|
||||||
|
await addScrapeJobs(jobs);
|
||||||
|
|
||||||
|
const protocol = process.env.ENV === "local" ? req.protocol : "https";
|
||||||
|
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
id,
|
||||||
|
url: `${protocol}://${req.get("host")}/v1/batch/scrape/${id}`,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
25
apps/api/src/controllers/v1/concurrency-check.ts
Normal file
25
apps/api/src/controllers/v1/concurrency-check.ts
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import {
|
||||||
|
ConcurrencyCheckParams,
|
||||||
|
ConcurrencyCheckResponse,
|
||||||
|
RequestWithAuth,
|
||||||
|
} from "./types";
|
||||||
|
import { RateLimiterMode } from "../../types";
|
||||||
|
import { Response } from "express";
|
||||||
|
import { redisConnection } from "../../services/queue-service";
|
||||||
|
// Basically just middleware and error wrapping
|
||||||
|
export async function concurrencyCheckController(
|
||||||
|
req: RequestWithAuth<ConcurrencyCheckParams, undefined, undefined>,
|
||||||
|
res: Response<ConcurrencyCheckResponse>
|
||||||
|
) {
|
||||||
|
const concurrencyLimiterKey = "concurrency-limiter:" + req.auth.team_id;
|
||||||
|
const now = Date.now();
|
||||||
|
const activeJobsOfTeam = await redisConnection.zrangebyscore(
|
||||||
|
concurrencyLimiterKey,
|
||||||
|
now,
|
||||||
|
Infinity
|
||||||
|
);
|
||||||
|
return res
|
||||||
|
.status(200)
|
||||||
|
.json({ success: true, concurrency: activeJobsOfTeam.length });
|
||||||
|
}
|
||||||
50
apps/api/src/controllers/v1/crawl-cancel.ts
Normal file
50
apps/api/src/controllers/v1/crawl-cancel.ts
Normal file
|
|
@ -0,0 +1,50 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { supabase_service } from "../../services/supabase";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { getCrawl, saveCrawl } from "../../lib/crawl-redis";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
import { RequestWithAuth } from "./types";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
export async function crawlCancelController(req: RequestWithAuth<{ jobId: string }>, res: Response) {
|
||||||
|
try {
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return res.status(404).json({ error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
// check if the job belongs to the team
|
||||||
|
if (useDbAuthentication) {
|
||||||
|
const { data, error: supaError } = await supabase_service
|
||||||
|
.from("bulljobs_teams")
|
||||||
|
.select("*")
|
||||||
|
.eq("job_id", req.params.jobId)
|
||||||
|
.eq("team_id", req.auth.team_id);
|
||||||
|
if (supaError) {
|
||||||
|
return res.status(500).json({ error: supaError.message });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (data.length === 0) {
|
||||||
|
return res.status(403).json({ error: "Unauthorized" });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
sc.cancelled = true;
|
||||||
|
await saveCrawl(req.params.jobId, sc);
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(error);
|
||||||
|
}
|
||||||
|
|
||||||
|
res.json({
|
||||||
|
status: "cancelled"
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
|
return res.status(500).json({ error: error.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
179
apps/api/src/controllers/v1/crawl-status-ws.ts
Normal file
179
apps/api/src/controllers/v1/crawl-status-ws.ts
Normal file
|
|
@ -0,0 +1,179 @@
|
||||||
|
import { authMiddleware } from "../../routes/v1";
|
||||||
|
import { RateLimiterMode } from "../../types";
|
||||||
|
import { authenticateUser } from "../auth";
|
||||||
|
import { CrawlStatusParams, CrawlStatusResponse, Document, ErrorResponse, legacyDocumentConverter, RequestWithAuth } from "./types";
|
||||||
|
import { WebSocket } from "ws";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { getCrawl, getCrawlExpiry, getCrawlJobs, getDoneJobsOrdered, getDoneJobsOrderedLength, getThrottledJobs, isCrawlFinished, isCrawlFinishedLocked } from "../../lib/crawl-redis";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { getJob, getJobs } from "./crawl-status";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
type ErrorMessage = {
|
||||||
|
type: "error",
|
||||||
|
error: string,
|
||||||
|
}
|
||||||
|
|
||||||
|
type CatchupMessage = {
|
||||||
|
type: "catchup",
|
||||||
|
data: CrawlStatusResponse,
|
||||||
|
}
|
||||||
|
|
||||||
|
type DocumentMessage = {
|
||||||
|
type: "document",
|
||||||
|
data: Document,
|
||||||
|
}
|
||||||
|
|
||||||
|
type DoneMessage = { type: "done" }
|
||||||
|
|
||||||
|
type Message = ErrorMessage | CatchupMessage | DoneMessage | DocumentMessage;
|
||||||
|
|
||||||
|
function send(ws: WebSocket, msg: Message) {
|
||||||
|
if (ws.readyState === 1) {
|
||||||
|
return new Promise((resolve, reject) => {
|
||||||
|
ws.send(JSON.stringify(msg), (err) => {
|
||||||
|
if (err) reject(err);
|
||||||
|
else resolve(null);
|
||||||
|
});
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
function close(ws: WebSocket, code: number, msg: Message) {
|
||||||
|
if (ws.readyState <= 1) {
|
||||||
|
ws.close(code, JSON.stringify(msg));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
async function crawlStatusWS(ws: WebSocket, req: RequestWithAuth<CrawlStatusParams, undefined, undefined>) {
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return close(ws, 1008, { type: "error", error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sc.team_id !== req.auth.team_id) {
|
||||||
|
return close(ws, 3003, { type: "error", error: "Forbidden" });
|
||||||
|
}
|
||||||
|
|
||||||
|
let doneJobIDs = [];
|
||||||
|
let finished = false;
|
||||||
|
|
||||||
|
const loop = async () => {
|
||||||
|
if (finished) return;
|
||||||
|
|
||||||
|
const jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
|
||||||
|
if (jobIDs.length === doneJobIDs.length) {
|
||||||
|
return close(ws, 1000, { type: "done" });
|
||||||
|
}
|
||||||
|
|
||||||
|
const notDoneJobIDs = jobIDs.filter(x => !doneJobIDs.includes(x));
|
||||||
|
const jobStatuses = await Promise.all(notDoneJobIDs.map(async x => [x, await getScrapeQueue().getJobState(x)]));
|
||||||
|
const newlyDoneJobIDs = jobStatuses.filter(x => x[1] === "completed" || x[1] === "failed").map(x => x[0]);
|
||||||
|
|
||||||
|
for (const jobID of newlyDoneJobIDs) {
|
||||||
|
const job = await getJob(jobID);
|
||||||
|
|
||||||
|
if (job.returnvalue) {
|
||||||
|
send(ws, {
|
||||||
|
type: "document",
|
||||||
|
data: legacyDocumentConverter(job.returnvalue),
|
||||||
|
})
|
||||||
|
} else {
|
||||||
|
return close(ws, 3000, { type: "error", error: job.failedReason });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
doneJobIDs.push(...newlyDoneJobIDs);
|
||||||
|
|
||||||
|
setTimeout(loop, 1000);
|
||||||
|
};
|
||||||
|
|
||||||
|
setTimeout(loop, 1000);
|
||||||
|
|
||||||
|
doneJobIDs = await getDoneJobsOrdered(req.params.jobId);
|
||||||
|
|
||||||
|
let jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
let jobStatuses = await Promise.all(jobIDs.map(async x => [x, await getScrapeQueue().getJobState(x)] as const));
|
||||||
|
const throttledJobs = new Set(...await getThrottledJobs(req.auth.team_id));
|
||||||
|
|
||||||
|
const throttledJobsSet = new Set(throttledJobs);
|
||||||
|
|
||||||
|
const validJobStatuses = [];
|
||||||
|
const validJobIDs = [];
|
||||||
|
|
||||||
|
for (const [id, status] of jobStatuses) {
|
||||||
|
if (!throttledJobsSet.has(id) && status !== "failed" && status !== "unknown") {
|
||||||
|
validJobStatuses.push([id, status]);
|
||||||
|
validJobIDs.push(id);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
const status: Exclude<CrawlStatusResponse, ErrorResponse>["status"] = sc.cancelled ? "cancelled" : validJobStatuses.every(x => x[1] === "completed") ? "completed" : "scraping";
|
||||||
|
|
||||||
|
jobIDs = validJobIDs; // Use validJobIDs instead of jobIDs for further processing
|
||||||
|
|
||||||
|
const doneJobs = await getJobs(doneJobIDs);
|
||||||
|
const data = doneJobs.map(x => x.returnvalue);
|
||||||
|
|
||||||
|
send(ws, {
|
||||||
|
type: "catchup",
|
||||||
|
data: {
|
||||||
|
success: true,
|
||||||
|
status,
|
||||||
|
total: jobIDs.length,
|
||||||
|
completed: doneJobIDs.length,
|
||||||
|
creditsUsed: jobIDs.length,
|
||||||
|
expiresAt: (await getCrawlExpiry(req.params.jobId)).toISOString(),
|
||||||
|
data: data.map(x => legacyDocumentConverter(x)),
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
if (status !== "scraping") {
|
||||||
|
finished = true;
|
||||||
|
return close(ws, 1000, { type: "done" });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Basically just middleware and error wrapping
|
||||||
|
export async function crawlStatusWSController(ws: WebSocket, req: RequestWithAuth<CrawlStatusParams, undefined, undefined>) {
|
||||||
|
try {
|
||||||
|
const { success, team_id, error, status, plan } = await authenticateUser(
|
||||||
|
req,
|
||||||
|
null,
|
||||||
|
RateLimiterMode.CrawlStatus,
|
||||||
|
);
|
||||||
|
|
||||||
|
if (!success) {
|
||||||
|
return close(ws, 3000, {
|
||||||
|
type: "error",
|
||||||
|
error,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
req.auth = { team_id, plan };
|
||||||
|
|
||||||
|
await crawlStatusWS(ws, req);
|
||||||
|
} catch (err) {
|
||||||
|
Sentry.captureException(err);
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
let verbose = JSON.stringify(err);
|
||||||
|
if (verbose === "{}") {
|
||||||
|
if (err instanceof Error) {
|
||||||
|
verbose = JSON.stringify({
|
||||||
|
message: err.message,
|
||||||
|
name: err.name,
|
||||||
|
stack: err.stack,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
Logger.error("Error occurred in WebSocket! (" + req.path + ") -- ID " + id + " -- " + verbose);
|
||||||
|
return close(ws, 1011, {
|
||||||
|
type: "error",
|
||||||
|
error: "An unexpected error occurred. Please contact hello@firecrawl.com for help. Your exception ID is " + id
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
148
apps/api/src/controllers/v1/crawl-status.ts
Normal file
148
apps/api/src/controllers/v1/crawl-status.ts
Normal file
|
|
@ -0,0 +1,148 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { CrawlStatusParams, CrawlStatusResponse, ErrorResponse, legacyDocumentConverter, RequestWithAuth } from "./types";
|
||||||
|
import { getCrawl, getCrawlExpiry, getCrawlJobs, getDoneJobsOrdered, getDoneJobsOrderedLength, getThrottledJobs } from "../../lib/crawl-redis";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { supabaseGetJobById, supabaseGetJobsById } from "../../lib/supabase-jobs";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
export async function getJob(id: string) {
|
||||||
|
const job = await getScrapeQueue().getJob(id);
|
||||||
|
if (!job) return job;
|
||||||
|
|
||||||
|
if (process.env.USE_DB_AUTHENTICATION === "true") {
|
||||||
|
const supabaseData = await supabaseGetJobById(id);
|
||||||
|
|
||||||
|
if (supabaseData) {
|
||||||
|
job.returnvalue = supabaseData.docs;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
job.returnvalue = Array.isArray(job.returnvalue) ? job.returnvalue[0] : job.returnvalue;
|
||||||
|
|
||||||
|
return job;
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getJobs(ids: string[]) {
|
||||||
|
const jobs = (await Promise.all(ids.map(x => getScrapeQueue().getJob(x)))).filter(x => x);
|
||||||
|
|
||||||
|
if (process.env.USE_DB_AUTHENTICATION === "true") {
|
||||||
|
const supabaseData = await supabaseGetJobsById(ids);
|
||||||
|
|
||||||
|
supabaseData.forEach(x => {
|
||||||
|
const job = jobs.find(y => y.id === x.job_id);
|
||||||
|
if (job) {
|
||||||
|
job.returnvalue = x.docs;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
}
|
||||||
|
|
||||||
|
jobs.forEach(job => {
|
||||||
|
job.returnvalue = Array.isArray(job.returnvalue) ? job.returnvalue[0] : job.returnvalue;
|
||||||
|
});
|
||||||
|
|
||||||
|
return jobs;
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function crawlStatusController(req: RequestWithAuth<CrawlStatusParams, undefined, CrawlStatusResponse>, res: Response<CrawlStatusResponse>, isBatch = false) {
|
||||||
|
const sc = await getCrawl(req.params.jobId);
|
||||||
|
if (!sc) {
|
||||||
|
return res.status(404).json({ success: false, error: "Job not found" });
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sc.team_id !== req.auth.team_id) {
|
||||||
|
return res.status(403).json({ success: false, error: "Forbidden" });
|
||||||
|
}
|
||||||
|
|
||||||
|
const start = typeof req.query.skip === "string" ? parseInt(req.query.skip, 10) : 0;
|
||||||
|
const end = typeof req.query.limit === "string" ? (start + parseInt(req.query.limit, 10) - 1) : undefined;
|
||||||
|
|
||||||
|
let jobIDs = await getCrawlJobs(req.params.jobId);
|
||||||
|
let jobStatuses = await Promise.all(jobIDs.map(async x => [x, await getScrapeQueue().getJobState(x)] as const));
|
||||||
|
const throttledJobs = new Set(...await getThrottledJobs(req.auth.team_id));
|
||||||
|
|
||||||
|
const throttledJobsSet = new Set(throttledJobs);
|
||||||
|
|
||||||
|
const validJobStatuses = [];
|
||||||
|
const validJobIDs = [];
|
||||||
|
|
||||||
|
for (const [id, status] of jobStatuses) {
|
||||||
|
if (!throttledJobsSet.has(id) && status !== "failed" && status !== "unknown") {
|
||||||
|
validJobStatuses.push([id, status]);
|
||||||
|
validJobIDs.push(id);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
const status: Exclude<CrawlStatusResponse, ErrorResponse>["status"] = sc.cancelled ? "cancelled" : validJobStatuses.every(x => x[1] === "completed") ? "completed" : "scraping";
|
||||||
|
|
||||||
|
// Use validJobIDs instead of jobIDs for further processing
|
||||||
|
jobIDs = validJobIDs;
|
||||||
|
|
||||||
|
const doneJobsLength = await getDoneJobsOrderedLength(req.params.jobId);
|
||||||
|
const doneJobsOrder = await getDoneJobsOrdered(req.params.jobId, start, end ?? -1);
|
||||||
|
|
||||||
|
let doneJobs = [];
|
||||||
|
|
||||||
|
if (end === undefined) { // determine 10 megabyte limit
|
||||||
|
let bytes = 0;
|
||||||
|
const bytesLimit = 10485760; // 10 MiB in bytes
|
||||||
|
const factor = 100; // chunking for faster retrieval
|
||||||
|
|
||||||
|
for (let i = 0; i < doneJobsOrder.length && bytes < bytesLimit; i += factor) {
|
||||||
|
// get current chunk and retrieve jobs
|
||||||
|
const currentIDs = doneJobsOrder.slice(i, i+factor);
|
||||||
|
const jobs = await getJobs(currentIDs);
|
||||||
|
|
||||||
|
// iterate through jobs and add them one them one to the byte counter
|
||||||
|
// both loops will break once we cross the byte counter
|
||||||
|
for (let ii = 0; ii < jobs.length && bytes < bytesLimit; ii++) {
|
||||||
|
const job = jobs[ii];
|
||||||
|
doneJobs.push(job);
|
||||||
|
bytes += JSON.stringify(legacyDocumentConverter(job.returnvalue)).length;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// if we ran over the bytes limit, remove the last document, except if it's the only document
|
||||||
|
if (bytes > bytesLimit && doneJobs.length !== 1) {
|
||||||
|
doneJobs.splice(doneJobs.length - 1, 1);
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
doneJobs = await getJobs(doneJobsOrder);
|
||||||
|
}
|
||||||
|
|
||||||
|
const data = doneJobs.map(x => x.returnvalue);
|
||||||
|
|
||||||
|
const protocol = process.env.ENV === "local" ? req.protocol : "https";
|
||||||
|
const nextURL = new URL(`${protocol}://${req.get("host")}/v1/${isBatch ? "batch/scrape" : "crawl"}/${req.params.jobId}`);
|
||||||
|
|
||||||
|
nextURL.searchParams.set("skip", (start + data.length).toString());
|
||||||
|
|
||||||
|
if (typeof req.query.limit === "string") {
|
||||||
|
nextURL.searchParams.set("limit", req.query.limit);
|
||||||
|
}
|
||||||
|
|
||||||
|
if (data.length > 0) {
|
||||||
|
if (!doneJobs[0].data.pageOptions.includeRawHtml) {
|
||||||
|
for (let ii = 0; ii < doneJobs.length; ii++) {
|
||||||
|
if (data[ii]) {
|
||||||
|
delete data[ii].rawHtml;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
status,
|
||||||
|
completed: doneJobsLength,
|
||||||
|
total: jobIDs.length,
|
||||||
|
creditsUsed: jobIDs.length,
|
||||||
|
expiresAt: (await getCrawlExpiry(req.params.jobId)).toISOString(),
|
||||||
|
next:
|
||||||
|
status !== "scraping" && (start + data.length) === doneJobsLength // if there's not gonna be any documents after this
|
||||||
|
? undefined
|
||||||
|
: nextURL.href,
|
||||||
|
data: data.map(x => legacyDocumentConverter(x)),
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
175
apps/api/src/controllers/v1/crawl.ts
Normal file
175
apps/api/src/controllers/v1/crawl.ts
Normal file
|
|
@ -0,0 +1,175 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import {
|
||||||
|
CrawlRequest,
|
||||||
|
crawlRequestSchema,
|
||||||
|
CrawlResponse,
|
||||||
|
legacyCrawlerOptions,
|
||||||
|
legacyScrapeOptions,
|
||||||
|
RequestWithAuth,
|
||||||
|
} from "./types";
|
||||||
|
import {
|
||||||
|
addCrawlJob,
|
||||||
|
addCrawlJobs,
|
||||||
|
crawlToCrawler,
|
||||||
|
lockURL,
|
||||||
|
lockURLs,
|
||||||
|
saveCrawl,
|
||||||
|
StoredCrawl,
|
||||||
|
} from "../../lib/crawl-redis";
|
||||||
|
import { logCrawl } from "../../services/logging/crawl_log";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
import { addScrapeJob } from "../../services/queue-jobs";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
import { callWebhook } from "../../services/webhook";
|
||||||
|
|
||||||
|
export async function crawlController(
|
||||||
|
req: RequestWithAuth<{}, CrawlResponse, CrawlRequest>,
|
||||||
|
res: Response<CrawlResponse>
|
||||||
|
) {
|
||||||
|
req.body = crawlRequestSchema.parse(req.body);
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
|
||||||
|
await logCrawl(id, req.auth.team_id);
|
||||||
|
|
||||||
|
let { remainingCredits } = req.account;
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
if(!useDbAuthentication){
|
||||||
|
remainingCredits = Infinity;
|
||||||
|
}
|
||||||
|
|
||||||
|
const crawlerOptions = legacyCrawlerOptions(req.body);
|
||||||
|
const pageOptions = legacyScrapeOptions(req.body.scrapeOptions);
|
||||||
|
|
||||||
|
// TODO: @rafa, is this right? copied from v0
|
||||||
|
if (Array.isArray(crawlerOptions.includes)) {
|
||||||
|
for (const x of crawlerOptions.includes) {
|
||||||
|
try {
|
||||||
|
new RegExp(x);
|
||||||
|
} catch (e) {
|
||||||
|
return res.status(400).json({ success: false, error: e.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if (Array.isArray(crawlerOptions.excludes)) {
|
||||||
|
for (const x of crawlerOptions.excludes) {
|
||||||
|
try {
|
||||||
|
new RegExp(x);
|
||||||
|
} catch (e) {
|
||||||
|
return res.status(400).json({ success: false, error: e.message });
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
crawlerOptions.limit = Math.min(remainingCredits, crawlerOptions.limit);
|
||||||
|
|
||||||
|
const sc: StoredCrawl = {
|
||||||
|
originUrl: req.body.url,
|
||||||
|
crawlerOptions,
|
||||||
|
pageOptions,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
createdAt: Date.now(),
|
||||||
|
plan: req.auth.plan,
|
||||||
|
};
|
||||||
|
|
||||||
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
|
try {
|
||||||
|
sc.robots = await crawler.getRobotsTxt(pageOptions.skipTlsVerification);
|
||||||
|
} catch (e) {
|
||||||
|
Logger.debug(
|
||||||
|
`[Crawl] Failed to get robots.txt (this is probably fine!): ${JSON.stringify(
|
||||||
|
e
|
||||||
|
)}`
|
||||||
|
);
|
||||||
|
}
|
||||||
|
|
||||||
|
await saveCrawl(id, sc);
|
||||||
|
|
||||||
|
const sitemap = sc.crawlerOptions.ignoreSitemap
|
||||||
|
? null
|
||||||
|
: await crawler.tryGetSitemap();
|
||||||
|
|
||||||
|
if (sitemap !== null && sitemap.length > 0) {
|
||||||
|
let jobPriority = 20;
|
||||||
|
// If it is over 1000, we need to get the job priority,
|
||||||
|
// otherwise we can use the default priority of 20
|
||||||
|
if(sitemap.length > 1000){
|
||||||
|
// set base to 21
|
||||||
|
jobPriority = await getJobPriority({plan: req.auth.plan, team_id: req.auth.team_id, basePriority: 21})
|
||||||
|
}
|
||||||
|
const jobs = sitemap.map((x) => {
|
||||||
|
const url = x.url;
|
||||||
|
const uuid = uuidv4();
|
||||||
|
return {
|
||||||
|
name: uuid,
|
||||||
|
data: {
|
||||||
|
url,
|
||||||
|
mode: "single_urls",
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
plan: req.auth.plan,
|
||||||
|
crawlerOptions,
|
||||||
|
pageOptions,
|
||||||
|
origin: "api",
|
||||||
|
crawl_id: id,
|
||||||
|
sitemapped: true,
|
||||||
|
webhook: req.body.webhook,
|
||||||
|
v1: true,
|
||||||
|
},
|
||||||
|
opts: {
|
||||||
|
jobId: uuid,
|
||||||
|
priority: 20,
|
||||||
|
},
|
||||||
|
};
|
||||||
|
});
|
||||||
|
|
||||||
|
await lockURLs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.data.url)
|
||||||
|
);
|
||||||
|
await addCrawlJobs(
|
||||||
|
id,
|
||||||
|
jobs.map((x) => x.opts.jobId)
|
||||||
|
);
|
||||||
|
await getScrapeQueue().addBulk(jobs);
|
||||||
|
} else {
|
||||||
|
await lockURL(id, sc, req.body.url);
|
||||||
|
const jobId = uuidv4();
|
||||||
|
await addScrapeJob(
|
||||||
|
{
|
||||||
|
url: req.body.url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: crawlerOptions,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
plan: req.auth.plan,
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: "api",
|
||||||
|
crawl_id: id,
|
||||||
|
webhook: req.body.webhook,
|
||||||
|
v1: true,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
priority: 15,
|
||||||
|
},
|
||||||
|
jobId,
|
||||||
|
);
|
||||||
|
await addCrawlJob(id, jobId);
|
||||||
|
}
|
||||||
|
|
||||||
|
if(req.body.webhook) {
|
||||||
|
await callWebhook(req.auth.team_id, id, null, req.body.webhook, true, "crawl.started");
|
||||||
|
}
|
||||||
|
|
||||||
|
const protocol = process.env.ENV === "local" ? req.protocol : "https";
|
||||||
|
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
id,
|
||||||
|
url: `${protocol}://${req.get("host")}/v1/crawl/${id}`,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
6
apps/api/src/controllers/v1/liveness.ts
Normal file
6
apps/api/src/controllers/v1/liveness.ts
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
|
||||||
|
export async function livenessController(req: Request, res: Response) {
|
||||||
|
//TODO: add checks if the application is live and healthy like checking the redis connection
|
||||||
|
res.status(200).json({ status: "ok" });
|
||||||
|
}
|
||||||
237
apps/api/src/controllers/v1/map.ts
Normal file
237
apps/api/src/controllers/v1/map.ts
Normal file
|
|
@ -0,0 +1,237 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import {
|
||||||
|
legacyCrawlerOptions,
|
||||||
|
mapRequestSchema,
|
||||||
|
RequestWithAuth,
|
||||||
|
} from "./types";
|
||||||
|
import { crawlToCrawler, StoredCrawl } from "../../lib/crawl-redis";
|
||||||
|
import { MapResponse, MapRequest } from "./types";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
import {
|
||||||
|
checkAndUpdateURLForMap,
|
||||||
|
isSameDomain,
|
||||||
|
isSameSubdomain,
|
||||||
|
removeDuplicateUrls,
|
||||||
|
} from "../../lib/validateUrl";
|
||||||
|
import { fireEngineMap } from "../../search/fireEngine";
|
||||||
|
import { billTeam } from "../../services/billing/credit_billing";
|
||||||
|
import { logJob } from "../../services/logging/log_job";
|
||||||
|
import { performCosineSimilarity } from "../../lib/map-cosine";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import Redis from "ioredis";
|
||||||
|
|
||||||
|
configDotenv();
|
||||||
|
const redis = new Redis(process.env.REDIS_URL);
|
||||||
|
|
||||||
|
// Max Links that /map can return
|
||||||
|
const MAX_MAP_LIMIT = 5000;
|
||||||
|
// Max Links that "Smart /map" can return
|
||||||
|
const MAX_FIRE_ENGINE_RESULTS = 1000;
|
||||||
|
|
||||||
|
export async function mapController(
|
||||||
|
req: RequestWithAuth<{}, MapResponse, MapRequest>,
|
||||||
|
res: Response<MapResponse>
|
||||||
|
) {
|
||||||
|
const startTime = new Date().getTime();
|
||||||
|
|
||||||
|
req.body = mapRequestSchema.parse(req.body);
|
||||||
|
|
||||||
|
const limit: number = req.body.limit ?? MAX_MAP_LIMIT;
|
||||||
|
|
||||||
|
const id = uuidv4();
|
||||||
|
let links: string[] = [req.body.url];
|
||||||
|
|
||||||
|
const sc: StoredCrawl = {
|
||||||
|
originUrl: req.body.url,
|
||||||
|
crawlerOptions: legacyCrawlerOptions(req.body),
|
||||||
|
pageOptions: {},
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
createdAt: Date.now(),
|
||||||
|
plan: req.auth.plan,
|
||||||
|
};
|
||||||
|
|
||||||
|
const crawler = crawlToCrawler(id, sc);
|
||||||
|
|
||||||
|
let urlWithoutWww = req.body.url.replace("www.", "");
|
||||||
|
|
||||||
|
let mapUrl = req.body.search
|
||||||
|
? `"${req.body.search}" site:${urlWithoutWww}`
|
||||||
|
: `site:${req.body.url}`;
|
||||||
|
|
||||||
|
const resultsPerPage = 100;
|
||||||
|
const maxPages = Math.ceil(Math.min(MAX_FIRE_ENGINE_RESULTS, limit) / resultsPerPage);
|
||||||
|
|
||||||
|
const cacheKey = `fireEngineMap:${mapUrl}`;
|
||||||
|
const cachedResult = null;
|
||||||
|
|
||||||
|
let allResults: any[];
|
||||||
|
let pagePromises: Promise<any>[];
|
||||||
|
|
||||||
|
if (cachedResult) {
|
||||||
|
allResults = JSON.parse(cachedResult);
|
||||||
|
} else {
|
||||||
|
const fetchPage = async (page: number) => {
|
||||||
|
return fireEngineMap(mapUrl, {
|
||||||
|
numResults: resultsPerPage,
|
||||||
|
page: page,
|
||||||
|
});
|
||||||
|
};
|
||||||
|
|
||||||
|
pagePromises = Array.from({ length: maxPages }, (_, i) => fetchPage(i + 1));
|
||||||
|
allResults = await Promise.all(pagePromises);
|
||||||
|
|
||||||
|
await redis.set(cacheKey, JSON.stringify(allResults), "EX", 24 * 60 * 60); // Cache for 24 hours
|
||||||
|
}
|
||||||
|
|
||||||
|
// Parallelize sitemap fetch with serper search
|
||||||
|
const [sitemap, ...searchResults] = await Promise.all([
|
||||||
|
req.body.ignoreSitemap ? null : crawler.tryGetSitemap(),
|
||||||
|
...(cachedResult ? [] : pagePromises),
|
||||||
|
]);
|
||||||
|
|
||||||
|
if (!cachedResult) {
|
||||||
|
allResults = searchResults;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (sitemap !== null) {
|
||||||
|
sitemap.forEach((x) => {
|
||||||
|
links.push(x.url);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
let mapResults = allResults
|
||||||
|
.flat()
|
||||||
|
.filter((result) => result !== null && result !== undefined);
|
||||||
|
|
||||||
|
const minumumCutoff = Math.min(MAX_MAP_LIMIT, limit);
|
||||||
|
if (mapResults.length > minumumCutoff) {
|
||||||
|
mapResults = mapResults.slice(0, minumumCutoff);
|
||||||
|
}
|
||||||
|
|
||||||
|
if (mapResults.length > 0) {
|
||||||
|
if (req.body.search) {
|
||||||
|
// Ensure all map results are first, maintaining their order
|
||||||
|
links = [
|
||||||
|
mapResults[0].url,
|
||||||
|
...mapResults.slice(1).map((x) => x.url),
|
||||||
|
...links,
|
||||||
|
];
|
||||||
|
} else {
|
||||||
|
mapResults.map((x) => {
|
||||||
|
links.push(x.url);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Perform cosine similarity between the search query and the list of links
|
||||||
|
if (req.body.search) {
|
||||||
|
const searchQuery = req.body.search.toLowerCase();
|
||||||
|
|
||||||
|
links = performCosineSimilarity(links, searchQuery);
|
||||||
|
}
|
||||||
|
|
||||||
|
links = links
|
||||||
|
.map((x) => {
|
||||||
|
try {
|
||||||
|
return checkAndUpdateURLForMap(x).url.trim();
|
||||||
|
} catch (_) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
})
|
||||||
|
.filter((x) => x !== null);
|
||||||
|
|
||||||
|
// allows for subdomains to be included
|
||||||
|
links = links.filter((x) => isSameDomain(x, req.body.url));
|
||||||
|
|
||||||
|
// if includeSubdomains is false, filter out subdomains
|
||||||
|
if (!req.body.includeSubdomains) {
|
||||||
|
links = links.filter((x) => isSameSubdomain(x, req.body.url));
|
||||||
|
}
|
||||||
|
|
||||||
|
// remove duplicates that could be due to http/https or www
|
||||||
|
links = removeDuplicateUrls(links);
|
||||||
|
|
||||||
|
billTeam(req.auth.team_id, req.acuc?.sub_id, 1).catch((error) => {
|
||||||
|
Logger.error(
|
||||||
|
`Failed to bill team ${req.auth.team_id} for 1 credit: ${error}`
|
||||||
|
);
|
||||||
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
|
});
|
||||||
|
|
||||||
|
const endTime = new Date().getTime();
|
||||||
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
|
|
||||||
|
const linksToReturn = links.slice(0, limit);
|
||||||
|
|
||||||
|
logJob({
|
||||||
|
job_id: id,
|
||||||
|
success: links.length > 0,
|
||||||
|
message: "Map completed",
|
||||||
|
num_docs: linksToReturn.length,
|
||||||
|
docs: linksToReturn,
|
||||||
|
time_taken: timeTakenInSeconds,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
mode: "map",
|
||||||
|
url: req.body.url,
|
||||||
|
crawlerOptions: {},
|
||||||
|
pageOptions: {},
|
||||||
|
origin: req.body.origin,
|
||||||
|
extractor_options: { mode: "markdown" },
|
||||||
|
num_tokens: 0,
|
||||||
|
});
|
||||||
|
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
links: linksToReturn,
|
||||||
|
scrape_id: req.body.origin?.includes("website") ? id : undefined,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
// Subdomain sitemap url checking
|
||||||
|
|
||||||
|
// // For each result, check for subdomains, get their sitemaps and add them to the links
|
||||||
|
// const processedUrls = new Set();
|
||||||
|
// const processedSubdomains = new Set();
|
||||||
|
|
||||||
|
// for (const result of links) {
|
||||||
|
// let url;
|
||||||
|
// let hostParts;
|
||||||
|
// try {
|
||||||
|
// url = new URL(result);
|
||||||
|
// hostParts = url.hostname.split('.');
|
||||||
|
// } catch (e) {
|
||||||
|
// continue;
|
||||||
|
// }
|
||||||
|
|
||||||
|
// console.log("hostParts", hostParts);
|
||||||
|
// // Check if it's a subdomain (more than 2 parts, and not 'www')
|
||||||
|
// if (hostParts.length > 2 && hostParts[0] !== 'www') {
|
||||||
|
// const subdomain = hostParts[0];
|
||||||
|
// console.log("subdomain", subdomain);
|
||||||
|
// const subdomainUrl = `${url.protocol}//${subdomain}.${hostParts.slice(-2).join('.')}`;
|
||||||
|
// console.log("subdomainUrl", subdomainUrl);
|
||||||
|
|
||||||
|
// if (!processedSubdomains.has(subdomainUrl)) {
|
||||||
|
// processedSubdomains.add(subdomainUrl);
|
||||||
|
|
||||||
|
// const subdomainCrawl = crawlToCrawler(id, {
|
||||||
|
// originUrl: subdomainUrl,
|
||||||
|
// crawlerOptions: legacyCrawlerOptions(req.body),
|
||||||
|
// pageOptions: {},
|
||||||
|
// team_id: req.auth.team_id,
|
||||||
|
// createdAt: Date.now(),
|
||||||
|
// plan: req.auth.plan,
|
||||||
|
// });
|
||||||
|
// const subdomainSitemap = await subdomainCrawl.tryGetSitemap();
|
||||||
|
// if (subdomainSitemap) {
|
||||||
|
// subdomainSitemap.forEach((x) => {
|
||||||
|
// if (!processedUrls.has(x.url)) {
|
||||||
|
// processedUrls.add(x.url);
|
||||||
|
// links.push(x.url);
|
||||||
|
// }
|
||||||
|
// });
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
|
// }
|
||||||
6
apps/api/src/controllers/v1/readiness.ts
Normal file
6
apps/api/src/controllers/v1/readiness.ts
Normal file
|
|
@ -0,0 +1,6 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
|
||||||
|
export async function readinessController(req: Request, res: Response) {
|
||||||
|
// TODO: add checks when the application is ready to serve traffic
|
||||||
|
res.status(200).json({ status: "ok" });
|
||||||
|
}
|
||||||
38
apps/api/src/controllers/v1/scrape-status.ts
Normal file
38
apps/api/src/controllers/v1/scrape-status.ts
Normal file
|
|
@ -0,0 +1,38 @@
|
||||||
|
import { Response } from "express";
|
||||||
|
import { supabaseGetJobByIdOnlyData } from "../../lib/supabase-jobs";
|
||||||
|
import { scrapeStatusRateLimiter } from "../../services/rate-limiter";
|
||||||
|
|
||||||
|
export async function scrapeStatusController(req: any, res: any) {
|
||||||
|
try {
|
||||||
|
const rateLimiter = scrapeStatusRateLimiter;
|
||||||
|
const incomingIP = (req.headers["x-forwarded-for"] ||
|
||||||
|
req.socket.remoteAddress) as string;
|
||||||
|
const iptoken = incomingIP;
|
||||||
|
await rateLimiter.consume(iptoken);
|
||||||
|
|
||||||
|
const job = await supabaseGetJobByIdOnlyData(req.params.jobId);
|
||||||
|
|
||||||
|
if(job.team_id !== "41bdbfe1-0579-4d9b-b6d5-809f16be12f5"){
|
||||||
|
return res.status(403).json({
|
||||||
|
success: false,
|
||||||
|
error: "You are not allowed to access this resource.",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
data: job?.docs[0],
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
if (error instanceof Error && error.message == "Too Many Requests") {
|
||||||
|
return res.status(429).json({
|
||||||
|
success: false,
|
||||||
|
error: "Rate limit exceeded. Please try again later.",
|
||||||
|
});
|
||||||
|
} else {
|
||||||
|
return res.status(500).json({
|
||||||
|
success: false,
|
||||||
|
error: "An unexpected error occurred.",
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
152
apps/api/src/controllers/v1/scrape.ts
Normal file
152
apps/api/src/controllers/v1/scrape.ts
Normal file
|
|
@ -0,0 +1,152 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { Logger } from "../../lib/logger";
|
||||||
|
import {
|
||||||
|
Document,
|
||||||
|
legacyDocumentConverter,
|
||||||
|
legacyExtractorOptions,
|
||||||
|
legacyScrapeOptions,
|
||||||
|
RequestWithAuth,
|
||||||
|
ScrapeRequest,
|
||||||
|
scrapeRequestSchema,
|
||||||
|
ScrapeResponse,
|
||||||
|
} from "./types";
|
||||||
|
import { billTeam } from "../../services/billing/credit_billing";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import { numTokensFromString } from "../../lib/LLM-extraction/helpers";
|
||||||
|
import { addScrapeJob, waitForJob } from "../../services/queue-jobs";
|
||||||
|
import { logJob } from "../../services/logging/log_job";
|
||||||
|
import { getJobPriority } from "../../lib/job-priority";
|
||||||
|
import { PlanType } from "../../types";
|
||||||
|
import { getScrapeQueue } from "../../services/queue-service";
|
||||||
|
|
||||||
|
export async function scrapeController(
|
||||||
|
req: RequestWithAuth<{}, ScrapeResponse, ScrapeRequest>,
|
||||||
|
res: Response<ScrapeResponse>
|
||||||
|
) {
|
||||||
|
req.body = scrapeRequestSchema.parse(req.body);
|
||||||
|
let earlyReturn = false;
|
||||||
|
|
||||||
|
const origin = req.body.origin;
|
||||||
|
const timeout = req.body.timeout;
|
||||||
|
const pageOptions = legacyScrapeOptions(req.body);
|
||||||
|
const extractorOptions = req.body.extract ? legacyExtractorOptions(req.body.extract) : undefined;
|
||||||
|
const jobId = uuidv4();
|
||||||
|
|
||||||
|
const startTime = new Date().getTime();
|
||||||
|
const jobPriority = await getJobPriority({
|
||||||
|
plan: req.auth.plan as PlanType,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
basePriority: 10,
|
||||||
|
});
|
||||||
|
|
||||||
|
await addScrapeJob(
|
||||||
|
{
|
||||||
|
url: req.body.url,
|
||||||
|
mode: "single_urls",
|
||||||
|
crawlerOptions: {},
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
plan: req.auth.plan,
|
||||||
|
pageOptions,
|
||||||
|
extractorOptions,
|
||||||
|
origin: req.body.origin,
|
||||||
|
is_scrape: true,
|
||||||
|
},
|
||||||
|
{},
|
||||||
|
jobId,
|
||||||
|
jobPriority
|
||||||
|
);
|
||||||
|
|
||||||
|
const totalWait = (req.body.waitFor ?? 0) + (req.body.actions ?? []).reduce((a,x) => (x.type === "wait" ? x.milliseconds : 0) + a, 0);
|
||||||
|
|
||||||
|
let doc: any | undefined;
|
||||||
|
try {
|
||||||
|
doc = (await waitForJob(jobId, timeout + totalWait))[0];
|
||||||
|
} catch (e) {
|
||||||
|
Logger.error(`Error in scrapeController: ${e}`);
|
||||||
|
if (e instanceof Error && e.message.startsWith("Job wait")) {
|
||||||
|
return res.status(408).json({
|
||||||
|
success: false,
|
||||||
|
error: "Request timed out",
|
||||||
|
});
|
||||||
|
} else {
|
||||||
|
return res.status(500).json({
|
||||||
|
success: false,
|
||||||
|
error: `(Internal server error) - ${e && e?.message ? e.message : e} ${
|
||||||
|
extractorOptions && extractorOptions.mode !== "markdown"
|
||||||
|
? " - Could be due to LLM parsing issues"
|
||||||
|
: ""
|
||||||
|
}`,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
await getScrapeQueue().remove(jobId);
|
||||||
|
|
||||||
|
if (!doc) {
|
||||||
|
console.error("!!! PANIC DOC IS", doc);
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
warning: "No page found",
|
||||||
|
data: doc,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
delete doc.index;
|
||||||
|
delete doc.provider;
|
||||||
|
|
||||||
|
const endTime = new Date().getTime();
|
||||||
|
const timeTakenInSeconds = (endTime - startTime) / 1000;
|
||||||
|
const numTokens =
|
||||||
|
doc && doc.markdown
|
||||||
|
? numTokensFromString(doc.markdown, "gpt-3.5-turbo")
|
||||||
|
: 0;
|
||||||
|
|
||||||
|
let creditsToBeBilled = 1; // Assuming 1 credit per document
|
||||||
|
if (earlyReturn) {
|
||||||
|
// Don't bill if we're early returning
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
if(req.body.extract && req.body.formats.includes("extract")) {
|
||||||
|
creditsToBeBilled = 5;
|
||||||
|
}
|
||||||
|
|
||||||
|
billTeam(req.auth.team_id, req.acuc?.sub_id, creditsToBeBilled).catch(error => {
|
||||||
|
Logger.error(`Failed to bill team ${req.auth.team_id} for ${creditsToBeBilled} credits: ${error}`);
|
||||||
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
|
});
|
||||||
|
|
||||||
|
if (!pageOptions || !pageOptions.includeRawHtml) {
|
||||||
|
if (doc && doc.rawHtml) {
|
||||||
|
delete doc.rawHtml;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
if(pageOptions && pageOptions.includeExtract) {
|
||||||
|
if(!pageOptions.includeMarkdown && doc && doc.markdown) {
|
||||||
|
delete doc.markdown;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
logJob({
|
||||||
|
job_id: jobId,
|
||||||
|
success: true,
|
||||||
|
message: "Scrape completed",
|
||||||
|
num_docs: 1,
|
||||||
|
docs: [doc],
|
||||||
|
time_taken: timeTakenInSeconds,
|
||||||
|
team_id: req.auth.team_id,
|
||||||
|
mode: "scrape",
|
||||||
|
url: req.body.url,
|
||||||
|
crawlerOptions: {},
|
||||||
|
pageOptions: pageOptions,
|
||||||
|
origin: origin,
|
||||||
|
extractor_options: extractorOptions,
|
||||||
|
num_tokens: numTokens,
|
||||||
|
});
|
||||||
|
|
||||||
|
return res.status(200).json({
|
||||||
|
success: true,
|
||||||
|
data: legacyDocumentConverter(doc),
|
||||||
|
scrape_id: origin?.includes("website") ? jobId : undefined,
|
||||||
|
});
|
||||||
|
}
|
||||||
520
apps/api/src/controllers/v1/types.ts
Normal file
520
apps/api/src/controllers/v1/types.ts
Normal file
|
|
@ -0,0 +1,520 @@
|
||||||
|
import { Request, Response } from "express";
|
||||||
|
import { z } from "zod";
|
||||||
|
import { isUrlBlocked } from "../../scraper/WebScraper/utils/blocklist";
|
||||||
|
import { Action, ExtractorOptions, PageOptions } from "../../lib/entities";
|
||||||
|
import { protocolIncluded, checkUrl } from "../../lib/validateUrl";
|
||||||
|
import { PlanType } from "../../types";
|
||||||
|
import { countries } from "../../lib/validate-country";
|
||||||
|
|
||||||
|
export type Format =
|
||||||
|
| "markdown"
|
||||||
|
| "html"
|
||||||
|
| "rawHtml"
|
||||||
|
| "links"
|
||||||
|
| "screenshot"
|
||||||
|
| "screenshot@fullPage"
|
||||||
|
| "extract";
|
||||||
|
|
||||||
|
export const url = z.preprocess(
|
||||||
|
(x) => {
|
||||||
|
if (!protocolIncluded(x as string)) {
|
||||||
|
return `http://${x}`;
|
||||||
|
}
|
||||||
|
return x;
|
||||||
|
},
|
||||||
|
z
|
||||||
|
.string()
|
||||||
|
.url()
|
||||||
|
.regex(/^https?:\/\//, "URL uses unsupported protocol")
|
||||||
|
.refine(
|
||||||
|
(x) => /\.[a-z]{2,}([\/?#]|$)/i.test(x),
|
||||||
|
"URL must have a valid top-level domain or be a valid path"
|
||||||
|
)
|
||||||
|
.refine(
|
||||||
|
(x) => {
|
||||||
|
try {
|
||||||
|
checkUrl(x as string)
|
||||||
|
return true;
|
||||||
|
} catch (_) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"Invalid URL"
|
||||||
|
)
|
||||||
|
.refine(
|
||||||
|
(x) => !isUrlBlocked(x as string),
|
||||||
|
"Firecrawl currently does not support social media scraping due to policy restrictions. We're actively working on building support for it."
|
||||||
|
)
|
||||||
|
);
|
||||||
|
|
||||||
|
const strictMessage = "Unrecognized key in body -- please review the v1 API documentation for request body changes";
|
||||||
|
|
||||||
|
export const extractOptions = z.object({
|
||||||
|
mode: z.enum(["llm"]).default("llm"),
|
||||||
|
schema: z.any().optional(),
|
||||||
|
systemPrompt: z.string().default("Based on the information on the page, extract all the information from the schema. Try to extract all the fields even those that might not be marked as required."),
|
||||||
|
prompt: z.string().optional()
|
||||||
|
}).strict(strictMessage);
|
||||||
|
|
||||||
|
export type ExtractOptions = z.infer<typeof extractOptions>;
|
||||||
|
|
||||||
|
export const actionsSchema = z.array(z.union([
|
||||||
|
z.object({
|
||||||
|
type: z.literal("wait"),
|
||||||
|
milliseconds: z.number().int().positive().finite().optional(),
|
||||||
|
selector: z.string().optional(),
|
||||||
|
}).refine(
|
||||||
|
(data) => (data.milliseconds !== undefined || data.selector !== undefined) && !(data.milliseconds !== undefined && data.selector !== undefined),
|
||||||
|
{
|
||||||
|
message: "Either 'milliseconds' or 'selector' must be provided, but not both.",
|
||||||
|
}
|
||||||
|
),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("click"),
|
||||||
|
selector: z.string(),
|
||||||
|
}),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("screenshot"),
|
||||||
|
fullPage: z.boolean().default(false),
|
||||||
|
}),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("write"),
|
||||||
|
text: z.string(),
|
||||||
|
}),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("press"),
|
||||||
|
key: z.string(),
|
||||||
|
}),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("scroll"),
|
||||||
|
direction: z.enum(["up", "down"]),
|
||||||
|
}),
|
||||||
|
z.object({
|
||||||
|
type: z.literal("scrape"),
|
||||||
|
}),
|
||||||
|
]));
|
||||||
|
|
||||||
|
export const scrapeOptions = z.object({
|
||||||
|
formats: z
|
||||||
|
.enum([
|
||||||
|
"markdown",
|
||||||
|
"html",
|
||||||
|
"rawHtml",
|
||||||
|
"links",
|
||||||
|
"screenshot",
|
||||||
|
"screenshot@fullPage",
|
||||||
|
"extract"
|
||||||
|
])
|
||||||
|
.array()
|
||||||
|
.optional()
|
||||||
|
.default(["markdown"])
|
||||||
|
.refine(x => !(x.includes("screenshot") && x.includes("screenshot@fullPage")), "You may only specify either screenshot or screenshot@fullPage"),
|
||||||
|
headers: z.record(z.string(), z.string()).optional(),
|
||||||
|
includeTags: z.string().array().optional(),
|
||||||
|
excludeTags: z.string().array().optional(),
|
||||||
|
onlyMainContent: z.boolean().default(true),
|
||||||
|
timeout: z.number().int().positive().finite().safe().default(30000),
|
||||||
|
waitFor: z.number().int().nonnegative().finite().safe().default(0),
|
||||||
|
extract: extractOptions.optional(),
|
||||||
|
mobile: z.boolean().default(false),
|
||||||
|
parsePDF: z.boolean().default(true),
|
||||||
|
actions: actionsSchema.optional(),
|
||||||
|
// New
|
||||||
|
location: z.object({
|
||||||
|
country: z.string().optional().refine(
|
||||||
|
(val) => !val || Object.keys(countries).includes(val.toUpperCase()),
|
||||||
|
{
|
||||||
|
message: "Invalid country code. Please use a valid ISO 3166-1 alpha-2 country code.",
|
||||||
|
}
|
||||||
|
).transform(val => val ? val.toUpperCase() : 'US'),
|
||||||
|
languages: z.string().array().optional(),
|
||||||
|
}).optional(),
|
||||||
|
|
||||||
|
// Deprecated
|
||||||
|
geolocation: z.object({
|
||||||
|
country: z.string().optional().refine(
|
||||||
|
(val) => !val || Object.keys(countries).includes(val.toUpperCase()),
|
||||||
|
{
|
||||||
|
message: "Invalid country code. Please use a valid ISO 3166-1 alpha-2 country code.",
|
||||||
|
}
|
||||||
|
).transform(val => val ? val.toUpperCase() : 'US'),
|
||||||
|
languages: z.string().array().optional(),
|
||||||
|
}).optional(),
|
||||||
|
skipTlsVerification: z.boolean().default(false),
|
||||||
|
removeBase64Images: z.boolean().default(true),
|
||||||
|
}).strict(strictMessage)
|
||||||
|
|
||||||
|
|
||||||
|
export type ScrapeOptions = z.infer<typeof scrapeOptions>;
|
||||||
|
|
||||||
|
export const scrapeRequestSchema = scrapeOptions.extend({
|
||||||
|
url,
|
||||||
|
origin: z.string().optional().default("api"),
|
||||||
|
}).strict(strictMessage).refine(
|
||||||
|
(obj) => {
|
||||||
|
const hasExtractFormat = obj.formats?.includes("extract");
|
||||||
|
const hasExtractOptions = obj.extract !== undefined;
|
||||||
|
return (hasExtractFormat && hasExtractOptions) || (!hasExtractFormat && !hasExtractOptions);
|
||||||
|
},
|
||||||
|
{
|
||||||
|
message: "When 'extract' format is specified, 'extract' options must be provided, and vice versa",
|
||||||
|
}
|
||||||
|
).transform((obj) => {
|
||||||
|
if ((obj.formats?.includes("extract") || obj.extract) && !obj.timeout) {
|
||||||
|
return { ...obj, timeout: 60000 };
|
||||||
|
}
|
||||||
|
return obj;
|
||||||
|
});
|
||||||
|
|
||||||
|
export type ScrapeRequest = z.infer<typeof scrapeRequestSchema>;
|
||||||
|
|
||||||
|
export const batchScrapeRequestSchema = scrapeOptions.extend({
|
||||||
|
urls: url.array(),
|
||||||
|
origin: z.string().optional().default("api"),
|
||||||
|
}).strict(strictMessage).refine(
|
||||||
|
(obj) => {
|
||||||
|
const hasExtractFormat = obj.formats?.includes("extract");
|
||||||
|
const hasExtractOptions = obj.extract !== undefined;
|
||||||
|
return (hasExtractFormat && hasExtractOptions) || (!hasExtractFormat && !hasExtractOptions);
|
||||||
|
},
|
||||||
|
{
|
||||||
|
message: "When 'extract' format is specified, 'extract' options must be provided, and vice versa",
|
||||||
|
}
|
||||||
|
).transform((obj) => {
|
||||||
|
if ((obj.formats?.includes("extract") || obj.extract) && !obj.timeout) {
|
||||||
|
return { ...obj, timeout: 60000 };
|
||||||
|
}
|
||||||
|
return obj;
|
||||||
|
});
|
||||||
|
|
||||||
|
export type BatchScrapeRequest = z.infer<typeof batchScrapeRequestSchema>;
|
||||||
|
|
||||||
|
const crawlerOptions = z.object({
|
||||||
|
includePaths: z.string().array().default([]),
|
||||||
|
excludePaths: z.string().array().default([]),
|
||||||
|
maxDepth: z.number().default(10), // default?
|
||||||
|
limit: z.number().default(10000), // default?
|
||||||
|
allowBackwardLinks: z.boolean().default(false), // >> TODO: CHANGE THIS NAME???
|
||||||
|
allowExternalLinks: z.boolean().default(false),
|
||||||
|
ignoreSitemap: z.boolean().default(true),
|
||||||
|
}).strict(strictMessage);
|
||||||
|
|
||||||
|
// export type CrawlerOptions = {
|
||||||
|
// includePaths?: string[];
|
||||||
|
// excludePaths?: string[];
|
||||||
|
// maxDepth?: number;
|
||||||
|
// limit?: number;
|
||||||
|
// allowBackwardLinks?: boolean; // >> TODO: CHANGE THIS NAME???
|
||||||
|
// allowExternalLinks?: boolean;
|
||||||
|
// ignoreSitemap?: boolean;
|
||||||
|
// };
|
||||||
|
|
||||||
|
export type CrawlerOptions = z.infer<typeof crawlerOptions>;
|
||||||
|
|
||||||
|
export const crawlRequestSchema = crawlerOptions.extend({
|
||||||
|
url,
|
||||||
|
origin: z.string().optional().default("api"),
|
||||||
|
scrapeOptions: scrapeOptions.omit({ timeout: true }).default({}),
|
||||||
|
webhook: z.string().url().optional(),
|
||||||
|
limit: z.number().default(10000),
|
||||||
|
}).strict(strictMessage);
|
||||||
|
|
||||||
|
// export type CrawlRequest = {
|
||||||
|
// url: string;
|
||||||
|
// crawlerOptions?: CrawlerOptions;
|
||||||
|
// scrapeOptions?: Exclude<ScrapeRequest, "url">;
|
||||||
|
// };
|
||||||
|
|
||||||
|
// export type ExtractorOptions = {
|
||||||
|
// mode: "markdown" | "llm-extraction" | "llm-extraction-from-markdown" | "llm-extraction-from-raw-html";
|
||||||
|
// extractionPrompt?: string;
|
||||||
|
// extractionSchema?: Record<string, any>;
|
||||||
|
// }
|
||||||
|
|
||||||
|
|
||||||
|
export type CrawlRequest = z.infer<typeof crawlRequestSchema>;
|
||||||
|
|
||||||
|
export const mapRequestSchema = crawlerOptions.extend({
|
||||||
|
url,
|
||||||
|
origin: z.string().optional().default("api"),
|
||||||
|
includeSubdomains: z.boolean().default(true),
|
||||||
|
search: z.string().optional(),
|
||||||
|
ignoreSitemap: z.boolean().default(false),
|
||||||
|
limit: z.number().min(1).max(5000).default(5000).optional(),
|
||||||
|
}).strict(strictMessage);
|
||||||
|
|
||||||
|
// export type MapRequest = {
|
||||||
|
// url: string;
|
||||||
|
// crawlerOptions?: CrawlerOptions;
|
||||||
|
// };
|
||||||
|
|
||||||
|
export type MapRequest = z.infer<typeof mapRequestSchema>;
|
||||||
|
|
||||||
|
export type Document = {
|
||||||
|
markdown?: string;
|
||||||
|
extract?: string;
|
||||||
|
html?: string;
|
||||||
|
rawHtml?: string;
|
||||||
|
links?: string[];
|
||||||
|
screenshot?: string;
|
||||||
|
actions?: {
|
||||||
|
screenshots: string[];
|
||||||
|
};
|
||||||
|
warning?: string;
|
||||||
|
metadata: {
|
||||||
|
title?: string;
|
||||||
|
description?: string;
|
||||||
|
language?: string;
|
||||||
|
keywords?: string;
|
||||||
|
robots?: string;
|
||||||
|
ogTitle?: string;
|
||||||
|
ogDescription?: string;
|
||||||
|
ogUrl?: string;
|
||||||
|
ogImage?: string;
|
||||||
|
ogAudio?: string;
|
||||||
|
ogDeterminer?: string;
|
||||||
|
ogLocale?: string;
|
||||||
|
ogLocaleAlternate?: string[];
|
||||||
|
ogSiteName?: string;
|
||||||
|
ogVideo?: string;
|
||||||
|
dcTermsCreated?: string;
|
||||||
|
dcDateCreated?: string;
|
||||||
|
dcDate?: string;
|
||||||
|
dcTermsType?: string;
|
||||||
|
dcType?: string;
|
||||||
|
dcTermsAudience?: string;
|
||||||
|
dcTermsSubject?: string;
|
||||||
|
dcSubject?: string;
|
||||||
|
dcDescription?: string;
|
||||||
|
dcTermsKeywords?: string;
|
||||||
|
modifiedTime?: string;
|
||||||
|
publishedTime?: string;
|
||||||
|
articleTag?: string;
|
||||||
|
articleSection?: string;
|
||||||
|
sourceURL?: string;
|
||||||
|
statusCode?: number;
|
||||||
|
error?: string;
|
||||||
|
[key: string]: string | string[] | number | undefined;
|
||||||
|
|
||||||
|
};
|
||||||
|
};
|
||||||
|
|
||||||
|
export type ErrorResponse = {
|
||||||
|
success: false;
|
||||||
|
error: string;
|
||||||
|
details?: any;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type ScrapeResponse =
|
||||||
|
| ErrorResponse
|
||||||
|
| {
|
||||||
|
success: true;
|
||||||
|
warning?: string;
|
||||||
|
data: Document;
|
||||||
|
scrape_id?: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export interface ScrapeResponseRequestTest {
|
||||||
|
statusCode: number;
|
||||||
|
body: ScrapeResponse;
|
||||||
|
error?: string;
|
||||||
|
}
|
||||||
|
|
||||||
|
export type CrawlResponse =
|
||||||
|
| ErrorResponse
|
||||||
|
| {
|
||||||
|
success: true;
|
||||||
|
id: string;
|
||||||
|
url: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type MapResponse =
|
||||||
|
| ErrorResponse
|
||||||
|
| {
|
||||||
|
success: true;
|
||||||
|
links: string[];
|
||||||
|
scrape_id?: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type CrawlStatusParams = {
|
||||||
|
jobId: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type ConcurrencyCheckParams = {
|
||||||
|
teamId: string;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type ConcurrencyCheckResponse =
|
||||||
|
| ErrorResponse
|
||||||
|
| {
|
||||||
|
success: true;
|
||||||
|
concurrency: number;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type CrawlStatusResponse =
|
||||||
|
| ErrorResponse
|
||||||
|
| {
|
||||||
|
success: true;
|
||||||
|
status: "scraping" | "completed" | "failed" | "cancelled";
|
||||||
|
completed: number;
|
||||||
|
total: number;
|
||||||
|
creditsUsed: number;
|
||||||
|
expiresAt: string;
|
||||||
|
next?: string;
|
||||||
|
data: Document[];
|
||||||
|
};
|
||||||
|
|
||||||
|
type AuthObject = {
|
||||||
|
team_id: string;
|
||||||
|
plan: PlanType;
|
||||||
|
};
|
||||||
|
|
||||||
|
type Account = {
|
||||||
|
remainingCredits: number;
|
||||||
|
};
|
||||||
|
|
||||||
|
export type AuthCreditUsageChunk = {
|
||||||
|
api_key: string;
|
||||||
|
team_id: string;
|
||||||
|
sub_id: string | null;
|
||||||
|
sub_current_period_start: string | null;
|
||||||
|
sub_current_period_end: string | null;
|
||||||
|
price_id: string | null;
|
||||||
|
price_credits: number; // credit limit with assoicated price, or free_credits (500) if free plan
|
||||||
|
credits_used: number;
|
||||||
|
coupon_credits: number; // do not rely on this number to be up to date after calling a billTeam
|
||||||
|
coupons: any[];
|
||||||
|
adjusted_credits_used: number; // credits this period minus coupons used
|
||||||
|
remaining_credits: number;
|
||||||
|
sub_user_id: string | null;
|
||||||
|
total_credits_sum: number;
|
||||||
|
};
|
||||||
|
|
||||||
|
export interface RequestWithMaybeACUC<
|
||||||
|
ReqParams = {},
|
||||||
|
ReqBody = undefined,
|
||||||
|
ResBody = undefined
|
||||||
|
> extends Request<ReqParams, ReqBody, ResBody> {
|
||||||
|
acuc?: AuthCreditUsageChunk,
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface RequestWithACUC<
|
||||||
|
ReqParams = {},
|
||||||
|
ReqBody = undefined,
|
||||||
|
ResBody = undefined
|
||||||
|
> extends Request<ReqParams, ReqBody, ResBody> {
|
||||||
|
acuc: AuthCreditUsageChunk,
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface RequestWithAuth<
|
||||||
|
ReqParams = {},
|
||||||
|
ReqBody = undefined,
|
||||||
|
ResBody = undefined,
|
||||||
|
> extends Request<ReqParams, ReqBody, ResBody> {
|
||||||
|
auth: AuthObject;
|
||||||
|
account?: Account;
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface RequestWithMaybeAuth<
|
||||||
|
ReqParams = {},
|
||||||
|
ReqBody = undefined,
|
||||||
|
ResBody = undefined
|
||||||
|
> extends RequestWithMaybeACUC<ReqParams, ReqBody, ResBody> {
|
||||||
|
auth?: AuthObject;
|
||||||
|
account?: Account;
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface RequestWithAuth<
|
||||||
|
ReqParams = {},
|
||||||
|
ReqBody = undefined,
|
||||||
|
ResBody = undefined,
|
||||||
|
> extends RequestWithACUC<ReqParams, ReqBody, ResBody> {
|
||||||
|
auth: AuthObject;
|
||||||
|
account?: Account;
|
||||||
|
}
|
||||||
|
|
||||||
|
export interface ResponseWithSentry<
|
||||||
|
ResBody = undefined,
|
||||||
|
> extends Response<ResBody> {
|
||||||
|
sentry?: string,
|
||||||
|
}
|
||||||
|
|
||||||
|
export function legacyCrawlerOptions(x: CrawlerOptions) {
|
||||||
|
return {
|
||||||
|
includes: x.includePaths,
|
||||||
|
excludes: x.excludePaths,
|
||||||
|
maxCrawledLinks: x.limit,
|
||||||
|
maxDepth: x.maxDepth,
|
||||||
|
limit: x.limit,
|
||||||
|
generateImgAltText: false,
|
||||||
|
allowBackwardCrawling: x.allowBackwardLinks,
|
||||||
|
allowExternalContentLinks: x.allowExternalLinks,
|
||||||
|
ignoreSitemap: x.ignoreSitemap,
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
export function legacyScrapeOptions(x: ScrapeOptions): PageOptions {
|
||||||
|
return {
|
||||||
|
includeMarkdown: x.formats.includes("markdown"),
|
||||||
|
includeHtml: x.formats.includes("html"),
|
||||||
|
includeRawHtml: x.formats.includes("rawHtml"),
|
||||||
|
includeExtract: x.formats.includes("extract"),
|
||||||
|
onlyIncludeTags: x.includeTags,
|
||||||
|
removeTags: x.excludeTags,
|
||||||
|
onlyMainContent: x.onlyMainContent,
|
||||||
|
waitFor: x.waitFor,
|
||||||
|
headers: x.headers,
|
||||||
|
includeLinks: x.formats.includes("links"),
|
||||||
|
screenshot: x.formats.includes("screenshot"),
|
||||||
|
fullPageScreenshot: x.formats.includes("screenshot@fullPage"),
|
||||||
|
parsePDF: x.parsePDF,
|
||||||
|
actions: x.actions as Action[], // no strict null checking grrrr - mogery
|
||||||
|
geolocation: x.location ?? x.geolocation,
|
||||||
|
skipTlsVerification: x.skipTlsVerification,
|
||||||
|
removeBase64Images: x.removeBase64Images,
|
||||||
|
mobile: x.mobile,
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
export function legacyExtractorOptions(x: ExtractOptions): ExtractorOptions {
|
||||||
|
return {
|
||||||
|
mode: x.mode ? "llm-extraction" : "markdown",
|
||||||
|
extractionPrompt: x.prompt ?? "Based on the information on the page, extract the information from the schema.",
|
||||||
|
extractionSchema: x.schema,
|
||||||
|
userPrompt: x.prompt ?? "",
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
||||||
|
export function legacyDocumentConverter(doc: any): Document {
|
||||||
|
if (doc === null || doc === undefined) return null;
|
||||||
|
|
||||||
|
if (doc.metadata) {
|
||||||
|
if (doc.metadata.screenshot) {
|
||||||
|
doc.screenshot = doc.metadata.screenshot;
|
||||||
|
delete doc.metadata.screenshot;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (doc.metadata.fullPageScreenshot) {
|
||||||
|
doc.fullPageScreenshot = doc.metadata.fullPageScreenshot;
|
||||||
|
delete doc.metadata.fullPageScreenshot;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return {
|
||||||
|
markdown: doc.markdown,
|
||||||
|
links: doc.linksOnPage,
|
||||||
|
rawHtml: doc.rawHtml,
|
||||||
|
html: doc.html,
|
||||||
|
extract: doc.llm_extraction,
|
||||||
|
screenshot: doc.screenshot ?? doc.fullPageScreenshot,
|
||||||
|
actions: doc.actions ?? undefined,
|
||||||
|
warning: doc.warning ?? undefined,
|
||||||
|
metadata: {
|
||||||
|
...doc.metadata,
|
||||||
|
pageError: undefined,
|
||||||
|
pageStatusCode: undefined,
|
||||||
|
error: doc.metadata?.pageError,
|
||||||
|
statusCode: doc.metadata?.pageStatusCode,
|
||||||
|
},
|
||||||
|
};
|
||||||
|
}
|
||||||
|
|
@ -4,6 +4,7 @@ async function example() {
|
||||||
const example = new WebScraperDataProvider();
|
const example = new WebScraperDataProvider();
|
||||||
|
|
||||||
await example.setOptions({
|
await example.setOptions({
|
||||||
|
jobId: "TEST",
|
||||||
mode: "crawl",
|
mode: "crawl",
|
||||||
urls: ["https://mendable.ai"],
|
urls: ["https://mendable.ai"],
|
||||||
crawlerOptions: {},
|
crawlerOptions: {},
|
||||||
|
|
|
||||||
|
|
@ -1,122 +1,107 @@
|
||||||
import express from "express";
|
import "dotenv/config";
|
||||||
|
import "./services/sentry"
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import express, { NextFunction, Request, Response } from "express";
|
||||||
import bodyParser from "body-parser";
|
import bodyParser from "body-parser";
|
||||||
import cors from "cors";
|
import cors from "cors";
|
||||||
import "dotenv/config";
|
import { getScrapeQueue } from "./services/queue-service";
|
||||||
import { getWebScraperQueue } from "./services/queue-service";
|
|
||||||
import { redisClient } from "./services/rate-limiter";
|
|
||||||
import { v0Router } from "./routes/v0";
|
import { v0Router } from "./routes/v0";
|
||||||
import { initSDK } from "@hyperdx/node-opentelemetry";
|
import { initSDK } from "@hyperdx/node-opentelemetry";
|
||||||
import cluster from "cluster";
|
|
||||||
import os from "os";
|
import os from "os";
|
||||||
|
import { Logger } from "./lib/logger";
|
||||||
|
import { adminRouter } from "./routes/admin";
|
||||||
|
import { ScrapeEvents } from "./lib/scrape-events";
|
||||||
|
import http from 'node:http';
|
||||||
|
import https from 'node:https';
|
||||||
|
import CacheableLookup from 'cacheable-lookup';
|
||||||
|
import { v1Router } from "./routes/v1";
|
||||||
|
import expressWs from "express-ws";
|
||||||
|
import { crawlStatusWSController } from "./controllers/v1/crawl-status-ws";
|
||||||
|
import { ErrorResponse, ResponseWithSentry } from "./controllers/v1/types";
|
||||||
|
import { ZodError } from "zod";
|
||||||
|
import { v4 as uuidv4 } from "uuid";
|
||||||
|
import dns from 'node:dns';
|
||||||
|
|
||||||
const { createBullBoard } = require("@bull-board/api");
|
const { createBullBoard } = require("@bull-board/api");
|
||||||
const { BullAdapter } = require("@bull-board/api/bullAdapter");
|
const { BullAdapter } = require("@bull-board/api/bullAdapter");
|
||||||
const { ExpressAdapter } = require("@bull-board/express");
|
const { ExpressAdapter } = require("@bull-board/express");
|
||||||
|
|
||||||
const numCPUs = process.env.ENV === "local" ? 2 : os.cpus().length;
|
const numCPUs = process.env.ENV === "local" ? 2 : os.cpus().length;
|
||||||
console.log(`Number of CPUs: ${numCPUs} available`);
|
Logger.info(`Number of CPUs: ${numCPUs} available`);
|
||||||
|
|
||||||
if (cluster.isMaster) {
|
const cacheable = new CacheableLookup()
|
||||||
console.log(`Master ${process.pid} is running`);
|
|
||||||
|
|
||||||
// Fork workers.
|
|
||||||
for (let i = 0; i < numCPUs; i++) {
|
|
||||||
cluster.fork();
|
|
||||||
}
|
|
||||||
|
|
||||||
cluster.on("exit", (worker, code, signal) => {
|
// Install cacheable lookup for all other requests
|
||||||
console.log(`Worker ${worker.process.pid} exited`);
|
cacheable.install(http.globalAgent);
|
||||||
console.log("Starting a new worker");
|
cacheable.install(https.globalAgent);
|
||||||
cluster.fork();
|
|
||||||
});
|
|
||||||
} else {
|
|
||||||
const app = express();
|
|
||||||
|
|
||||||
global.isProduction = process.env.IS_PRODUCTION === "true";
|
|
||||||
|
|
||||||
app.use(bodyParser.urlencoded({ extended: true }));
|
const ws = expressWs(express());
|
||||||
app.use(bodyParser.json({ limit: "10mb" }));
|
const app = ws.app;
|
||||||
|
|
||||||
app.use(cors()); // Add this line to enable CORS
|
global.isProduction = process.env.IS_PRODUCTION === "true";
|
||||||
|
|
||||||
const serverAdapter = new ExpressAdapter();
|
app.use(bodyParser.urlencoded({ extended: true }));
|
||||||
serverAdapter.setBasePath(`/admin/${process.env.BULL_AUTH_KEY}/queues`);
|
app.use(bodyParser.json({ limit: "10mb" }));
|
||||||
|
|
||||||
const { addQueue, removeQueue, setQueues, replaceQueues } = createBullBoard({
|
app.use(cors()); // Add this line to enable CORS
|
||||||
queues: [new BullAdapter(getWebScraperQueue())],
|
|
||||||
|
const serverAdapter = new ExpressAdapter();
|
||||||
|
serverAdapter.setBasePath(`/admin/${process.env.BULL_AUTH_KEY}/queues`);
|
||||||
|
|
||||||
|
const { addQueue, removeQueue, setQueues, replaceQueues } = createBullBoard({
|
||||||
|
queues: [new BullAdapter(getScrapeQueue())],
|
||||||
serverAdapter: serverAdapter,
|
serverAdapter: serverAdapter,
|
||||||
});
|
});
|
||||||
|
|
||||||
app.use(
|
|
||||||
|
app.use(
|
||||||
`/admin/${process.env.BULL_AUTH_KEY}/queues`,
|
`/admin/${process.env.BULL_AUTH_KEY}/queues`,
|
||||||
serverAdapter.getRouter()
|
serverAdapter.getRouter()
|
||||||
);
|
);
|
||||||
|
|
||||||
app.get("/", (req, res) => {
|
app.get("/", (req, res) => {
|
||||||
res.send("SCRAPERS-JS: Hello, world! Fly.io");
|
res.send("SCRAPERS-JS: Hello, world! K8s!");
|
||||||
});
|
});
|
||||||
|
|
||||||
//write a simple test function
|
//write a simple test function
|
||||||
app.get("/test", async (req, res) => {
|
app.get("/test", async (req, res) => {
|
||||||
res.send("Hello, world!");
|
res.send("Hello, world!");
|
||||||
});
|
});
|
||||||
|
|
||||||
// register router
|
// register router
|
||||||
app.use(v0Router);
|
app.use(v0Router);
|
||||||
|
app.use("/v1", v1Router);
|
||||||
|
app.use(adminRouter);
|
||||||
|
|
||||||
const DEFAULT_PORT = process.env.PORT ?? 3002;
|
const DEFAULT_PORT = process.env.PORT ?? 3002;
|
||||||
const HOST = process.env.HOST ?? "localhost";
|
const HOST = process.env.HOST ?? "localhost";
|
||||||
redisClient.connect();
|
|
||||||
|
|
||||||
// HyperDX OpenTelemetry
|
// HyperDX OpenTelemetry
|
||||||
if (process.env.ENV === "production") {
|
if (process.env.ENV === "production") {
|
||||||
initSDK({ consoleCapture: true, additionalInstrumentations: [] });
|
initSDK({ consoleCapture: true, additionalInstrumentations: [] });
|
||||||
}
|
}
|
||||||
|
|
||||||
function startServer(port = DEFAULT_PORT) {
|
function startServer(port = DEFAULT_PORT) {
|
||||||
const server = app.listen(Number(port), HOST, () => {
|
const server = app.listen(Number(port), HOST, () => {
|
||||||
console.log(`Worker ${process.pid} listening on port ${port}`);
|
Logger.info(`Worker ${process.pid} listening on port ${port}`);
|
||||||
console.log(
|
Logger.info(
|
||||||
`For the UI, open http://${HOST}:${port}/admin/${process.env.BULL_AUTH_KEY}/queues`
|
`For the Queue UI, open: http://${HOST}:${port}/admin/${process.env.BULL_AUTH_KEY}/queues`
|
||||||
);
|
|
||||||
console.log("");
|
|
||||||
console.log("1. Make sure Redis is running on port 6379 by default");
|
|
||||||
console.log(
|
|
||||||
"2. If you want to run nango, make sure you do port forwarding in 3002 using ngrok http 3002 "
|
|
||||||
);
|
);
|
||||||
});
|
});
|
||||||
return server;
|
return server;
|
||||||
}
|
}
|
||||||
|
|
||||||
if (require.main === module) {
|
if (require.main === module) {
|
||||||
startServer();
|
startServer();
|
||||||
}
|
}
|
||||||
|
|
||||||
// Use this as a "health check" that way we dont destroy the server
|
app.get(`/serverHealthCheck`, async (req, res) => {
|
||||||
app.get(`/admin/${process.env.BULL_AUTH_KEY}/queues`, async (req, res) => {
|
|
||||||
try {
|
try {
|
||||||
const webScraperQueue = getWebScraperQueue();
|
const scrapeQueue = getScrapeQueue();
|
||||||
const [webScraperActive] = await Promise.all([
|
|
||||||
webScraperQueue.getActiveCount(),
|
|
||||||
]);
|
|
||||||
|
|
||||||
const noActiveJobs = webScraperActive === 0;
|
|
||||||
// 200 if no active jobs, 503 if there are active jobs
|
|
||||||
return res.status(noActiveJobs ? 200 : 500).json({
|
|
||||||
webScraperActive,
|
|
||||||
noActiveJobs,
|
|
||||||
});
|
|
||||||
} catch (error) {
|
|
||||||
console.error(error);
|
|
||||||
return res.status(500).json({ error: error.message });
|
|
||||||
}
|
|
||||||
});
|
|
||||||
|
|
||||||
app.get(`/serverHealthCheck`, async (req, res) => {
|
|
||||||
try {
|
|
||||||
const webScraperQueue = getWebScraperQueue();
|
|
||||||
const [waitingJobs] = await Promise.all([
|
const [waitingJobs] = await Promise.all([
|
||||||
webScraperQueue.getWaitingCount(),
|
scrapeQueue.getWaitingCount(),
|
||||||
]);
|
]);
|
||||||
|
|
||||||
const noWaitingJobs = waitingJobs === 0;
|
const noWaitingJobs = waitingJobs === 0;
|
||||||
|
|
@ -125,20 +110,21 @@ if (cluster.isMaster) {
|
||||||
waitingJobs,
|
waitingJobs,
|
||||||
});
|
});
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(error);
|
Sentry.captureException(error);
|
||||||
|
Logger.error(error);
|
||||||
return res.status(500).json({ error: error.message });
|
return res.status(500).json({ error: error.message });
|
||||||
}
|
}
|
||||||
});
|
});
|
||||||
|
|
||||||
app.get("/serverHealthCheck/notify", async (req, res) => {
|
app.get("/serverHealthCheck/notify", async (req, res) => {
|
||||||
if (process.env.SLACK_WEBHOOK_URL) {
|
if (process.env.SLACK_WEBHOOK_URL) {
|
||||||
const treshold = 1; // The treshold value for the active jobs
|
const treshold = 1; // The treshold value for the active jobs
|
||||||
const timeout = 60000; // 1 minute // The timeout value for the check in milliseconds
|
const timeout = 60000; // 1 minute // The timeout value for the check in milliseconds
|
||||||
|
|
||||||
const getWaitingJobsCount = async () => {
|
const getWaitingJobsCount = async () => {
|
||||||
const webScraperQueue = getWebScraperQueue();
|
const scrapeQueue = getScrapeQueue();
|
||||||
const [waitingJobsCount] = await Promise.all([
|
const [waitingJobsCount] = await Promise.all([
|
||||||
webScraperQueue.getWaitingCount(),
|
scrapeQueue.getWaitingCount(),
|
||||||
]);
|
]);
|
||||||
|
|
||||||
return waitingJobsCount;
|
return waitingJobsCount;
|
||||||
|
|
@ -170,50 +156,70 @@ if (cluster.isMaster) {
|
||||||
});
|
});
|
||||||
|
|
||||||
if (!response.ok) {
|
if (!response.ok) {
|
||||||
console.error("Failed to send Slack notification");
|
Logger.error("Failed to send Slack notification");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}, timeout);
|
}, timeout);
|
||||||
}
|
}
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(error);
|
Sentry.captureException(error);
|
||||||
|
Logger.debug(error);
|
||||||
}
|
}
|
||||||
};
|
};
|
||||||
|
|
||||||
checkWaitingJobs();
|
checkWaitingJobs();
|
||||||
}
|
}
|
||||||
});
|
});
|
||||||
|
|
||||||
app.get(
|
app.get("/is-production", (req, res) => {
|
||||||
`/admin/${process.env.BULL_AUTH_KEY}/clean-before-24h-complete-jobs`,
|
|
||||||
async (req, res) => {
|
|
||||||
try {
|
|
||||||
const webScraperQueue = getWebScraperQueue();
|
|
||||||
const completedJobs = await webScraperQueue.getJobs(["completed"]);
|
|
||||||
const before24hJobs = completedJobs.filter(
|
|
||||||
(job) => job.finishedOn < Date.now() - 24 * 60 * 60 * 1000
|
|
||||||
);
|
|
||||||
const jobIds = before24hJobs.map((job) => job.id) as string[];
|
|
||||||
let count = 0;
|
|
||||||
for (const jobId of jobIds) {
|
|
||||||
try {
|
|
||||||
await webScraperQueue.removeJobs(jobId);
|
|
||||||
count++;
|
|
||||||
} catch (jobError) {
|
|
||||||
console.error(`Failed to remove job with ID ${jobId}:`, jobError);
|
|
||||||
}
|
|
||||||
}
|
|
||||||
res.status(200).send(`Removed ${count} completed jobs.`);
|
|
||||||
} catch (error) {
|
|
||||||
console.error("Failed to clean last 24h complete jobs:", error);
|
|
||||||
res.status(500).send("Failed to clean jobs");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
);
|
|
||||||
|
|
||||||
app.get("/is-production", (req, res) => {
|
|
||||||
res.send({ isProduction: global.isProduction });
|
res.send({ isProduction: global.isProduction });
|
||||||
});
|
});
|
||||||
|
|
||||||
|
app.use((err: unknown, req: Request<{}, ErrorResponse, undefined>, res: Response<ErrorResponse>, next: NextFunction) => {
|
||||||
|
if (err instanceof ZodError) {
|
||||||
|
if (Array.isArray(err.errors) && err.errors.find(x => x.message === "URL uses unsupported protocol")) {
|
||||||
|
Logger.warn("Unsupported protocol error: " + JSON.stringify(req.body));
|
||||||
|
}
|
||||||
|
|
||||||
|
res.status(400).json({ success: false, error: "Bad Request", details: err.errors });
|
||||||
|
} else {
|
||||||
|
next(err);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
Sentry.setupExpressErrorHandler(app);
|
||||||
|
|
||||||
|
app.use((err: unknown, req: Request<{}, ErrorResponse, undefined>, res: ResponseWithSentry<ErrorResponse>, next: NextFunction) => {
|
||||||
|
if (err instanceof SyntaxError && 'status' in err && err.status === 400 && 'body' in err) {
|
||||||
|
return res.status(400).json({ success: false, error: 'Bad request, malformed JSON' });
|
||||||
|
}
|
||||||
|
|
||||||
|
const id = res.sentry ?? uuidv4();
|
||||||
|
let verbose = JSON.stringify(err);
|
||||||
|
if (verbose === "{}") {
|
||||||
|
if (err instanceof Error) {
|
||||||
|
verbose = JSON.stringify({
|
||||||
|
message: err.message,
|
||||||
|
name: err.name,
|
||||||
|
stack: err.stack,
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
Logger.error("Error occurred in request! (" + req.path + ") -- ID " + id + " -- " + verbose);
|
||||||
|
res.status(500).json({ success: false, error: "An unexpected error occurred. Please contact hello@firecrawl.com for help. Your exception ID is " + id });
|
||||||
|
});
|
||||||
|
|
||||||
|
Logger.info(`Worker ${process.pid} started`);
|
||||||
|
|
||||||
|
// const sq = getScrapeQueue();
|
||||||
|
|
||||||
|
// sq.on("waiting", j => ScrapeEvents.logJobEvent(j, "waiting"));
|
||||||
|
// sq.on("active", j => ScrapeEvents.logJobEvent(j, "active"));
|
||||||
|
// sq.on("completed", j => ScrapeEvents.logJobEvent(j, "completed"));
|
||||||
|
// sq.on("paused", j => ScrapeEvents.logJobEvent(j, "paused"));
|
||||||
|
// sq.on("resumed", j => ScrapeEvents.logJobEvent(j, "resumed"));
|
||||||
|
// sq.on("removed", j => ScrapeEvents.logJobEvent(j, "removed"));
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
console.log(`Worker ${process.pid} started`);
|
|
||||||
}
|
|
||||||
|
|
|
||||||
|
|
@ -6,7 +6,13 @@ export function numTokensFromString(message: string, model: string): number {
|
||||||
const encoder = encoding_for_model(model as TiktokenModel);
|
const encoder = encoding_for_model(model as TiktokenModel);
|
||||||
|
|
||||||
// Encode the message into tokens
|
// Encode the message into tokens
|
||||||
const tokens = encoder.encode(message);
|
let tokens: Uint32Array;
|
||||||
|
try {
|
||||||
|
tokens = encoder.encode(message);
|
||||||
|
} catch (error) {
|
||||||
|
message = message.replace("<|endoftext|>", "");
|
||||||
|
tokens = encoder.encode(message);
|
||||||
|
}
|
||||||
|
|
||||||
// Free the encoder resources after use
|
// Free the encoder resources after use
|
||||||
encoder.free();
|
encoder.free();
|
||||||
|
|
|
||||||
|
|
@ -4,16 +4,19 @@ const ajv = new Ajv(); // Initialize AJV for JSON schema validation
|
||||||
|
|
||||||
import { generateOpenAICompletions } from "./models";
|
import { generateOpenAICompletions } from "./models";
|
||||||
import { Document, ExtractorOptions } from "../entities";
|
import { Document, ExtractorOptions } from "../entities";
|
||||||
|
import { Logger } from "../logger";
|
||||||
|
|
||||||
// Generate completion using OpenAI
|
// Generate completion using OpenAI
|
||||||
export async function generateCompletions(
|
export async function generateCompletions(
|
||||||
documents: Document[],
|
documents: Document[],
|
||||||
extractionOptions: ExtractorOptions
|
extractionOptions: ExtractorOptions,
|
||||||
|
mode: "markdown" | "raw-html"
|
||||||
): Promise<Document[]> {
|
): Promise<Document[]> {
|
||||||
// const schema = zodToJsonSchema(options.schema)
|
// const schema = zodToJsonSchema(options.schema)
|
||||||
|
|
||||||
const schema = extractionOptions.extractionSchema;
|
const schema = extractionOptions.extractionSchema;
|
||||||
const prompt = extractionOptions.extractionPrompt;
|
const systemPrompt = extractionOptions.extractionPrompt;
|
||||||
|
const prompt = extractionOptions.userPrompt;
|
||||||
|
|
||||||
const switchVariable = "openAI"; // Placholder, want to think more about how we abstract the model provider
|
const switchVariable = "openAI"; // Placholder, want to think more about how we abstract the model provider
|
||||||
|
|
||||||
|
|
@ -22,28 +25,34 @@ export async function generateCompletions(
|
||||||
switch (switchVariable) {
|
switch (switchVariable) {
|
||||||
case "openAI":
|
case "openAI":
|
||||||
const llm = new OpenAI();
|
const llm = new OpenAI();
|
||||||
try{
|
try {
|
||||||
const completionResult = await generateOpenAICompletions({
|
const completionResult = await generateOpenAICompletions({
|
||||||
client: llm,
|
client: llm,
|
||||||
document: document,
|
document: document,
|
||||||
schema: schema,
|
schema: schema,
|
||||||
prompt: prompt,
|
prompt: prompt,
|
||||||
|
systemPrompt: systemPrompt,
|
||||||
|
mode: mode,
|
||||||
});
|
});
|
||||||
// Validate the JSON output against the schema using AJV
|
// Validate the JSON output against the schema using AJV
|
||||||
|
if (schema) {
|
||||||
const validate = ajv.compile(schema);
|
const validate = ajv.compile(schema);
|
||||||
if (!validate(completionResult.llm_extraction)) {
|
if (!validate(completionResult.llm_extraction)) {
|
||||||
//TODO: add Custom Error handling middleware that bubbles this up with proper Error code, etc.
|
//TODO: add Custom Error handling middleware that bubbles this up with proper Error code, etc.
|
||||||
throw new Error(
|
throw new Error(
|
||||||
`JSON parsing error(s): ${validate.errors
|
`JSON parsing error(s): ${validate.errors
|
||||||
?.map((err) => err.message)
|
?.map((err) => err.message)
|
||||||
.join(", ")}\n\nLLM extraction did not match the extraction schema you provided. This could be because of a model hallucination, or an Error on our side. Try adjusting your prompt, and if it doesn't work reach out to support.`
|
.join(
|
||||||
|
", "
|
||||||
|
)}\n\nLLM extraction did not match the extraction schema you provided. This could be because of a model hallucination, or an Error on our side. Try adjusting your prompt, and if it doesn't work reach out to support.`
|
||||||
);
|
);
|
||||||
}
|
}
|
||||||
|
}
|
||||||
|
|
||||||
return completionResult;
|
return completionResult;
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error(`Error generating completions: ${error}`);
|
Logger.error(`Error generating completions: ${error}`);
|
||||||
throw new Error(`Error generating completions: ${error.message}`);
|
throw error;
|
||||||
}
|
}
|
||||||
default:
|
default:
|
||||||
throw new Error("Invalid client");
|
throw new Error("Invalid client");
|
||||||
|
|
|
||||||
|
|
@ -13,52 +13,100 @@ const defaultPrompt =
|
||||||
"You are a professional web scraper. Extract the contents of the webpage";
|
"You are a professional web scraper. Extract the contents of the webpage";
|
||||||
|
|
||||||
function prepareOpenAIDoc(
|
function prepareOpenAIDoc(
|
||||||
document: Document
|
document: Document,
|
||||||
): [OpenAI.Chat.Completions.ChatCompletionContentPart[], number] {
|
mode: "markdown" | "raw-html"
|
||||||
|
): [OpenAI.Chat.Completions.ChatCompletionContentPart[], number] | null {
|
||||||
let markdown = document.markdown;
|
let markdown = document.markdown;
|
||||||
|
|
||||||
// Check if the markdown content exists in the document
|
let extractionTarget = document.markdown;
|
||||||
if (!markdown) {
|
|
||||||
throw new Error(
|
if (mode === "raw-html") {
|
||||||
"Markdown content is missing in the document. This is likely due to an error in the scraping process. Please try again or reach out to help@mendable.ai"
|
extractionTarget = document.rawHtml;
|
||||||
);
|
}
|
||||||
|
|
||||||
|
// Check if the markdown content exists in the document
|
||||||
|
if (!extractionTarget) {
|
||||||
|
return null;
|
||||||
|
// throw new Error(
|
||||||
|
// `${mode} content is missing in the document. This is likely due to an error in the scraping process. Please try again or reach out to help@mendable.ai`
|
||||||
|
// );
|
||||||
}
|
}
|
||||||
|
|
||||||
// count number of tokens
|
// count number of tokens
|
||||||
const numTokens = numTokensFromString(document.markdown, "gpt-4");
|
const numTokens = numTokensFromString(extractionTarget, "gpt-4");
|
||||||
|
|
||||||
if (numTokens > maxTokens) {
|
if (numTokens > maxTokens) {
|
||||||
// trim the document to the maximum number of tokens, tokens != characters
|
// trim the document to the maximum number of tokens, tokens != characters
|
||||||
markdown = markdown.slice(0, (maxTokens * modifier));
|
extractionTarget = extractionTarget.slice(0, maxTokens * modifier);
|
||||||
}
|
}
|
||||||
|
return [[{ type: "text", text: extractionTarget }], numTokens];
|
||||||
return [[{ type: "text", text: markdown }], numTokens];
|
|
||||||
}
|
}
|
||||||
|
|
||||||
export async function generateOpenAICompletions({
|
export async function generateOpenAICompletions({
|
||||||
client,
|
client,
|
||||||
model = "gpt-4o",
|
model = process.env.MODEL_NAME || "gpt-4o-mini",
|
||||||
document,
|
document,
|
||||||
schema, //TODO - add zod dynamic type checking
|
schema, //TODO - add zod dynamic type checking
|
||||||
prompt = defaultPrompt,
|
systemPrompt = defaultPrompt,
|
||||||
|
prompt,
|
||||||
temperature,
|
temperature,
|
||||||
|
mode,
|
||||||
}: {
|
}: {
|
||||||
client: OpenAI;
|
client: OpenAI;
|
||||||
model?: string;
|
model?: string;
|
||||||
document: Document;
|
document: Document;
|
||||||
schema: any; // This should be replaced with a proper Zod schema type when available
|
schema: any; // This should be replaced with a proper Zod schema type when available
|
||||||
prompt?: string;
|
prompt?: string;
|
||||||
|
systemPrompt?: string;
|
||||||
temperature?: number;
|
temperature?: number;
|
||||||
|
mode: "markdown" | "raw-html";
|
||||||
}): Promise<Document> {
|
}): Promise<Document> {
|
||||||
const openai = client as OpenAI;
|
const openai = client as OpenAI;
|
||||||
const [content, numTokens] = prepareOpenAIDoc(document);
|
const preparedDoc = prepareOpenAIDoc(document, mode);
|
||||||
|
|
||||||
const completion = await openai.chat.completions.create({
|
if (preparedDoc === null) {
|
||||||
|
return {
|
||||||
|
...document,
|
||||||
|
warning:
|
||||||
|
"LLM extraction was not performed since the document's content is empty or missing.",
|
||||||
|
};
|
||||||
|
}
|
||||||
|
const [content, numTokens] = preparedDoc;
|
||||||
|
|
||||||
|
let completion;
|
||||||
|
let llmExtraction;
|
||||||
|
if (prompt && !schema) {
|
||||||
|
const jsonCompletion = await openai.chat.completions.create({
|
||||||
model,
|
model,
|
||||||
messages: [
|
messages: [
|
||||||
{
|
{
|
||||||
role: "system",
|
role: "system",
|
||||||
content: prompt,
|
content: systemPrompt,
|
||||||
|
},
|
||||||
|
{ role: "user", content },
|
||||||
|
{
|
||||||
|
role: "user",
|
||||||
|
content: `Transform the above content into structured json output based on the following user request: ${prompt}`,
|
||||||
|
},
|
||||||
|
],
|
||||||
|
response_format: { type: "json_object" },
|
||||||
|
temperature,
|
||||||
|
});
|
||||||
|
|
||||||
|
try {
|
||||||
|
llmExtraction = JSON.parse(
|
||||||
|
jsonCompletion.choices[0].message.content.trim()
|
||||||
|
);
|
||||||
|
} catch (e) {
|
||||||
|
throw new Error("Invalid JSON");
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
completion = await openai.chat.completions.create({
|
||||||
|
model,
|
||||||
|
messages: [
|
||||||
|
{
|
||||||
|
role: "system",
|
||||||
|
content: systemPrompt,
|
||||||
},
|
},
|
||||||
{ role: "user", content },
|
{ role: "user", content },
|
||||||
],
|
],
|
||||||
|
|
@ -72,20 +120,26 @@ export async function generateOpenAICompletions({
|
||||||
},
|
},
|
||||||
},
|
},
|
||||||
],
|
],
|
||||||
tool_choice: { "type": "function", "function": {"name": "extract_content"}},
|
tool_choice: { type: "function", function: { name: "extract_content" } },
|
||||||
temperature,
|
temperature,
|
||||||
});
|
});
|
||||||
|
|
||||||
const c = completion.choices[0].message.tool_calls[0].function.arguments;
|
const c = completion.choices[0].message.tool_calls[0].function.arguments;
|
||||||
|
|
||||||
// Extract the LLM extraction content from the completion response
|
// Extract the LLM extraction content from the completion response
|
||||||
const llmExtraction = JSON.parse(c);
|
try {
|
||||||
|
llmExtraction = JSON.parse(c);
|
||||||
|
} catch (e) {
|
||||||
|
throw new Error("Invalid JSON");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
// Return the document with the LLM extraction content added
|
// Return the document with the LLM extraction content added
|
||||||
return {
|
return {
|
||||||
...document,
|
...document,
|
||||||
llm_extraction: llmExtraction,
|
llm_extraction: llmExtraction,
|
||||||
warning: numTokens > maxTokens ? `Page was trimmed to fit the maximum token limit defined by the LLM model (Max: ${maxTokens} tokens, Attemped: ${numTokens} tokens). If results are not good, email us at help@mendable.ai so we can help you.` : undefined,
|
warning:
|
||||||
|
numTokens > maxTokens
|
||||||
|
? `Page was trimmed to fit the maximum token limit defined by the LLM model (Max: ${maxTokens} tokens, Attemped: ${numTokens} tokens). If results are not good, email us at help@mendable.ai so we can help you.`
|
||||||
|
: undefined,
|
||||||
};
|
};
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
|
||||||
40
apps/api/src/lib/__tests__/html-to-markdown.test.ts
Normal file
40
apps/api/src/lib/__tests__/html-to-markdown.test.ts
Normal file
|
|
@ -0,0 +1,40 @@
|
||||||
|
import { parseMarkdown } from '../html-to-markdown';
|
||||||
|
|
||||||
|
describe('parseMarkdown', () => {
|
||||||
|
it('should correctly convert simple HTML to Markdown', async () => {
|
||||||
|
const html = '<p>Hello, world!</p>';
|
||||||
|
const expectedMarkdown = 'Hello, world!';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should convert complex HTML with nested elements to Markdown', async () => {
|
||||||
|
const html = '<div><p>Hello <strong>bold</strong> world!</p><ul><li>List item</li></ul></div>';
|
||||||
|
const expectedMarkdown = 'Hello **bold** world!\n\n- List item';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should return empty string when input is empty', async () => {
|
||||||
|
const html = '';
|
||||||
|
const expectedMarkdown = '';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should handle null input gracefully', async () => {
|
||||||
|
const html = null;
|
||||||
|
const expectedMarkdown = '';
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expectedMarkdown);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should handle various types of invalid HTML gracefully', async () => {
|
||||||
|
const invalidHtmls = [
|
||||||
|
{ html: '<html><p>Unclosed tag', expected: 'Unclosed tag' },
|
||||||
|
{ html: '<div><span>Missing closing div', expected: 'Missing closing div' },
|
||||||
|
{ html: '<p><strong>Wrong nesting</em></strong></p>', expected: '**Wrong nesting**' },
|
||||||
|
{ html: '<a href="http://example.com">Link without closing tag', expected: '[Link without closing tag](http://example.com)' }
|
||||||
|
];
|
||||||
|
|
||||||
|
for (const { html, expected } of invalidHtmls) {
|
||||||
|
await expect(parseMarkdown(html)).resolves.toBe(expected);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
134
apps/api/src/lib/__tests__/job-priority.test.ts
Normal file
134
apps/api/src/lib/__tests__/job-priority.test.ts
Normal file
|
|
@ -0,0 +1,134 @@
|
||||||
|
import {
|
||||||
|
getJobPriority,
|
||||||
|
addJobPriority,
|
||||||
|
deleteJobPriority,
|
||||||
|
} from "../job-priority";
|
||||||
|
import { redisConnection } from "../../services/queue-service";
|
||||||
|
import { PlanType } from "../../types";
|
||||||
|
|
||||||
|
jest.mock("../../services/queue-service", () => ({
|
||||||
|
redisConnection: {
|
||||||
|
sadd: jest.fn(),
|
||||||
|
srem: jest.fn(),
|
||||||
|
scard: jest.fn(),
|
||||||
|
expire: jest.fn(),
|
||||||
|
},
|
||||||
|
}));
|
||||||
|
|
||||||
|
describe("Job Priority Tests", () => {
|
||||||
|
afterEach(() => {
|
||||||
|
jest.clearAllMocks();
|
||||||
|
});
|
||||||
|
|
||||||
|
test("addJobPriority should add job_id to the set and set expiration", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
const job_id = "job1";
|
||||||
|
await addJobPriority(team_id, job_id);
|
||||||
|
expect(redisConnection.sadd).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
job_id
|
||||||
|
);
|
||||||
|
expect(redisConnection.expire).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
60
|
||||||
|
);
|
||||||
|
});
|
||||||
|
|
||||||
|
test("deleteJobPriority should remove job_id from the set", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
const job_id = "job1";
|
||||||
|
await deleteJobPriority(team_id, job_id);
|
||||||
|
expect(redisConnection.srem).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
job_id
|
||||||
|
);
|
||||||
|
});
|
||||||
|
|
||||||
|
test("getJobPriority should return correct priority based on plan and set length", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
const plan: PlanType = "standard";
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(150);
|
||||||
|
|
||||||
|
const priority = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priority).toBe(10);
|
||||||
|
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(250);
|
||||||
|
const priorityExceeded = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priorityExceeded).toBe(20); // basePriority + Math.ceil((250 - 200) * 0.4)
|
||||||
|
});
|
||||||
|
|
||||||
|
test("getJobPriority should handle different plans correctly", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(50);
|
||||||
|
let plan: PlanType = "hobby";
|
||||||
|
let priority = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priority).toBe(10);
|
||||||
|
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(150);
|
||||||
|
plan = "hobby";
|
||||||
|
priority = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priority).toBe(25); // basePriority + Math.ceil((150 - 50) * 0.3)
|
||||||
|
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(25);
|
||||||
|
plan = "free";
|
||||||
|
priority = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priority).toBe(10);
|
||||||
|
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(60);
|
||||||
|
plan = "free";
|
||||||
|
priority = await getJobPriority({ plan, team_id });
|
||||||
|
expect(priority).toBe(28); // basePriority + Math.ceil((60 - 25) * 0.5)
|
||||||
|
});
|
||||||
|
|
||||||
|
test("addJobPriority should reset expiration time when adding new job", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
const job_id1 = "job1";
|
||||||
|
const job_id2 = "job2";
|
||||||
|
|
||||||
|
await addJobPriority(team_id, job_id1);
|
||||||
|
expect(redisConnection.expire).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
60
|
||||||
|
);
|
||||||
|
|
||||||
|
// Clear the mock calls
|
||||||
|
(redisConnection.expire as jest.Mock).mockClear();
|
||||||
|
|
||||||
|
// Add another job
|
||||||
|
await addJobPriority(team_id, job_id2);
|
||||||
|
expect(redisConnection.expire).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
60
|
||||||
|
);
|
||||||
|
});
|
||||||
|
|
||||||
|
test("Set should expire after 60 seconds", async () => {
|
||||||
|
const team_id = "team1";
|
||||||
|
const job_id = "job1";
|
||||||
|
|
||||||
|
jest.useFakeTimers();
|
||||||
|
|
||||||
|
await addJobPriority(team_id, job_id);
|
||||||
|
expect(redisConnection.expire).toHaveBeenCalledWith(
|
||||||
|
`limit_team_id:${team_id}`,
|
||||||
|
60
|
||||||
|
);
|
||||||
|
|
||||||
|
// Fast-forward time by 59 seconds
|
||||||
|
jest.advanceTimersByTime(59000);
|
||||||
|
|
||||||
|
// The set should still exist
|
||||||
|
expect(redisConnection.scard).not.toHaveBeenCalled();
|
||||||
|
|
||||||
|
// Fast-forward time by 2 more seconds (total 61 seconds)
|
||||||
|
jest.advanceTimersByTime(2000);
|
||||||
|
|
||||||
|
// Check if the set has been removed (scard should return 0)
|
||||||
|
(redisConnection.scard as jest.Mock).mockResolvedValue(0);
|
||||||
|
const setSize = await redisConnection.scard(`limit_team_id:${team_id}`);
|
||||||
|
expect(setSize).toBe(0);
|
||||||
|
|
||||||
|
jest.useRealTimers();
|
||||||
|
});
|
||||||
|
});
|
||||||
48
apps/api/src/lib/concurrency-limit.ts
Normal file
48
apps/api/src/lib/concurrency-limit.ts
Normal file
|
|
@ -0,0 +1,48 @@
|
||||||
|
import { getRateLimiterPoints } from "../services/rate-limiter";
|
||||||
|
import { redisConnection } from "../services/queue-service";
|
||||||
|
import { RateLimiterMode } from "../types";
|
||||||
|
import { JobsOptions } from "bullmq";
|
||||||
|
|
||||||
|
const constructKey = (team_id: string) => "concurrency-limiter:" + team_id;
|
||||||
|
const constructQueueKey = (team_id: string) => "concurrency-limit-queue:" + team_id;
|
||||||
|
const stalledJobTimeoutMs = 2 * 60 * 1000;
|
||||||
|
|
||||||
|
export function getConcurrencyLimitMax(plan: string): number {
|
||||||
|
return getRateLimiterPoints(RateLimiterMode.Scrape, undefined, plan);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function cleanOldConcurrencyLimitEntries(team_id: string, now: number = Date.now()) {
|
||||||
|
await redisConnection.zremrangebyscore(constructKey(team_id), -Infinity, now);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getConcurrencyLimitActiveJobs(team_id: string, now: number = Date.now()): Promise<string[]> {
|
||||||
|
return await redisConnection.zrangebyscore(constructKey(team_id), now, Infinity);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function pushConcurrencyLimitActiveJob(team_id: string, id: string, now: number = Date.now()) {
|
||||||
|
await redisConnection.zadd(constructKey(team_id), now + stalledJobTimeoutMs, id);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function removeConcurrencyLimitActiveJob(team_id: string, id: string) {
|
||||||
|
await redisConnection.zrem(constructKey(team_id), id);
|
||||||
|
}
|
||||||
|
|
||||||
|
export type ConcurrencyLimitedJob = {
|
||||||
|
id: string;
|
||||||
|
data: any;
|
||||||
|
opts: JobsOptions;
|
||||||
|
priority?: number;
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function takeConcurrencyLimitedJob(team_id: string): Promise<ConcurrencyLimitedJob | null> {
|
||||||
|
const res = await redisConnection.zmpop(1, constructQueueKey(team_id), "MIN");
|
||||||
|
if (res === null || res === undefined) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
return JSON.parse(res[1][0][0]);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function pushConcurrencyLimitedJob(team_id: string, job: ConcurrencyLimitedJob) {
|
||||||
|
await redisConnection.zadd(constructQueueKey(team_id), job.priority ?? 1, JSON.stringify(job));
|
||||||
|
}
|
||||||
152
apps/api/src/lib/crawl-redis.ts
Normal file
152
apps/api/src/lib/crawl-redis.ts
Normal file
|
|
@ -0,0 +1,152 @@
|
||||||
|
import { WebCrawler } from "../scraper/WebScraper/crawler";
|
||||||
|
import { redisConnection } from "../services/queue-service";
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
|
||||||
|
export type StoredCrawl = {
|
||||||
|
originUrl?: string;
|
||||||
|
crawlerOptions: any;
|
||||||
|
pageOptions: any;
|
||||||
|
team_id: string;
|
||||||
|
plan: string;
|
||||||
|
robots?: string;
|
||||||
|
cancelled?: boolean;
|
||||||
|
createdAt: number;
|
||||||
|
};
|
||||||
|
|
||||||
|
export async function saveCrawl(id: string, crawl: StoredCrawl) {
|
||||||
|
await redisConnection.set("crawl:" + id, JSON.stringify(crawl));
|
||||||
|
await redisConnection.expire("crawl:" + id, 24 * 60 * 60, "NX");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getCrawl(id: string): Promise<StoredCrawl | null> {
|
||||||
|
const x = await redisConnection.get("crawl:" + id);
|
||||||
|
|
||||||
|
if (x === null) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
return JSON.parse(x);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getCrawlExpiry(id: string): Promise<Date> {
|
||||||
|
const d = new Date();
|
||||||
|
const ttl = await redisConnection.pttl("crawl:" + id);
|
||||||
|
d.setMilliseconds(d.getMilliseconds() + ttl);
|
||||||
|
d.setMilliseconds(0);
|
||||||
|
return d;
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function addCrawlJob(id: string, job_id: string) {
|
||||||
|
await redisConnection.sadd("crawl:" + id + ":jobs", job_id);
|
||||||
|
await redisConnection.expire("crawl:" + id + ":jobs", 24 * 60 * 60, "NX");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function addCrawlJobs(id: string, job_ids: string[]) {
|
||||||
|
await redisConnection.sadd("crawl:" + id + ":jobs", ...job_ids);
|
||||||
|
await redisConnection.expire("crawl:" + id + ":jobs", 24 * 60 * 60, "NX");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function addCrawlJobDone(id: string, job_id: string) {
|
||||||
|
await redisConnection.sadd("crawl:" + id + ":jobs_done", job_id);
|
||||||
|
await redisConnection.lpush("crawl:" + id + ":jobs_done_ordered", job_id);
|
||||||
|
await redisConnection.expire("crawl:" + id + ":jobs_done", 24 * 60 * 60, "NX");
|
||||||
|
await redisConnection.expire("crawl:" + id + ":jobs_done_ordered", 24 * 60 * 60, "NX");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getDoneJobsOrderedLength(id: string): Promise<number> {
|
||||||
|
return await redisConnection.llen("crawl:" + id + ":jobs_done_ordered");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getDoneJobsOrdered(id: string, start = 0, end = -1): Promise<string[]> {
|
||||||
|
return await redisConnection.lrange("crawl:" + id + ":jobs_done_ordered", start, end);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function isCrawlFinished(id: string) {
|
||||||
|
return (await redisConnection.scard("crawl:" + id + ":jobs_done")) === (await redisConnection.scard("crawl:" + id + ":jobs"));
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function isCrawlFinishedLocked(id: string) {
|
||||||
|
return (await redisConnection.exists("crawl:" + id + ":finish"));
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function finishCrawl(id: string) {
|
||||||
|
if (await isCrawlFinished(id)) {
|
||||||
|
const set = await redisConnection.setnx("crawl:" + id + ":finish", "yes");
|
||||||
|
if (set === 1) {
|
||||||
|
await redisConnection.expire("crawl:" + id + ":finish", 24 * 60 * 60);
|
||||||
|
}
|
||||||
|
return set === 1
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getCrawlJobs(id: string): Promise<string[]> {
|
||||||
|
return await redisConnection.smembers("crawl:" + id + ":jobs");
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getThrottledJobs(teamId: string): Promise<string[]> {
|
||||||
|
return await redisConnection.zrangebyscore("concurrency-limiter:" + teamId + ":throttled", Date.now(), Infinity);
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function lockURL(id: string, sc: StoredCrawl, url: string): Promise<boolean> {
|
||||||
|
if (typeof sc.crawlerOptions?.limit === "number") {
|
||||||
|
if (await redisConnection.scard("crawl:" + id + ":visited") >= sc.crawlerOptions.limit) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
const urlO = new URL(url);
|
||||||
|
urlO.search = "";
|
||||||
|
urlO.hash = "";
|
||||||
|
url = urlO.href;
|
||||||
|
} catch (error) {
|
||||||
|
Logger.warn("Failed to normalize URL " + JSON.stringify(url) + ": " + error);
|
||||||
|
}
|
||||||
|
|
||||||
|
const res = (await redisConnection.sadd("crawl:" + id + ":visited", url)) !== 0
|
||||||
|
await redisConnection.expire("crawl:" + id + ":visited", 24 * 60 * 60, "NX");
|
||||||
|
return res;
|
||||||
|
}
|
||||||
|
|
||||||
|
/// NOTE: does not check limit. only use if limit is checked beforehand e.g. with sitemap
|
||||||
|
export async function lockURLs(id: string, urls: string[]): Promise<boolean> {
|
||||||
|
urls = urls.map(url => {
|
||||||
|
try {
|
||||||
|
const urlO = new URL(url);
|
||||||
|
urlO.search = "";
|
||||||
|
urlO.hash = "";
|
||||||
|
return urlO.href;
|
||||||
|
} catch (error) {
|
||||||
|
Logger.warn("Failed to normalize URL " + JSON.stringify(url) + ": " + error);
|
||||||
|
}
|
||||||
|
|
||||||
|
return url;
|
||||||
|
});
|
||||||
|
|
||||||
|
const res = (await redisConnection.sadd("crawl:" + id + ":visited", ...urls)) !== 0
|
||||||
|
await redisConnection.expire("crawl:" + id + ":visited", 24 * 60 * 60, "NX");
|
||||||
|
return res;
|
||||||
|
}
|
||||||
|
|
||||||
|
export function crawlToCrawler(id: string, sc: StoredCrawl): WebCrawler {
|
||||||
|
const crawler = new WebCrawler({
|
||||||
|
jobId: id,
|
||||||
|
initialUrl: sc.originUrl,
|
||||||
|
includes: sc.crawlerOptions?.includes ?? [],
|
||||||
|
excludes: sc.crawlerOptions?.excludes ?? [],
|
||||||
|
maxCrawledLinks: sc.crawlerOptions?.maxCrawledLinks ?? 1000,
|
||||||
|
maxCrawledDepth: sc.crawlerOptions?.maxDepth ?? 10,
|
||||||
|
limit: sc.crawlerOptions?.limit ?? 10000,
|
||||||
|
generateImgAltText: sc.crawlerOptions?.generateImgAltText ?? false,
|
||||||
|
allowBackwardCrawling: sc.crawlerOptions?.allowBackwardCrawling ?? false,
|
||||||
|
allowExternalContentLinks: sc.crawlerOptions?.allowExternalContentLinks ?? false,
|
||||||
|
});
|
||||||
|
|
||||||
|
if (sc.robots !== undefined) {
|
||||||
|
try {
|
||||||
|
crawler.importRobotsTxt(sc.robots);
|
||||||
|
} catch (_) {}
|
||||||
|
}
|
||||||
|
|
||||||
|
return crawler;
|
||||||
|
}
|
||||||
|
|
@ -19,3 +19,4 @@ export class CustomError extends Error {
|
||||||
Object.setPrototypeOf(this, CustomError.prototype);
|
Object.setPrototypeOf(this, CustomError.prototype);
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
|
||||||
28
apps/api/src/lib/default-values.ts
Normal file
28
apps/api/src/lib/default-values.ts
Normal file
|
|
@ -0,0 +1,28 @@
|
||||||
|
export const defaultOrigin = "api";
|
||||||
|
|
||||||
|
export const defaultTimeout = 60000; // 60 seconds
|
||||||
|
|
||||||
|
export const defaultPageOptions = {
|
||||||
|
onlyMainContent: false,
|
||||||
|
includeHtml: false,
|
||||||
|
waitFor: 0,
|
||||||
|
screenshot: false,
|
||||||
|
fullPageScreenshot: false,
|
||||||
|
parsePDF: true
|
||||||
|
};
|
||||||
|
|
||||||
|
export const defaultCrawlerOptions = {
|
||||||
|
allowBackwardCrawling: false,
|
||||||
|
limit: 10000
|
||||||
|
}
|
||||||
|
|
||||||
|
export const defaultCrawlPageOptions = {
|
||||||
|
onlyMainContent: false,
|
||||||
|
includeHtml: false,
|
||||||
|
removeTags: [],
|
||||||
|
parsePDF: true
|
||||||
|
}
|
||||||
|
|
||||||
|
export const defaultExtractorOptions = {
|
||||||
|
mode: "markdown"
|
||||||
|
}
|
||||||
|
|
@ -10,22 +10,63 @@ export interface Progress {
|
||||||
currentDocument?: Document;
|
currentDocument?: Document;
|
||||||
}
|
}
|
||||||
|
|
||||||
|
export type Action = {
|
||||||
|
type: "wait",
|
||||||
|
milliseconds?: number,
|
||||||
|
selector?: string,
|
||||||
|
} | {
|
||||||
|
type: "click",
|
||||||
|
selector: string,
|
||||||
|
} | {
|
||||||
|
type: "screenshot",
|
||||||
|
fullPage?: boolean,
|
||||||
|
} | {
|
||||||
|
type: "write",
|
||||||
|
text: string,
|
||||||
|
} | {
|
||||||
|
type: "press",
|
||||||
|
key: string,
|
||||||
|
} | {
|
||||||
|
type: "scroll",
|
||||||
|
direction: "up" | "down"
|
||||||
|
} | {
|
||||||
|
type: "scrape",
|
||||||
|
}
|
||||||
|
|
||||||
export type PageOptions = {
|
export type PageOptions = {
|
||||||
|
includeMarkdown?: boolean;
|
||||||
|
includeExtract?: boolean;
|
||||||
onlyMainContent?: boolean;
|
onlyMainContent?: boolean;
|
||||||
includeHtml?: boolean;
|
includeHtml?: boolean;
|
||||||
|
includeRawHtml?: boolean;
|
||||||
fallback?: boolean;
|
fallback?: boolean;
|
||||||
fetchPageContent?: boolean;
|
fetchPageContent?: boolean;
|
||||||
waitFor?: number;
|
waitFor?: number;
|
||||||
screenshot?: boolean;
|
screenshot?: boolean;
|
||||||
|
fullPageScreenshot?: boolean;
|
||||||
headers?: Record<string, string>;
|
headers?: Record<string, string>;
|
||||||
replaceAllPathsWithAbsolutePaths?: boolean;
|
replaceAllPathsWithAbsolutePaths?: boolean;
|
||||||
|
parsePDF?: boolean;
|
||||||
removeTags?: string | string[];
|
removeTags?: string | string[];
|
||||||
|
onlyIncludeTags?: string | string[];
|
||||||
|
includeLinks?: boolean;
|
||||||
|
useFastMode?: boolean; // beta
|
||||||
|
disableJsDom?: boolean; // beta
|
||||||
|
atsv?: boolean; // anti-bot solver, beta
|
||||||
|
actions?: Action[]; // beta
|
||||||
|
geolocation?: {
|
||||||
|
country?: string;
|
||||||
|
};
|
||||||
|
skipTlsVerification?: boolean;
|
||||||
|
removeBase64Images?: boolean;
|
||||||
|
mobile?: boolean;
|
||||||
};
|
};
|
||||||
|
|
||||||
export type ExtractorOptions = {
|
export type ExtractorOptions = {
|
||||||
mode: "markdown" | "llm-extraction";
|
mode: "markdown" | "llm-extraction" | "llm-extraction-from-markdown" | "llm-extraction-from-raw-html";
|
||||||
extractionPrompt?: string;
|
extractionPrompt?: string;
|
||||||
extractionSchema?: Record<string, any>;
|
extractionSchema?: Record<string, any>;
|
||||||
|
userPrompt?: string;
|
||||||
}
|
}
|
||||||
|
|
||||||
export type SearchOptions = {
|
export type SearchOptions = {
|
||||||
|
|
@ -39,8 +80,8 @@ export type SearchOptions = {
|
||||||
|
|
||||||
export type CrawlerOptions = {
|
export type CrawlerOptions = {
|
||||||
returnOnlyUrls?: boolean;
|
returnOnlyUrls?: boolean;
|
||||||
includes?: string[];
|
includes?: string | string[];
|
||||||
excludes?: string[];
|
excludes?: string | string[];
|
||||||
maxCrawledLinks?: number;
|
maxCrawledLinks?: number;
|
||||||
maxDepth?: number;
|
maxDepth?: number;
|
||||||
limit?: number;
|
limit?: number;
|
||||||
|
|
@ -49,9 +90,11 @@ export type CrawlerOptions = {
|
||||||
ignoreSitemap?: boolean;
|
ignoreSitemap?: boolean;
|
||||||
mode?: "default" | "fast"; // have a mode of some sort
|
mode?: "default" | "fast"; // have a mode of some sort
|
||||||
allowBackwardCrawling?: boolean;
|
allowBackwardCrawling?: boolean;
|
||||||
|
allowExternalContentLinks?: boolean;
|
||||||
}
|
}
|
||||||
|
|
||||||
export type WebScraperOptions = {
|
export type WebScraperOptions = {
|
||||||
|
jobId: string;
|
||||||
urls: string[];
|
urls: string[];
|
||||||
mode: "single_urls" | "sitemap" | "crawl";
|
mode: "single_urls" | "sitemap" | "crawl";
|
||||||
crawlerOptions?: CrawlerOptions;
|
crawlerOptions?: CrawlerOptions;
|
||||||
|
|
@ -59,6 +102,8 @@ export type WebScraperOptions = {
|
||||||
extractorOptions?: ExtractorOptions;
|
extractorOptions?: ExtractorOptions;
|
||||||
concurrentRequests?: number;
|
concurrentRequests?: number;
|
||||||
bullJobId?: string;
|
bullJobId?: string;
|
||||||
|
priority?: number;
|
||||||
|
teamId?: string;
|
||||||
};
|
};
|
||||||
|
|
||||||
export interface DocumentUrl {
|
export interface DocumentUrl {
|
||||||
|
|
@ -71,6 +116,7 @@ export class Document {
|
||||||
content: string;
|
content: string;
|
||||||
markdown?: string;
|
markdown?: string;
|
||||||
html?: string;
|
html?: string;
|
||||||
|
rawHtml?: string;
|
||||||
llm_extraction?: Record<string, any>;
|
llm_extraction?: Record<string, any>;
|
||||||
createdAt?: Date;
|
createdAt?: Date;
|
||||||
updatedAt?: Date;
|
updatedAt?: Date;
|
||||||
|
|
@ -82,8 +128,12 @@ export class Document {
|
||||||
childrenLinks?: string[];
|
childrenLinks?: string[];
|
||||||
provider?: string;
|
provider?: string;
|
||||||
warning?: string;
|
warning?: string;
|
||||||
|
actions?: {
|
||||||
|
screenshots: string[];
|
||||||
|
}
|
||||||
|
|
||||||
index?: number;
|
index?: number;
|
||||||
|
linksOnPage?: string[]; // Add this new field as a separate property
|
||||||
|
|
||||||
constructor(data: Partial<Document>) {
|
constructor(data: Partial<Document>) {
|
||||||
if (!data.content) {
|
if (!data.content) {
|
||||||
|
|
@ -97,6 +147,7 @@ export class Document {
|
||||||
this.markdown = data.markdown || "";
|
this.markdown = data.markdown || "";
|
||||||
this.childrenLinks = data.childrenLinks || undefined;
|
this.childrenLinks = data.childrenLinks || undefined;
|
||||||
this.provider = data.provider || undefined;
|
this.provider = data.provider || undefined;
|
||||||
|
this.linksOnPage = data.linksOnPage; // Assign linksOnPage if provided
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
@ -117,7 +168,26 @@ export class SearchResult {
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
export interface ScrapeActionContent {
|
||||||
|
url: string;
|
||||||
|
html: string;
|
||||||
|
}
|
||||||
|
|
||||||
export interface FireEngineResponse {
|
export interface FireEngineResponse {
|
||||||
html: string;
|
html: string;
|
||||||
screenshot: string;
|
screenshots?: string[];
|
||||||
|
pageStatusCode?: number;
|
||||||
|
pageError?: string;
|
||||||
|
scrapeActionContent?: ScrapeActionContent[];
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
export interface FireEngineOptions{
|
||||||
|
mobileProxy?: boolean;
|
||||||
|
method?: string;
|
||||||
|
engine?: string;
|
||||||
|
blockMedia?: boolean;
|
||||||
|
blockAds?: boolean;
|
||||||
|
disableJsDom?: boolean;
|
||||||
|
atsv?: boolean; // beta
|
||||||
}
|
}
|
||||||
|
|
@ -1,8 +1,68 @@
|
||||||
|
|
||||||
export function parseMarkdown(html: string) {
|
import koffi from 'koffi';
|
||||||
|
import { join } from 'path';
|
||||||
|
import "../services/sentry"
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
import dotenv from 'dotenv';
|
||||||
|
import { Logger } from './logger';
|
||||||
|
dotenv.config();
|
||||||
|
|
||||||
|
// TODO: add a timeout to the Go parser
|
||||||
|
|
||||||
|
class GoMarkdownConverter {
|
||||||
|
private static instance: GoMarkdownConverter;
|
||||||
|
private convert: any;
|
||||||
|
|
||||||
|
private constructor() {
|
||||||
|
const goExecutablePath = join(process.cwd(), 'sharedLibs', 'go-html-to-md', 'html-to-markdown.so');
|
||||||
|
const lib = koffi.load(goExecutablePath);
|
||||||
|
this.convert = lib.func('ConvertHTMLToMarkdown', 'string', ['string']);
|
||||||
|
}
|
||||||
|
|
||||||
|
public static getInstance(): GoMarkdownConverter {
|
||||||
|
if (!GoMarkdownConverter.instance) {
|
||||||
|
GoMarkdownConverter.instance = new GoMarkdownConverter();
|
||||||
|
}
|
||||||
|
return GoMarkdownConverter.instance;
|
||||||
|
}
|
||||||
|
|
||||||
|
public async convertHTMLToMarkdown(html: string): Promise<string> {
|
||||||
|
return new Promise<string>((resolve, reject) => {
|
||||||
|
this.convert.async(html, (err: Error, res: string) => {
|
||||||
|
if (err) {
|
||||||
|
reject(err);
|
||||||
|
} else {
|
||||||
|
resolve(res);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function parseMarkdown(html: string): Promise<string> {
|
||||||
|
if (!html) {
|
||||||
|
return '';
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
if (process.env.USE_GO_MARKDOWN_PARSER == "true") {
|
||||||
|
const converter = GoMarkdownConverter.getInstance();
|
||||||
|
let markdownContent = await converter.convertHTMLToMarkdown(html);
|
||||||
|
|
||||||
|
markdownContent = processMultiLineLinks(markdownContent);
|
||||||
|
markdownContent = removeSkipToContentLinks(markdownContent);
|
||||||
|
Logger.info(`HTML to Markdown conversion using Go parser successful`);
|
||||||
|
return markdownContent;
|
||||||
|
}
|
||||||
|
} catch (error) {
|
||||||
|
Sentry.captureException(error);
|
||||||
|
Logger.error(`Error converting HTML to Markdown with Go parser: ${error}`);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Fallback to TurndownService if Go parser fails or is not enabled
|
||||||
var TurndownService = require("turndown");
|
var TurndownService = require("turndown");
|
||||||
var turndownPluginGfm = require('joplin-turndown-plugin-gfm')
|
var turndownPluginGfm = require('joplin-turndown-plugin-gfm');
|
||||||
|
|
||||||
|
|
||||||
const turndownService = new TurndownService();
|
const turndownService = new TurndownService();
|
||||||
turndownService.addRule("inlineLink", {
|
turndownService.addRule("inlineLink", {
|
||||||
|
|
@ -21,9 +81,20 @@ export function parseMarkdown(html: string) {
|
||||||
});
|
});
|
||||||
var gfm = turndownPluginGfm.gfm;
|
var gfm = turndownPluginGfm.gfm;
|
||||||
turndownService.use(gfm);
|
turndownService.use(gfm);
|
||||||
let markdownContent = turndownService.turndown(html);
|
|
||||||
|
|
||||||
// multiple line links
|
try {
|
||||||
|
let markdownContent = await turndownService.turndown(html);
|
||||||
|
markdownContent = processMultiLineLinks(markdownContent);
|
||||||
|
markdownContent = removeSkipToContentLinks(markdownContent);
|
||||||
|
|
||||||
|
return markdownContent;
|
||||||
|
} catch (error) {
|
||||||
|
console.error("Error converting HTML to Markdown: ", error);
|
||||||
|
return ""; // Optionally return an empty string or handle the error as needed
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
function processMultiLineLinks(markdownContent: string): string {
|
||||||
let insideLinkContent = false;
|
let insideLinkContent = false;
|
||||||
let newMarkdownContent = "";
|
let newMarkdownContent = "";
|
||||||
let linkOpenCount = 0;
|
let linkOpenCount = 0;
|
||||||
|
|
@ -43,13 +114,14 @@ export function parseMarkdown(html: string) {
|
||||||
newMarkdownContent += char;
|
newMarkdownContent += char;
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
markdownContent = newMarkdownContent;
|
return newMarkdownContent;
|
||||||
|
}
|
||||||
|
|
||||||
|
function removeSkipToContentLinks(markdownContent: string): string {
|
||||||
// Remove [Skip to Content](#page) and [Skip to content](#skip)
|
// Remove [Skip to Content](#page) and [Skip to content](#skip)
|
||||||
markdownContent = markdownContent.replace(
|
const newMarkdownContent = markdownContent.replace(
|
||||||
/\[Skip to Content\]\(#[^\)]*\)/gi,
|
/\[Skip to Content\]\(#[^\)]*\)/gi,
|
||||||
""
|
""
|
||||||
);
|
);
|
||||||
|
return newMarkdownContent;
|
||||||
return markdownContent;
|
|
||||||
}
|
}
|
||||||
99
apps/api/src/lib/job-priority.ts
Normal file
99
apps/api/src/lib/job-priority.ts
Normal file
|
|
@ -0,0 +1,99 @@
|
||||||
|
import { redisConnection } from "../../src/services/queue-service";
|
||||||
|
import { PlanType } from "../../src/types";
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
|
||||||
|
const SET_KEY_PREFIX = "limit_team_id:";
|
||||||
|
export async function addJobPriority(team_id, job_id) {
|
||||||
|
try {
|
||||||
|
const setKey = SET_KEY_PREFIX + team_id;
|
||||||
|
|
||||||
|
// Add scrape job id to the set
|
||||||
|
await redisConnection.sadd(setKey, job_id);
|
||||||
|
|
||||||
|
// This approach will reset the expiration time to 60 seconds every time a new job is added to the set.
|
||||||
|
await redisConnection.expire(setKey, 60);
|
||||||
|
} catch (e) {
|
||||||
|
Logger.error(`Add job priority (sadd) failed: ${team_id}, ${job_id}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function deleteJobPriority(team_id, job_id) {
|
||||||
|
try {
|
||||||
|
const setKey = SET_KEY_PREFIX + team_id;
|
||||||
|
|
||||||
|
// remove job_id from the set
|
||||||
|
await redisConnection.srem(setKey, job_id);
|
||||||
|
} catch (e) {
|
||||||
|
Logger.error(`Delete job priority (srem) failed: ${team_id}, ${job_id}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export async function getJobPriority({
|
||||||
|
plan,
|
||||||
|
team_id,
|
||||||
|
basePriority = 10,
|
||||||
|
}: {
|
||||||
|
plan: PlanType;
|
||||||
|
team_id: string;
|
||||||
|
basePriority?: number;
|
||||||
|
}): Promise<number> {
|
||||||
|
if (team_id === "d97c4ceb-290b-4957-8432-2b2a02727d95") {
|
||||||
|
return 50;
|
||||||
|
}
|
||||||
|
|
||||||
|
try {
|
||||||
|
const setKey = SET_KEY_PREFIX + team_id;
|
||||||
|
|
||||||
|
// Get the length of the set
|
||||||
|
const setLength = await redisConnection.scard(setKey);
|
||||||
|
|
||||||
|
// Determine the priority based on the plan and set length
|
||||||
|
let planModifier = 1;
|
||||||
|
let bucketLimit = 0;
|
||||||
|
|
||||||
|
switch (plan) {
|
||||||
|
case "free":
|
||||||
|
bucketLimit = 25;
|
||||||
|
planModifier = 0.5;
|
||||||
|
break;
|
||||||
|
case "hobby":
|
||||||
|
bucketLimit = 100;
|
||||||
|
planModifier = 0.3;
|
||||||
|
break;
|
||||||
|
case "standard":
|
||||||
|
case "standardnew":
|
||||||
|
bucketLimit = 200;
|
||||||
|
planModifier = 0.2;
|
||||||
|
break;
|
||||||
|
case "growth":
|
||||||
|
case "growthdouble":
|
||||||
|
bucketLimit = 400;
|
||||||
|
planModifier = 0.1;
|
||||||
|
break;
|
||||||
|
case "etier2c":
|
||||||
|
bucketLimit = 1000;
|
||||||
|
planModifier = 0.05;
|
||||||
|
break;
|
||||||
|
|
||||||
|
default:
|
||||||
|
bucketLimit = 25;
|
||||||
|
planModifier = 1;
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
|
||||||
|
// if length set is smaller than set, just return base priority
|
||||||
|
if (setLength <= bucketLimit) {
|
||||||
|
return basePriority;
|
||||||
|
} else {
|
||||||
|
// If not, we keep base priority + planModifier
|
||||||
|
return Math.ceil(
|
||||||
|
basePriority + Math.ceil((setLength - bucketLimit) * planModifier)
|
||||||
|
);
|
||||||
|
}
|
||||||
|
} catch (e) {
|
||||||
|
Logger.error(
|
||||||
|
`Get job priority failed: ${team_id}, ${plan}, ${basePriority}`
|
||||||
|
);
|
||||||
|
return basePriority;
|
||||||
|
}
|
||||||
|
}
|
||||||
57
apps/api/src/lib/logger.ts
Normal file
57
apps/api/src/lib/logger.ts
Normal file
|
|
@ -0,0 +1,57 @@
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
enum LogLevel {
|
||||||
|
NONE = 'NONE', // No logs will be output.
|
||||||
|
ERROR = 'ERROR', // For logging error messages that indicate a failure in a specific operation.
|
||||||
|
WARN = 'WARN', // For logging potentially harmful situations that are not necessarily errors.
|
||||||
|
INFO = 'INFO', // For logging informational messages that highlight the progress of the application.
|
||||||
|
DEBUG = 'DEBUG', // For logging detailed information on the flow through the system, primarily used for debugging.
|
||||||
|
TRACE = 'TRACE' // For logging more detailed information than the DEBUG level.
|
||||||
|
}
|
||||||
|
export class Logger {
|
||||||
|
static colors = {
|
||||||
|
ERROR: '\x1b[31m%s\x1b[0m', // Red
|
||||||
|
WARN: '\x1b[33m%s\x1b[0m', // Yellow
|
||||||
|
INFO: '\x1b[34m%s\x1b[0m', // Blue
|
||||||
|
DEBUG: '\x1b[36m%s\x1b[0m', // Cyan
|
||||||
|
TRACE: '\x1b[35m%s\x1b[0m' // Magenta
|
||||||
|
};
|
||||||
|
|
||||||
|
static log (message: string, level: LogLevel) {
|
||||||
|
const logLevel: LogLevel = LogLevel[process.env.LOGGING_LEVEL as keyof typeof LogLevel] || LogLevel.TRACE;
|
||||||
|
const levels = [LogLevel.NONE, LogLevel.ERROR, LogLevel.WARN, LogLevel.INFO, LogLevel.DEBUG, LogLevel.TRACE];
|
||||||
|
const currentLevelIndex = levels.indexOf(logLevel);
|
||||||
|
const messageLevelIndex = levels.indexOf(level);
|
||||||
|
|
||||||
|
if (currentLevelIndex >= messageLevelIndex) {
|
||||||
|
const color = Logger.colors[level];
|
||||||
|
console[level.toLowerCase()](color, `[${new Date().toISOString()}]${level} - ${message}`);
|
||||||
|
|
||||||
|
// const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
// if (useDbAuthentication) {
|
||||||
|
// save to supabase? another place?
|
||||||
|
// supabase.from('logs').insert({ level: level, message: message, timestamp: new Date().toISOString(), success: boolean });
|
||||||
|
// }
|
||||||
|
}
|
||||||
|
}
|
||||||
|
static error(message: string | any) {
|
||||||
|
Logger.log(message, LogLevel.ERROR);
|
||||||
|
}
|
||||||
|
|
||||||
|
static warn(message: string) {
|
||||||
|
Logger.log(message, LogLevel.WARN);
|
||||||
|
}
|
||||||
|
|
||||||
|
static info(message: string) {
|
||||||
|
Logger.log(message, LogLevel.INFO);
|
||||||
|
}
|
||||||
|
|
||||||
|
static debug(message: string) {
|
||||||
|
Logger.log(message, LogLevel.DEBUG);
|
||||||
|
}
|
||||||
|
|
||||||
|
static trace(message: string) {
|
||||||
|
Logger.log(message, LogLevel.TRACE);
|
||||||
|
}
|
||||||
|
}
|
||||||
46
apps/api/src/lib/map-cosine.ts
Normal file
46
apps/api/src/lib/map-cosine.ts
Normal file
|
|
@ -0,0 +1,46 @@
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
|
||||||
|
export function performCosineSimilarity(links: string[], searchQuery: string) {
|
||||||
|
try {
|
||||||
|
// Function to calculate cosine similarity
|
||||||
|
const cosineSimilarity = (vec1: number[], vec2: number[]): number => {
|
||||||
|
const dotProduct = vec1.reduce((sum, val, i) => sum + val * vec2[i], 0);
|
||||||
|
const magnitude1 = Math.sqrt(
|
||||||
|
vec1.reduce((sum, val) => sum + val * val, 0)
|
||||||
|
);
|
||||||
|
const magnitude2 = Math.sqrt(
|
||||||
|
vec2.reduce((sum, val) => sum + val * val, 0)
|
||||||
|
);
|
||||||
|
if (magnitude1 === 0 || magnitude2 === 0) return 0;
|
||||||
|
return dotProduct / (magnitude1 * magnitude2);
|
||||||
|
};
|
||||||
|
|
||||||
|
// Function to convert text to vector
|
||||||
|
const textToVector = (text: string): number[] => {
|
||||||
|
const words = searchQuery.toLowerCase().split(/\W+/);
|
||||||
|
return words.map((word) => {
|
||||||
|
const count = (text.toLowerCase().match(new RegExp(word, "g")) || [])
|
||||||
|
.length;
|
||||||
|
return count / text.length;
|
||||||
|
});
|
||||||
|
};
|
||||||
|
|
||||||
|
// Calculate similarity scores
|
||||||
|
const similarityScores = links.map((link) => {
|
||||||
|
const linkVector = textToVector(link);
|
||||||
|
const searchVector = textToVector(searchQuery);
|
||||||
|
return cosineSimilarity(linkVector, searchVector);
|
||||||
|
});
|
||||||
|
|
||||||
|
// Sort links based on similarity scores and print scores
|
||||||
|
const a = links
|
||||||
|
.map((link, index) => ({ link, score: similarityScores[index] }))
|
||||||
|
.sort((a, b) => b.score - a.score);
|
||||||
|
|
||||||
|
links = a.map((item) => item.link);
|
||||||
|
return links;
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error performing cosine similarity: ${error}`);
|
||||||
|
return links;
|
||||||
|
}
|
||||||
|
}
|
||||||
87
apps/api/src/lib/scrape-events.ts
Normal file
87
apps/api/src/lib/scrape-events.ts
Normal file
|
|
@ -0,0 +1,87 @@
|
||||||
|
import { Job } from "bullmq";
|
||||||
|
import type { baseScrapers } from "../scraper/WebScraper/single_url";
|
||||||
|
import { supabase_service as supabase } from "../services/supabase";
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
|
export type ScrapeErrorEvent = {
|
||||||
|
type: "error",
|
||||||
|
message: string,
|
||||||
|
stack?: string,
|
||||||
|
}
|
||||||
|
|
||||||
|
export type ScrapeScrapeEvent = {
|
||||||
|
type: "scrape",
|
||||||
|
url: string,
|
||||||
|
worker?: string,
|
||||||
|
method: (typeof baseScrapers)[number],
|
||||||
|
result: null | {
|
||||||
|
success: boolean,
|
||||||
|
response_code?: number,
|
||||||
|
response_size?: number,
|
||||||
|
error?: string | object,
|
||||||
|
// proxy?: string,
|
||||||
|
time_taken: number,
|
||||||
|
},
|
||||||
|
}
|
||||||
|
|
||||||
|
export type ScrapeQueueEvent = {
|
||||||
|
type: "queue",
|
||||||
|
event: "waiting" | "active" | "completed" | "paused" | "resumed" | "removed" | "failed",
|
||||||
|
worker?: string,
|
||||||
|
}
|
||||||
|
|
||||||
|
export type ScrapeEvent = ScrapeErrorEvent | ScrapeScrapeEvent | ScrapeQueueEvent;
|
||||||
|
|
||||||
|
export class ScrapeEvents {
|
||||||
|
static async insert(jobId: string, content: ScrapeEvent) {
|
||||||
|
if (jobId === "TEST") return null;
|
||||||
|
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
if (useDbAuthentication) {
|
||||||
|
try {
|
||||||
|
const result = await supabase.from("scrape_events").insert({
|
||||||
|
job_id: jobId,
|
||||||
|
type: content.type,
|
||||||
|
content: content,
|
||||||
|
// created_at
|
||||||
|
}).select().single();
|
||||||
|
return (result.data as any).id;
|
||||||
|
} catch (error) {
|
||||||
|
// Logger.error(`Error inserting scrape event: ${error}`);
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
static async updateScrapeResult(logId: number | null, result: ScrapeScrapeEvent["result"]) {
|
||||||
|
if (logId === null) return;
|
||||||
|
|
||||||
|
try {
|
||||||
|
const previousLog = (await supabase.from("scrape_events").select().eq("id", logId).single()).data as any;
|
||||||
|
await supabase.from("scrape_events").update({
|
||||||
|
content: {
|
||||||
|
...previousLog.content,
|
||||||
|
result,
|
||||||
|
}
|
||||||
|
}).eq("id", logId);
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error updating scrape result: ${error}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
static async logJobEvent(job: Job | any, event: ScrapeQueueEvent["event"]) {
|
||||||
|
try {
|
||||||
|
await this.insert(((job as any).id ? (job as any).id : job) as string, {
|
||||||
|
type: "queue",
|
||||||
|
event,
|
||||||
|
worker: process.env.FLY_MACHINE_ID,
|
||||||
|
});
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`Error logging job event: ${error}`);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
93
apps/api/src/lib/supabase-jobs.ts
Normal file
93
apps/api/src/lib/supabase-jobs.ts
Normal file
|
|
@ -0,0 +1,93 @@
|
||||||
|
import { supabase_service } from "../services/supabase";
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get a single firecrawl_job by ID
|
||||||
|
* @param jobId ID of Job
|
||||||
|
* @returns {any | null} Job
|
||||||
|
*/
|
||||||
|
export const supabaseGetJobById = async (jobId: string) => {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.select("*")
|
||||||
|
.eq("job_id", jobId)
|
||||||
|
.single();
|
||||||
|
|
||||||
|
if (error) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!data) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
return data;
|
||||||
|
};
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get multiple firecrawl_jobs by ID. Use this if you're not requesting a lot (50+) of jobs at once.
|
||||||
|
* @param jobIds IDs of Jobs
|
||||||
|
* @returns {any[]} Jobs
|
||||||
|
*/
|
||||||
|
export const supabaseGetJobsById = async (jobIds: string[]) => {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.select()
|
||||||
|
.in("job_id", jobIds);
|
||||||
|
|
||||||
|
if (error) {
|
||||||
|
Logger.error(`Error in supabaseGetJobsById: ${error}`);
|
||||||
|
Sentry.captureException(error);
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!data) {
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
return data;
|
||||||
|
};
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Get multiple firecrawl_jobs by crawl ID. Use this if you need a lot of jobs at once.
|
||||||
|
* @param crawlId ID of crawl
|
||||||
|
* @returns {any[]} Jobs
|
||||||
|
*/
|
||||||
|
export const supabaseGetJobsByCrawlId = async (crawlId: string) => {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.select()
|
||||||
|
.eq("crawl_id", crawlId)
|
||||||
|
|
||||||
|
if (error) {
|
||||||
|
Logger.error(`Error in supabaseGetJobsByCrawlId: ${error}`);
|
||||||
|
Sentry.captureException(error);
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!data) {
|
||||||
|
return [];
|
||||||
|
}
|
||||||
|
|
||||||
|
return data;
|
||||||
|
};
|
||||||
|
|
||||||
|
|
||||||
|
export const supabaseGetJobByIdOnlyData = async (jobId: string) => {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.select("docs, team_id")
|
||||||
|
.eq("job_id", jobId)
|
||||||
|
.single();
|
||||||
|
|
||||||
|
if (error) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
if (!data) {
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
|
||||||
|
return data;
|
||||||
|
};
|
||||||
1
apps/api/src/lib/timeout.ts
Normal file
1
apps/api/src/lib/timeout.ts
Normal file
|
|
@ -0,0 +1 @@
|
||||||
|
export const axiosTimeout = 3000;
|
||||||
2261
apps/api/src/lib/validate-country.ts
Normal file
2261
apps/api/src/lib/validate-country.ts
Normal file
File diff suppressed because it is too large
Load Diff
159
apps/api/src/lib/validateUrl.test.ts
Normal file
159
apps/api/src/lib/validateUrl.test.ts
Normal file
|
|
@ -0,0 +1,159 @@
|
||||||
|
import { isSameDomain, removeDuplicateUrls } from "./validateUrl";
|
||||||
|
import { isSameSubdomain } from "./validateUrl";
|
||||||
|
|
||||||
|
describe("isSameDomain", () => {
|
||||||
|
it("should return true for a subdomain", () => {
|
||||||
|
const result = isSameDomain("http://sub.example.com", "http://example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for the same domain", () => {
|
||||||
|
const result = isSameDomain("http://example.com", "http://example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for different domains", () => {
|
||||||
|
const result = isSameDomain("http://example.com", "http://another.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for a subdomain with different protocols", () => {
|
||||||
|
const result = isSameDomain("https://sub.example.com", "http://example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for invalid URLs", () => {
|
||||||
|
const result = isSameDomain("invalid-url", "http://example.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
const result2 = isSameDomain("http://example.com", "invalid-url");
|
||||||
|
expect(result2).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for a subdomain with www prefix", () => {
|
||||||
|
const result = isSameDomain("http://www.sub.example.com", "http://example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for the same domain with www prefix", () => {
|
||||||
|
const result = isSameDomain("http://docs.s.s.example.com", "http://example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
describe("isSameSubdomain", () => {
|
||||||
|
it("should return false for a subdomain", () => {
|
||||||
|
const result = isSameSubdomain("http://example.com", "http://docs.example.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for the same subdomain", () => {
|
||||||
|
const result = isSameSubdomain("http://docs.example.com", "http://docs.example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for different subdomains", () => {
|
||||||
|
const result = isSameSubdomain("http://docs.example.com", "http://blog.example.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for different domains", () => {
|
||||||
|
const result = isSameSubdomain("http://example.com", "http://another.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for invalid URLs", () => {
|
||||||
|
const result = isSameSubdomain("invalid-url", "http://example.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
const result2 = isSameSubdomain("http://example.com", "invalid-url");
|
||||||
|
expect(result2).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for the same subdomain with different protocols", () => {
|
||||||
|
const result = isSameSubdomain("https://docs.example.com", "http://docs.example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return true for the same subdomain with www prefix", () => {
|
||||||
|
const result = isSameSubdomain("http://www.docs.example.com", "http://docs.example.com");
|
||||||
|
expect(result).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should return false for a subdomain with www prefix and different subdomain", () => {
|
||||||
|
const result = isSameSubdomain("http://www.docs.example.com", "http://blog.example.com");
|
||||||
|
expect(result).toBe(false);
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
||||||
|
describe("removeDuplicateUrls", () => {
|
||||||
|
it("should remove duplicate URLs with different protocols", () => {
|
||||||
|
const urls = [
|
||||||
|
"http://example.com",
|
||||||
|
"https://example.com",
|
||||||
|
"http://www.example.com",
|
||||||
|
"https://www.example.com"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual(["https://example.com"]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should keep URLs with different paths", () => {
|
||||||
|
const urls = [
|
||||||
|
"https://example.com/page1",
|
||||||
|
"https://example.com/page2",
|
||||||
|
"https://example.com/page1?param=1",
|
||||||
|
"https://example.com/page1#section1"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual([
|
||||||
|
"https://example.com/page1",
|
||||||
|
"https://example.com/page2",
|
||||||
|
"https://example.com/page1?param=1",
|
||||||
|
"https://example.com/page1#section1"
|
||||||
|
]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should prefer https over http", () => {
|
||||||
|
const urls = [
|
||||||
|
"http://example.com",
|
||||||
|
"https://example.com"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual(["https://example.com"]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should prefer non-www over www", () => {
|
||||||
|
const urls = [
|
||||||
|
"https://www.example.com",
|
||||||
|
"https://example.com"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual(["https://example.com"]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle empty input", () => {
|
||||||
|
const urls: string[] = [];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual([]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with different cases", () => {
|
||||||
|
const urls = [
|
||||||
|
"https://EXAMPLE.com",
|
||||||
|
"https://example.com"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual(["https://EXAMPLE.com"]);
|
||||||
|
});
|
||||||
|
|
||||||
|
it("should handle URLs with trailing slashes", () => {
|
||||||
|
const urls = [
|
||||||
|
"https://example.com",
|
||||||
|
"https://example.com/"
|
||||||
|
];
|
||||||
|
const result = removeDuplicateUrls(urls);
|
||||||
|
expect(result).toEqual(["https://example.com"]);
|
||||||
|
});
|
||||||
|
});
|
||||||
170
apps/api/src/lib/validateUrl.ts
Normal file
170
apps/api/src/lib/validateUrl.ts
Normal file
|
|
@ -0,0 +1,170 @@
|
||||||
|
export const protocolIncluded = (url: string) => {
|
||||||
|
// if :// not in the start of the url assume http (maybe https?)
|
||||||
|
// regex checks if :// appears before any .
|
||||||
|
return /^([^.:]+:\/\/)/.test(url);
|
||||||
|
};
|
||||||
|
|
||||||
|
const getURLobj = (s: string) => {
|
||||||
|
// URL fails if we dont include the protocol ie google.com
|
||||||
|
let error = false;
|
||||||
|
let urlObj = {};
|
||||||
|
try {
|
||||||
|
urlObj = new URL(s);
|
||||||
|
} catch (err) {
|
||||||
|
error = true;
|
||||||
|
}
|
||||||
|
return { error, urlObj };
|
||||||
|
};
|
||||||
|
|
||||||
|
export const checkAndUpdateURL = (url: string) => {
|
||||||
|
if (!protocolIncluded(url)) {
|
||||||
|
url = `http://${url}`;
|
||||||
|
}
|
||||||
|
|
||||||
|
const { error, urlObj } = getURLobj(url);
|
||||||
|
if (error) {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
const typedUrlObj = urlObj as URL;
|
||||||
|
|
||||||
|
if (typedUrlObj.protocol !== "http:" && typedUrlObj.protocol !== "https:") {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
return { urlObj: typedUrlObj, url: url };
|
||||||
|
};
|
||||||
|
|
||||||
|
export const checkUrl = (url: string) => {
|
||||||
|
const { error, urlObj } = getURLobj(url);
|
||||||
|
if (error) {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
const typedUrlObj = urlObj as URL;
|
||||||
|
|
||||||
|
if (typedUrlObj.protocol !== "http:" && typedUrlObj.protocol !== "https:") {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
if ((url.split(".")[0].match(/:/g) || []).length !== 1) {
|
||||||
|
throw new Error("Invalid URL. Invalid protocol."); // for this one: http://http://example.com
|
||||||
|
}
|
||||||
|
|
||||||
|
return url;
|
||||||
|
};
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Same domain check
|
||||||
|
* It checks if the domain of the url is the same as the base url
|
||||||
|
* It accounts true for subdomains and www.subdomains
|
||||||
|
* @param url
|
||||||
|
* @param baseUrl
|
||||||
|
* @returns
|
||||||
|
*/
|
||||||
|
export function isSameDomain(url: string, baseUrl: string) {
|
||||||
|
const { urlObj: urlObj1, error: error1 } = getURLobj(url);
|
||||||
|
const { urlObj: urlObj2, error: error2 } = getURLobj(baseUrl);
|
||||||
|
|
||||||
|
if (error1 || error2) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const typedUrlObj1 = urlObj1 as URL;
|
||||||
|
const typedUrlObj2 = urlObj2 as URL;
|
||||||
|
|
||||||
|
const cleanHostname = (hostname: string) => {
|
||||||
|
return hostname.startsWith('www.') ? hostname.slice(4) : hostname;
|
||||||
|
};
|
||||||
|
|
||||||
|
const domain1 = cleanHostname(typedUrlObj1.hostname).split('.').slice(-2).join('.');
|
||||||
|
const domain2 = cleanHostname(typedUrlObj2.hostname).split('.').slice(-2).join('.');
|
||||||
|
|
||||||
|
return domain1 === domain2;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
export function isSameSubdomain(url: string, baseUrl: string) {
|
||||||
|
const { urlObj: urlObj1, error: error1 } = getURLobj(url);
|
||||||
|
const { urlObj: urlObj2, error: error2 } = getURLobj(baseUrl);
|
||||||
|
|
||||||
|
if (error1 || error2) {
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
|
||||||
|
const typedUrlObj1 = urlObj1 as URL;
|
||||||
|
const typedUrlObj2 = urlObj2 as URL;
|
||||||
|
|
||||||
|
const cleanHostname = (hostname: string) => {
|
||||||
|
return hostname.startsWith('www.') ? hostname.slice(4) : hostname;
|
||||||
|
};
|
||||||
|
|
||||||
|
const domain1 = cleanHostname(typedUrlObj1.hostname).split('.').slice(-2).join('.');
|
||||||
|
const domain2 = cleanHostname(typedUrlObj2.hostname).split('.').slice(-2).join('.');
|
||||||
|
|
||||||
|
const subdomain1 = cleanHostname(typedUrlObj1.hostname).split('.').slice(0, -2).join('.');
|
||||||
|
const subdomain2 = cleanHostname(typedUrlObj2.hostname).split('.').slice(0, -2).join('.');
|
||||||
|
|
||||||
|
// Check if the domains are the same and the subdomains are the same
|
||||||
|
return domain1 === domain2 && subdomain1 === subdomain2;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
export const checkAndUpdateURLForMap = (url: string) => {
|
||||||
|
if (!protocolIncluded(url)) {
|
||||||
|
url = `http://${url}`;
|
||||||
|
}
|
||||||
|
// remove last slash if present
|
||||||
|
if (url.endsWith("/")) {
|
||||||
|
url = url.slice(0, -1);
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
const { error, urlObj } = getURLobj(url);
|
||||||
|
if (error) {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
const typedUrlObj = urlObj as URL;
|
||||||
|
|
||||||
|
if (typedUrlObj.protocol !== "http:" && typedUrlObj.protocol !== "https:") {
|
||||||
|
throw new Error("Invalid URL");
|
||||||
|
}
|
||||||
|
|
||||||
|
// remove any query params
|
||||||
|
url = url.split("?")[0].trim();
|
||||||
|
|
||||||
|
return { urlObj: typedUrlObj, url: url };
|
||||||
|
};
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
export function removeDuplicateUrls(urls: string[]): string[] {
|
||||||
|
const urlMap = new Map<string, string>();
|
||||||
|
|
||||||
|
for (const url of urls) {
|
||||||
|
const parsedUrl = new URL(url);
|
||||||
|
const protocol = parsedUrl.protocol;
|
||||||
|
const hostname = parsedUrl.hostname.replace(/^www\./, '');
|
||||||
|
const path = parsedUrl.pathname + parsedUrl.search + parsedUrl.hash;
|
||||||
|
|
||||||
|
const key = `${hostname}${path}`;
|
||||||
|
|
||||||
|
if (!urlMap.has(key)) {
|
||||||
|
urlMap.set(key, url);
|
||||||
|
} else {
|
||||||
|
const existingUrl = new URL(urlMap.get(key)!);
|
||||||
|
const existingProtocol = existingUrl.protocol;
|
||||||
|
|
||||||
|
if (protocol === 'https:' && existingProtocol === 'http:') {
|
||||||
|
urlMap.set(key, url);
|
||||||
|
} else if (protocol === existingProtocol && !parsedUrl.hostname.startsWith('www.') && existingUrl.hostname.startsWith('www.')) {
|
||||||
|
urlMap.set(key, url);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return [...new Set(Array.from(urlMap.values()))];
|
||||||
|
}
|
||||||
|
|
@ -1,4 +1,8 @@
|
||||||
import { AuthResponse } from "../../src/types";
|
import { AuthResponse } from "../../src/types";
|
||||||
|
import { Logger } from "./logger";
|
||||||
|
import * as Sentry from "@sentry/node";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
let warningCount = 0;
|
let warningCount = 0;
|
||||||
|
|
||||||
|
|
@ -6,9 +10,10 @@ export function withAuth<T extends AuthResponse, U extends any[]>(
|
||||||
originalFunction: (...args: U) => Promise<T>
|
originalFunction: (...args: U) => Promise<T>
|
||||||
) {
|
) {
|
||||||
return async function (...args: U): Promise<T> {
|
return async function (...args: U): Promise<T> {
|
||||||
if (process.env.USE_DB_AUTHENTICATION === "false") {
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
if (!useDbAuthentication) {
|
||||||
if (warningCount < 5) {
|
if (warningCount < 5) {
|
||||||
console.warn("WARNING - You're bypassing authentication");
|
Logger.warn("You're bypassing authentication");
|
||||||
warningCount++;
|
warningCount++;
|
||||||
}
|
}
|
||||||
return { success: true } as T;
|
return { success: true } as T;
|
||||||
|
|
@ -16,7 +21,8 @@ export function withAuth<T extends AuthResponse, U extends any[]>(
|
||||||
try {
|
try {
|
||||||
return await originalFunction(...args);
|
return await originalFunction(...args);
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error("Error in withAuth function: ", error);
|
Sentry.captureException(error);
|
||||||
|
Logger.error(`Error in withAuth function: ${error}`);
|
||||||
return { success: false, error: error.message } as T;
|
return { success: false, error: error.message } as T;
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
|
||||||
|
|
@ -1,81 +1,102 @@
|
||||||
import { Job } from "bull";
|
import { Job } from "bullmq";
|
||||||
import { CrawlResult, WebScraperOptions } from "../types";
|
import {
|
||||||
|
CrawlResult,
|
||||||
|
WebScraperOptions,
|
||||||
|
RunWebScraperParams,
|
||||||
|
RunWebScraperResult,
|
||||||
|
} from "../types";
|
||||||
import { WebScraperDataProvider } from "../scraper/WebScraper";
|
import { WebScraperDataProvider } from "../scraper/WebScraper";
|
||||||
import { DocumentUrl, Progress } from "../lib/entities";
|
import { DocumentUrl, Progress } from "../lib/entities";
|
||||||
import { billTeam } from "../services/billing/credit_billing";
|
import { billTeam } from "../services/billing/credit_billing";
|
||||||
import { Document } from "../lib/entities";
|
import { Document } from "../lib/entities";
|
||||||
|
import { supabase_service } from "../services/supabase";
|
||||||
|
import { Logger } from "../lib/logger";
|
||||||
|
import { ScrapeEvents } from "../lib/scrape-events";
|
||||||
|
import { configDotenv } from "dotenv";
|
||||||
|
configDotenv();
|
||||||
|
|
||||||
export async function startWebScraperPipeline({
|
export async function startWebScraperPipeline({
|
||||||
job,
|
job,
|
||||||
|
token,
|
||||||
}: {
|
}: {
|
||||||
job: Job<WebScraperOptions>;
|
job: Job<WebScraperOptions>;
|
||||||
|
token: string;
|
||||||
}) {
|
}) {
|
||||||
let partialDocs: Document[] = [];
|
let partialDocs: Document[] = [];
|
||||||
return (await runWebScraper({
|
return (await runWebScraper({
|
||||||
url: job.data.url,
|
url: job.data.url,
|
||||||
mode: job.data.mode,
|
mode: job.data.mode,
|
||||||
crawlerOptions: job.data.crawlerOptions,
|
crawlerOptions: job.data.crawlerOptions,
|
||||||
pageOptions: job.data.pageOptions,
|
extractorOptions: job.data.extractorOptions,
|
||||||
|
pageOptions: {
|
||||||
|
...job.data.pageOptions,
|
||||||
|
...(job.data.crawl_id ? ({
|
||||||
|
includeRawHtml: true,
|
||||||
|
}): {}),
|
||||||
|
},
|
||||||
inProgress: (progress) => {
|
inProgress: (progress) => {
|
||||||
|
Logger.debug(`🐂 Job in progress ${job.id}`);
|
||||||
if (progress.currentDocument) {
|
if (progress.currentDocument) {
|
||||||
partialDocs.push(progress.currentDocument);
|
partialDocs.push(progress.currentDocument);
|
||||||
if (partialDocs.length > 50) {
|
if (partialDocs.length > 50) {
|
||||||
partialDocs = partialDocs.slice(-50);
|
partialDocs = partialDocs.slice(-50);
|
||||||
}
|
}
|
||||||
job.progress({ ...progress, partialDocs: partialDocs });
|
// job.updateProgress({ ...progress, partialDocs: partialDocs });
|
||||||
}
|
}
|
||||||
},
|
},
|
||||||
onSuccess: (result) => {
|
onSuccess: (result, mode) => {
|
||||||
job.moveToCompleted(result);
|
Logger.debug(`🐂 Job completed ${job.id}`);
|
||||||
|
saveJob(job, result, token, mode);
|
||||||
},
|
},
|
||||||
onError: (error) => {
|
onError: (error) => {
|
||||||
job.moveToFailed(error);
|
Logger.error(`🐂 Job failed ${job.id}`);
|
||||||
|
ScrapeEvents.logJobEvent(job, "failed");
|
||||||
|
job.moveToFailed(error, token, false);
|
||||||
},
|
},
|
||||||
team_id: job.data.team_id,
|
team_id: job.data.team_id,
|
||||||
bull_job_id: job.id.toString(),
|
bull_job_id: job.id.toString(),
|
||||||
|
priority: job.opts.priority,
|
||||||
|
is_scrape: job.data.is_scrape ?? false,
|
||||||
})) as { success: boolean; message: string; docs: Document[] };
|
})) as { success: boolean; message: string; docs: Document[] };
|
||||||
}
|
}
|
||||||
|
|
||||||
export async function runWebScraper({
|
export async function runWebScraper({
|
||||||
url,
|
url,
|
||||||
mode,
|
mode,
|
||||||
crawlerOptions,
|
crawlerOptions,
|
||||||
pageOptions,
|
pageOptions,
|
||||||
|
extractorOptions,
|
||||||
inProgress,
|
inProgress,
|
||||||
onSuccess,
|
onSuccess,
|
||||||
onError,
|
onError,
|
||||||
team_id,
|
team_id,
|
||||||
bull_job_id,
|
bull_job_id,
|
||||||
}: {
|
priority,
|
||||||
url: string;
|
is_scrape=false,
|
||||||
mode: "crawl" | "single_urls" | "sitemap";
|
}: RunWebScraperParams): Promise<RunWebScraperResult> {
|
||||||
crawlerOptions: any;
|
|
||||||
pageOptions?: any;
|
|
||||||
inProgress: (progress: any) => void;
|
|
||||||
onSuccess: (result: any) => void;
|
|
||||||
onError: (error: any) => void;
|
|
||||||
team_id: string;
|
|
||||||
bull_job_id: string;
|
|
||||||
}): Promise<{
|
|
||||||
success: boolean;
|
|
||||||
message: string;
|
|
||||||
docs: Document[] | DocumentUrl[];
|
|
||||||
}> {
|
|
||||||
try {
|
try {
|
||||||
const provider = new WebScraperDataProvider();
|
const provider = new WebScraperDataProvider();
|
||||||
if (mode === "crawl") {
|
if (mode === "crawl") {
|
||||||
await provider.setOptions({
|
await provider.setOptions({
|
||||||
|
jobId: bull_job_id,
|
||||||
mode: mode,
|
mode: mode,
|
||||||
urls: [url],
|
urls: [url],
|
||||||
|
extractorOptions,
|
||||||
crawlerOptions: crawlerOptions,
|
crawlerOptions: crawlerOptions,
|
||||||
pageOptions: pageOptions,
|
pageOptions: pageOptions,
|
||||||
bullJobId: bull_job_id,
|
bullJobId: bull_job_id,
|
||||||
|
priority,
|
||||||
});
|
});
|
||||||
} else {
|
} else {
|
||||||
await provider.setOptions({
|
await provider.setOptions({
|
||||||
|
jobId: bull_job_id,
|
||||||
mode: mode,
|
mode: mode,
|
||||||
urls: url.split(","),
|
urls: url.split(","),
|
||||||
|
extractorOptions,
|
||||||
crawlerOptions: crawlerOptions,
|
crawlerOptions: crawlerOptions,
|
||||||
pageOptions: pageOptions,
|
pageOptions: pageOptions,
|
||||||
|
priority,
|
||||||
|
teamId: team_id
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
const docs = (await provider.getDocuments(false, (progress: Progress) => {
|
const docs = (await provider.getDocuments(false, (progress: Progress) => {
|
||||||
|
|
@ -91,33 +112,67 @@ export async function runWebScraper({
|
||||||
}
|
}
|
||||||
|
|
||||||
// remove docs with empty content
|
// remove docs with empty content
|
||||||
const filteredDocs = crawlerOptions.returnOnlyUrls
|
const filteredDocs = crawlerOptions?.returnOnlyUrls
|
||||||
? docs.map((doc) => {
|
? docs.map((doc) => {
|
||||||
if (doc.metadata.sourceURL) {
|
if (doc.metadata.sourceURL) {
|
||||||
return { url: doc.metadata.sourceURL };
|
return { url: doc.metadata.sourceURL };
|
||||||
}
|
}
|
||||||
})
|
})
|
||||||
: docs.filter((doc) => doc.content.trim().length > 0);
|
: docs;
|
||||||
|
|
||||||
const billingResult = await billTeam(team_id, filteredDocs.length);
|
if(is_scrape === false) {
|
||||||
|
let creditsToBeBilled = 1; // Assuming 1 credit per document
|
||||||
if (!billingResult.success) {
|
if (extractorOptions && (extractorOptions.mode === "llm-extraction" || extractorOptions.mode === "extract")) {
|
||||||
// throw new Error("Failed to bill team, no subscription was found");
|
creditsToBeBilled = 5;
|
||||||
return {
|
|
||||||
success: false,
|
|
||||||
message: "Failed to bill team, no subscription was found",
|
|
||||||
docs: [],
|
|
||||||
};
|
|
||||||
}
|
}
|
||||||
|
|
||||||
|
billTeam(team_id, undefined, creditsToBeBilled * filteredDocs.length).catch(error => {
|
||||||
|
Logger.error(`Failed to bill team ${team_id} for ${creditsToBeBilled * filteredDocs.length} credits: ${error}`);
|
||||||
|
// Optionally, you could notify an admin or add to a retry queue here
|
||||||
|
});
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
// This is where the returnvalue from the job is set
|
// This is where the returnvalue from the job is set
|
||||||
onSuccess(filteredDocs);
|
onSuccess(filteredDocs, mode);
|
||||||
|
|
||||||
// this return doesn't matter too much for the job completion result
|
// this return doesn't matter too much for the job completion result
|
||||||
return { success: true, message: "", docs: filteredDocs };
|
return { success: true, message: "", docs: filteredDocs };
|
||||||
} catch (error) {
|
} catch (error) {
|
||||||
console.error("Error running web scraper", error);
|
|
||||||
onError(error);
|
onError(error);
|
||||||
return { success: false, message: error.message, docs: [] };
|
return { success: false, message: error.message, docs: [] };
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
|
const saveJob = async (job: Job, result: any, token: string, mode: string) => {
|
||||||
|
try {
|
||||||
|
const useDbAuthentication = process.env.USE_DB_AUTHENTICATION === 'true';
|
||||||
|
if (useDbAuthentication) {
|
||||||
|
const { data, error } = await supabase_service
|
||||||
|
.from("firecrawl_jobs")
|
||||||
|
.update({ docs: result })
|
||||||
|
.eq("job_id", job.id);
|
||||||
|
|
||||||
|
if (error) throw new Error(error.message);
|
||||||
|
// try {
|
||||||
|
// if (mode === "crawl") {
|
||||||
|
// await job.moveToCompleted(null, token, false);
|
||||||
|
// } else {
|
||||||
|
// await job.moveToCompleted(result, token, false);
|
||||||
|
// }
|
||||||
|
// } catch (error) {
|
||||||
|
// // I think the job won't exist here anymore
|
||||||
|
// }
|
||||||
|
// } else {
|
||||||
|
// try {
|
||||||
|
// await job.moveToCompleted(result, token, false);
|
||||||
|
// } catch (error) {
|
||||||
|
// // I think the job won't exist here anymore
|
||||||
|
// }
|
||||||
|
}
|
||||||
|
ScrapeEvents.logJobEvent(job, "completed");
|
||||||
|
} catch (error) {
|
||||||
|
Logger.error(`🐂 Failed to update job status: ${error}`);
|
||||||
|
}
|
||||||
|
};
|
||||||
|
|
|
||||||
42
apps/api/src/routes/admin.ts
Normal file
42
apps/api/src/routes/admin.ts
Normal file
|
|
@ -0,0 +1,42 @@
|
||||||
|
import express from "express";
|
||||||
|
import { redisHealthController } from "../controllers/v0/admin/redis-health";
|
||||||
|
import {
|
||||||
|
autoscalerController,
|
||||||
|
checkQueuesController,
|
||||||
|
cleanBefore24hCompleteJobsController,
|
||||||
|
queuesController,
|
||||||
|
} from "../controllers/v0/admin/queue";
|
||||||
|
import { acucCacheClearController } from "../controllers/v0/admin/acuc-cache-clear";
|
||||||
|
import { wrap } from "./v1";
|
||||||
|
|
||||||
|
export const adminRouter = express.Router();
|
||||||
|
|
||||||
|
adminRouter.get(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/redis-health`,
|
||||||
|
redisHealthController
|
||||||
|
);
|
||||||
|
|
||||||
|
adminRouter.get(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/clean-before-24h-complete-jobs`,
|
||||||
|
cleanBefore24hCompleteJobsController
|
||||||
|
);
|
||||||
|
|
||||||
|
adminRouter.get(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/check-queues`,
|
||||||
|
checkQueuesController
|
||||||
|
);
|
||||||
|
|
||||||
|
adminRouter.get(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/queues`,
|
||||||
|
queuesController
|
||||||
|
);
|
||||||
|
|
||||||
|
adminRouter.get(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/autoscaler`,
|
||||||
|
autoscalerController
|
||||||
|
);
|
||||||
|
|
||||||
|
adminRouter.post(
|
||||||
|
`/admin/${process.env.BULL_AUTH_KEY}/acuc-cache-clear`,
|
||||||
|
wrap(acucCacheClearController),
|
||||||
|
);
|
||||||
|
|
@ -1,12 +1,14 @@
|
||||||
import express from "express";
|
import express from "express";
|
||||||
import { crawlController } from "../../src/controllers/crawl";
|
import { crawlController } from "../../src/controllers/v0/crawl";
|
||||||
import { crawlStatusController } from "../../src/controllers/crawl-status";
|
import { crawlStatusController } from "../../src/controllers/v0/crawl-status";
|
||||||
import { scrapeController } from "../../src/controllers/scrape";
|
import { scrapeController } from "../../src/controllers/v0/scrape";
|
||||||
import { crawlPreviewController } from "../../src/controllers/crawlPreview";
|
import { crawlPreviewController } from "../../src/controllers/v0/crawlPreview";
|
||||||
import { crawlJobStatusPreviewController } from "../../src/controllers/status";
|
import { crawlJobStatusPreviewController } from "../../src/controllers/v0/status";
|
||||||
import { searchController } from "../../src/controllers/search";
|
import { searchController } from "../../src/controllers/v0/search";
|
||||||
import { crawlCancelController } from "../../src/controllers/crawl-cancel";
|
import { crawlCancelController } from "../../src/controllers/v0/crawl-cancel";
|
||||||
import { keyAuthController } from "../../src/controllers/keyAuth";
|
import { keyAuthController } from "../../src/controllers/v0/keyAuth";
|
||||||
|
import { livenessController } from "../controllers/v0/liveness";
|
||||||
|
import { readinessController } from "../controllers/v0/readiness";
|
||||||
|
|
||||||
export const v0Router = express.Router();
|
export const v0Router = express.Router();
|
||||||
|
|
||||||
|
|
@ -23,3 +25,6 @@ v0Router.get("/v0/keyAuth", keyAuthController);
|
||||||
// Search routes
|
// Search routes
|
||||||
v0Router.post("/v0/search", searchController);
|
v0Router.post("/v0/search", searchController);
|
||||||
|
|
||||||
|
// Health/Probe routes
|
||||||
|
v0Router.get("/v0/health/liveness", livenessController);
|
||||||
|
v0Router.get("/v0/health/readiness", readinessController);
|
||||||
|
|
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user